 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Selective Context for Interaction Recognition
Oct 17, 2020
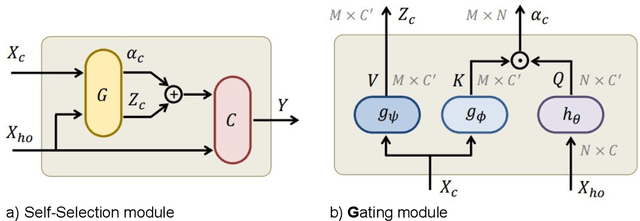

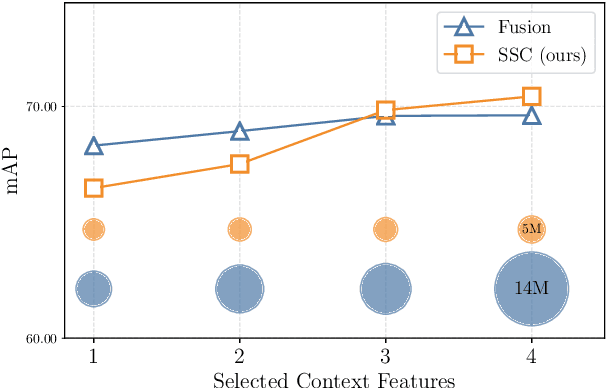
Human-object interaction recognition aims for identifying the relationship between a human subject and an object. Researchers incorporate global scene context into the early layers of deep Convolutional Neural Networks as a solution. They report a significant increase in the performance since generally interactions are correlated with the scene (\ie riding bicycle on the city street). However, this approach leads to the following problems. It increases the network size in the early layers, therefore not efficient. It leads to noisy filter responses when the scene is irrelevant, therefore not accurate. It only leverages scene context whereas human-object interactions offer a multitude of contexts, therefore incomplete. To circumvent these issues, in this work, we propose Self-Selective Context (SSC). SSC operates on the joint appearance of human-objects and context to bring the most discriminative context(s) into play for recognition. We devise novel contextual features that model the locality of human-object interactions and show that SSC can seamlessly integrate with the State-of-the-art interaction recognition models. Our experiments show that SSC leads to an important increase in interaction recognition performance, while using much fewer parameters.
TimeGate: Conditional Gating of Segments in Long-range Activities
Apr 03, 2020
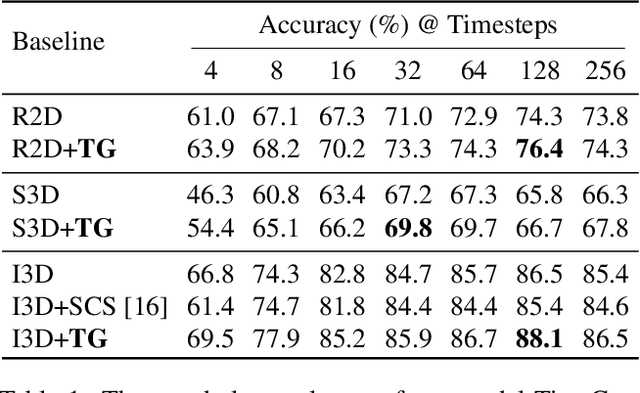
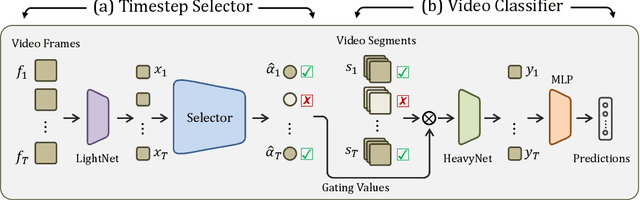
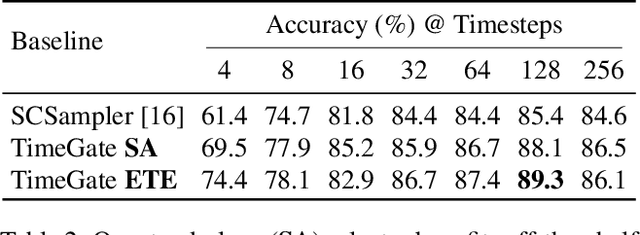
When recognizing a long-range activity, exploring the entire video is exhaustive and computationally expensive, as it can span up to a few minutes. Thus, it is of great importance to sample only the salient parts of the video. We propose TimeGate, along with a novel conditional gating module, for sampling the most representative segments from the long-range activity. TimeGate has two novelties that address the shortcomings of previous sampling methods, as SCSampler. First, it enables a differentiable sampling of segments. Thus, TimeGate can be fitted with modern CNNs and trained end-to-end as a single and unified model.Second, the sampling is conditioned on both the segments and their context. Consequently, TimeGate is better suited for long-range activities, where the importance of a segment heavily depends on the video context.TimeGate reduces the computation of existing CNNs on three benchmarks for long-range activities: Charades, Breakfast and MultiThumos. In particular, TimeGate reduces the computation of I3D by 50% while maintaining the classification accuracy.
