 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUVGS: Reimagining Unstructured 3D Gaussian Splatting using UV Mapping
Feb 03, 20253D Gaussian Splatting (3DGS) has demonstrated superior quality in modeling 3D objects and scenes. However, generating 3DGS remains challenging due to their discrete, unstructured, and permutation-invariant nature. In this work, we present a simple yet effective method to overcome these challenges. We utilize spherical mapping to transform 3DGS into a structured 2D representation, termed UVGS. UVGS can be viewed as multi-channel images, with feature dimensions as a concatenation of Gaussian attributes such as position, scale, color, opacity, and rotation. We further find that these heterogeneous features can be compressed into a lower-dimensional (e.g., 3-channel) shared feature space using a carefully designed multi-branch network. The compressed UVGS can be treated as typical RGB images. Remarkably, we discover that typical VAEs trained with latent diffusion models can directly generalize to this new representation without additional training. Our novel representation makes it effortless to leverage foundational 2D models, such as diffusion models, to directly model 3DGS. Additionally, one can simply increase the 2D UV resolution to accommodate more Gaussians, making UVGS a scalable solution compared to typical 3D backbones. This approach immediately unlocks various novel generation applications of 3DGS by inherently utilizing the already developed superior 2D generation capabilities. In our experiments, we demonstrate various unconditional, conditional generation, and inpainting applications of 3DGS based on diffusion models, which were previously non-trivial.
Lung Diseases Image Segmentation using Faster R-CNNs
Sep 10, 2023Lung diseases are a leading cause of child mortality in the developing world, with India accounting for approximately half of global pneumonia deaths (370,000) in 2016. Timely diagnosis is crucial for reducing mortality rates. This paper introduces a low-density neural network structure to mitigate topological challenges in deep networks. The network incorporates parameters into a feature pyramid, enhancing data extraction and minimizing information loss. Soft Non-Maximal Suppression optimizes regional proposals generated by the Region Proposal Network. The study evaluates the model on chest X-ray images, computing a confusion matrix to determine accuracy, precision, sensitivity, and specificity. We analyze loss functions, highlighting their trends during training. The regional proposal loss and classification loss assess model performance during training and classification phases. This paper analysis lung disease detection and neural network structures.
Machine Learning to Estimate Gross Loss of Jewelry for Wax Patterns
Jan 07, 2023In mass manufacturing of jewellery, the gross loss is estimated before manufacturing to calculate the wax weight of the pattern that would be investment casted to make multiple identical pieces of jewellery. Machine learning is a technology that is a part of AI which helps create a model with decision-making capabilities based on a large set of user-defined data. In this paper, the authors found a way to use Machine Learning in the jewellery industry to estimate this crucial Gross Loss. Choosing a small data set of manufactured rings and via regression analysis, it was found out that there is a potential of reducing the error in estimation from +-2-3 to +-0.5 using ML Algorithms from historic data and attributes collected from the CAD file during the design phase itself. To evaluate the approach's viability, additional study must be undertaken with a larger data set.
Motion-Augmented Self-Training for Video Recognition at Smaller Scale
May 04, 2021
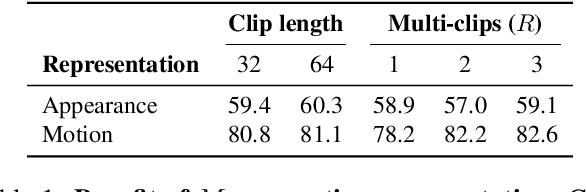


The goal of this paper is to self-train a 3D convolutional neural network on an unlabeled video collection for deployment on small-scale video collections. As smaller video datasets benefit more from motion than appearance, we strive to train our network using optical flow, but avoid its computation during inference. We propose the first motion-augmented self-training regime, we call MotionFit. We start with supervised training of a motion model on a small, and labeled, video collection. With the motion model we generate pseudo-labels for a large unlabeled video collection, which enables us to transfer knowledge by learning to predict these pseudo-labels with an appearance model. Moreover, we introduce a multi-clip loss as a simple yet efficient way to improve the quality of the pseudo-labeling, even without additional auxiliary tasks. We also take into consideration the temporal granularity of videos during self-training of the appearance model, which was missed in previous works. As a result we obtain a strong motion-augmented representation model suited for video downstream tasks like action recognition and clip retrieval. On small-scale video datasets, MotionFit outperforms alternatives for knowledge transfer by 5%-8%, video-only self-supervision by 1%-7% and semi-supervised learning by 9%-18% using the same amount of class labels.