PIC: Permutation Invariant Convolution for Recognizing Long-range Activities
Mar 18, 2020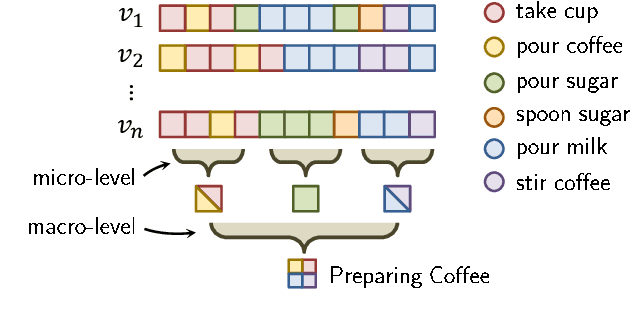
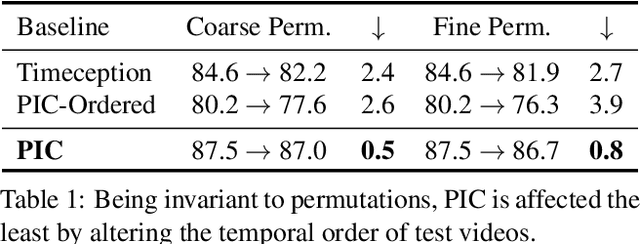
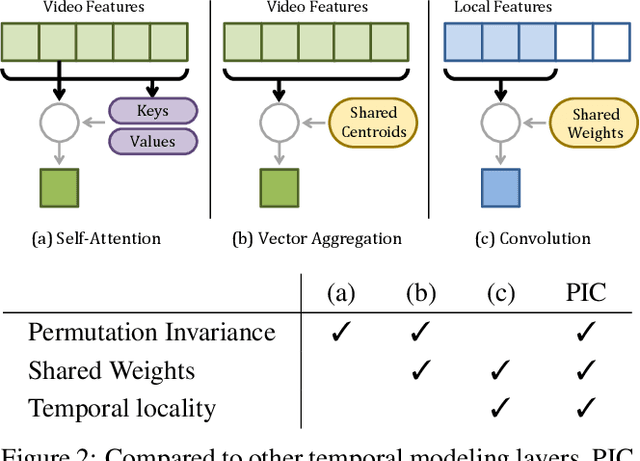
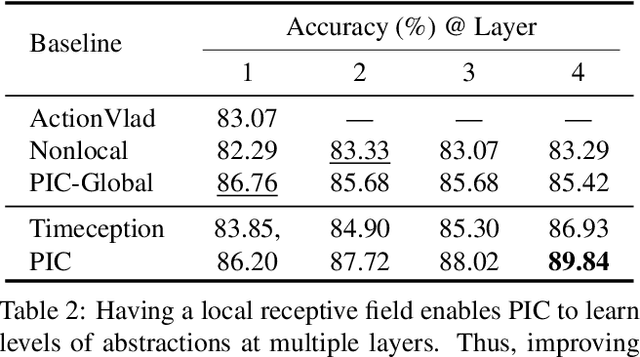
Neural operations as convolutions, self-attention, and vector aggregation are the go-to choices for recognizing short-range actions. However, they have three limitations in modeling long-range activities. This paper presents PIC, Permutation Invariant Convolution, a novel neural layer to model the temporal structure of long-range activities. It has three desirable properties. i. Unlike standard convolution, PIC is invariant to the temporal permutations of features within its receptive field, qualifying it to model the weak temporal structures. ii. Different from vector aggregation, PIC respects local connectivity, enabling it to learn long-range temporal abstractions using cascaded layers. iii. In contrast to self-attention, PIC uses shared weights, making it more capable of detecting the most discriminant visual evidence across long and noisy videos. We study the three properties of PIC and demonstrate its effectiveness in recognizing the long-range activities of Charades, Breakfast, and MultiThumos.
VideoGraph: Recognizing Minutes-Long Human Activities in Videos
May 13, 2019
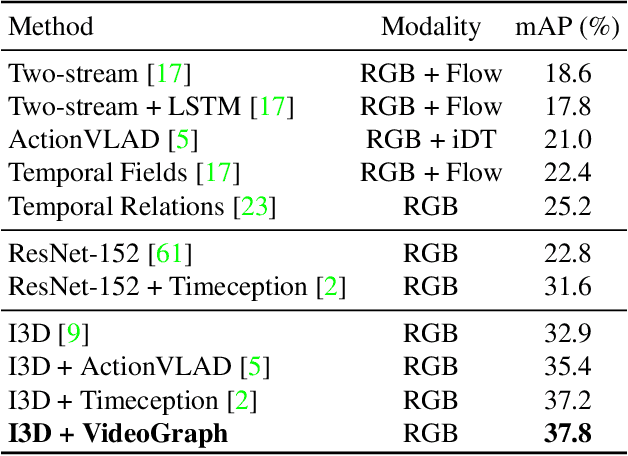
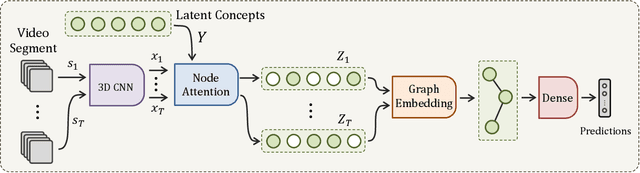
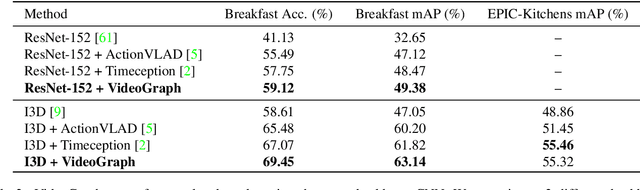
Many human activities take minutes to unfold. To represent them, related works opt for statistical pooling, which neglects the temporal structure. Others opt for convolutional methods, as CNN and Non-Local. While successful in learning temporal concepts, they are short of modeling minutes-long temporal dependencies. We propose VideoGraph, a method to achieve the best of two worlds: represent minutes-long human activities and learn their underlying temporal structure. VideoGraph learns a graph-based representation for human activities. The graph, its nodes and edges are learned entirely from video datasets, making VideoGraph applicable to problems without node-level annotation. The result is improvements over related works on benchmarks: Epic-Kitchen and Breakfast. Besides, we demonstrate that VideoGraph is able to learn the temporal structure of human activities in minutes-long videos.
Timeception for Complex Action Recognition
Dec 04, 2018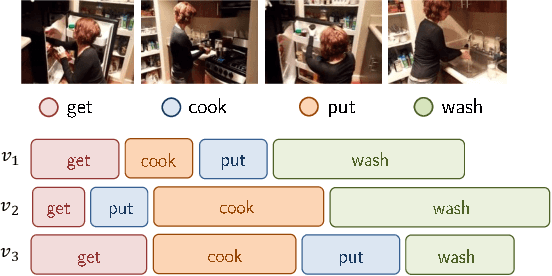
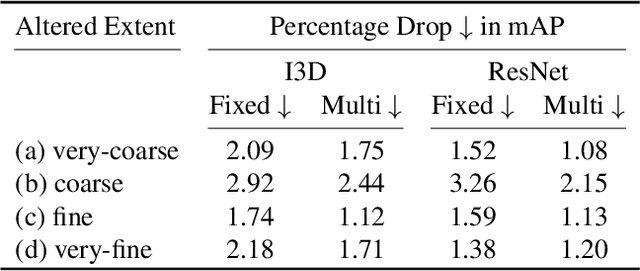
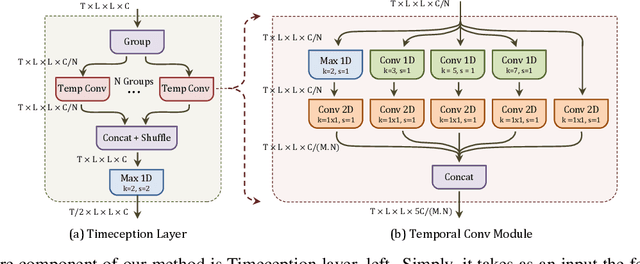
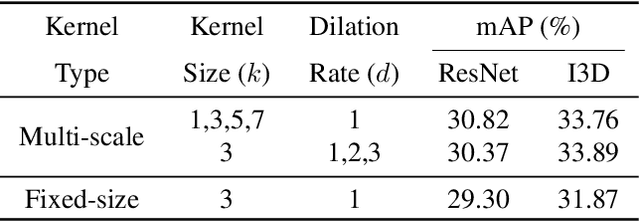
This paper focuses on the temporal aspect for recognizing human activities in videos; an important visual cue that has long been either disregarded or ill-used. We revisit the conventional definition of an activity and restrict it to "Complex Action": a set of one-actions with a weak temporal pattern that serves a specific purpose. Related works use spatiotemporal 3D convolutions with fixed kernel size, too rigid to capture the varieties in temporal extents of complex actions, and too short for long-range temporal modeling. In contrast, we use multi-scale temporal convolutions, and we reduce the complexity of 3D convolutions. The outcome is Timeception convolution layers, which reasons about minute-long temporal patterns, a factor of 8 longer than best related works. As a result, Timeception achieves impressive accuracy in recognizing human activities of Charades. Further, we conduct analysis to demonstrate that Timeception learns long-range temporal dependencies and tolerate temporal extents of complex actions.
Unified Embedding and Metric Learning for Zero-Exemplar Event Detection
May 05, 2017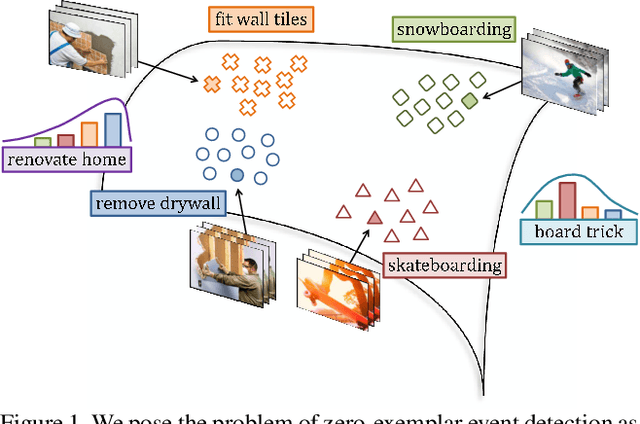

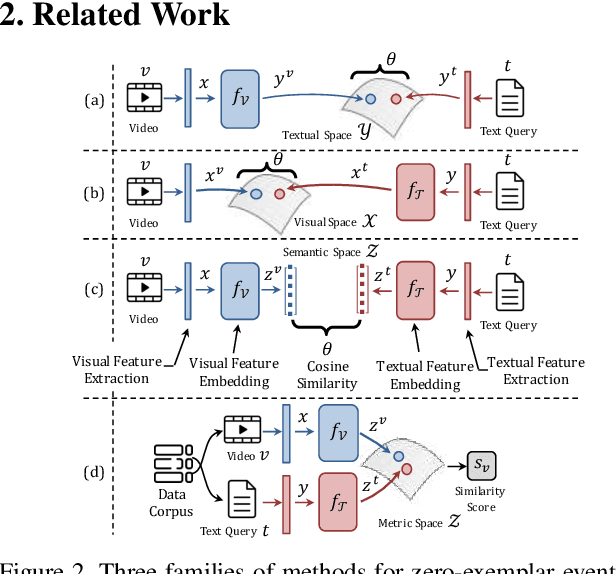

Event detection in unconstrained videos is conceived as a content-based video retrieval with two modalities: textual and visual. Given a text describing a novel event, the goal is to rank related videos accordingly. This task is zero-exemplar, no video examples are given to the novel event. Related works train a bank of concept detectors on external data sources. These detectors predict confidence scores for test videos, which are ranked and retrieved accordingly. In contrast, we learn a joint space in which the visual and textual representations are embedded. The space casts a novel event as a probability of pre-defined events. Also, it learns to measure the distance between an event and its related videos. Our model is trained end-to-end on publicly available EventNet. When applied to TRECVID Multimedia Event Detection dataset, it outperforms the state-of-the-art by a considerable margin.