TimeGate: Conditional Gating of Segments in Long-range Activities
Apr 03, 2020
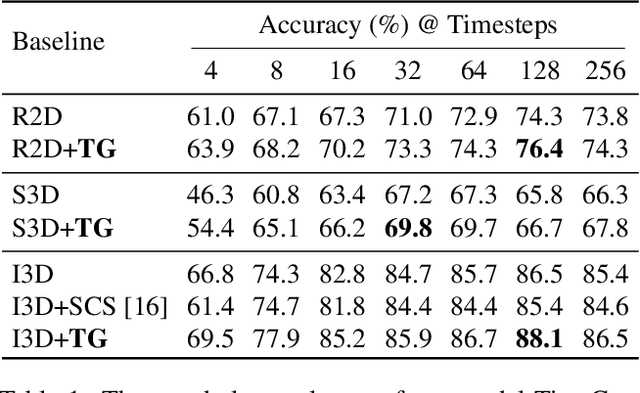
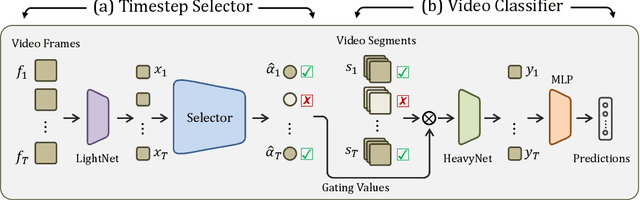
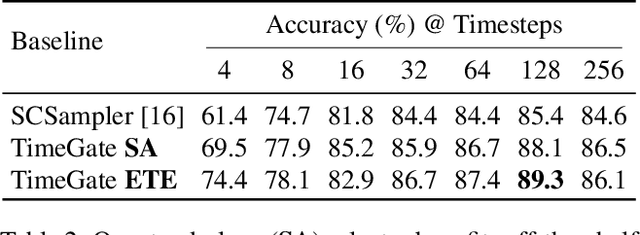
When recognizing a long-range activity, exploring the entire video is exhaustive and computationally expensive, as it can span up to a few minutes. Thus, it is of great importance to sample only the salient parts of the video. We propose TimeGate, along with a novel conditional gating module, for sampling the most representative segments from the long-range activity. TimeGate has two novelties that address the shortcomings of previous sampling methods, as SCSampler. First, it enables a differentiable sampling of segments. Thus, TimeGate can be fitted with modern CNNs and trained end-to-end as a single and unified model.Second, the sampling is conditioned on both the segments and their context. Consequently, TimeGate is better suited for long-range activities, where the importance of a segment heavily depends on the video context.TimeGate reduces the computation of existing CNNs on three benchmarks for long-range activities: Charades, Breakfast and MultiThumos. In particular, TimeGate reduces the computation of I3D by 50% while maintaining the classification accuracy.
Multi-Fidelity Recursive Behavior Prediction
Dec 18, 2018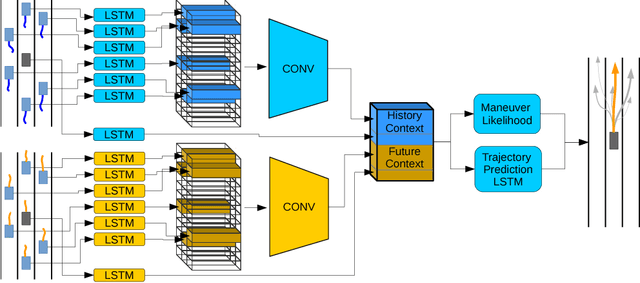
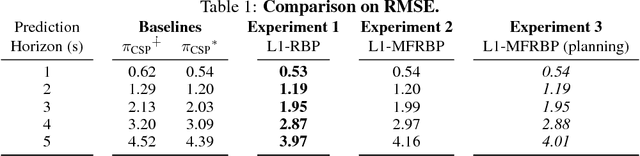
Predicting the behavior of surrounding vehicles is a critical problem in automated driving. We present a novel game theoretic behavior prediction model that achieves state of the art prediction accuracy by explicitly reasoning about possible future interaction between agents. We evaluate our approach on the NGSIM vehicle trajectory data set and demonstrate lower root mean square error than state-of-the-art methods.
Guess Where? Actor-Supervision for Spatiotemporal Action Localization
Apr 05, 2018
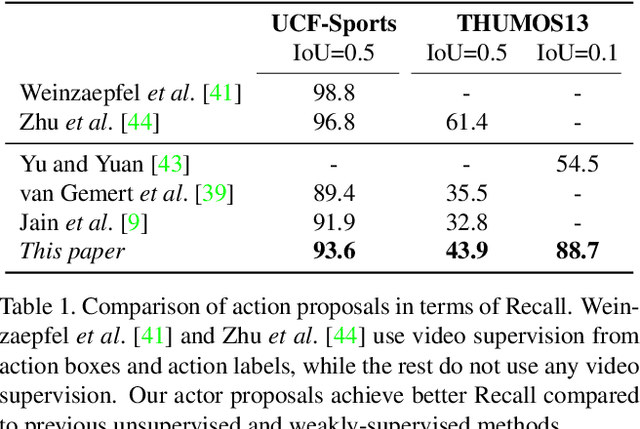
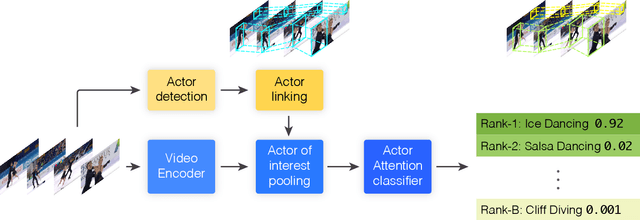

This paper addresses the problem of spatiotemporal localization of actions in videos. Compared to leading approaches, which all learn to localize based on carefully annotated boxes on training video frames, we adhere to a weakly-supervised solution that only requires a video class label. We introduce an actor-supervised architecture that exploits the inherent compositionality of actions in terms of actor transformations, to localize actions. We make two contributions. First, we propose actor proposals derived from a detector for human and non-human actors intended for images, which is linked over time by Siamese similarity matching to account for actor deformations. Second, we propose an actor-based attention mechanism that enables the localization of the actions from action class labels and actor proposals and is end-to-end trainable. Experiments on three human and non-human action datasets show actor supervision is state-of-the-art for weakly-supervised action localization and is even competitive to some fully-supervised alternatives.
Tubelets: Unsupervised action proposals from spatiotemporal super-voxels
Jul 07, 2016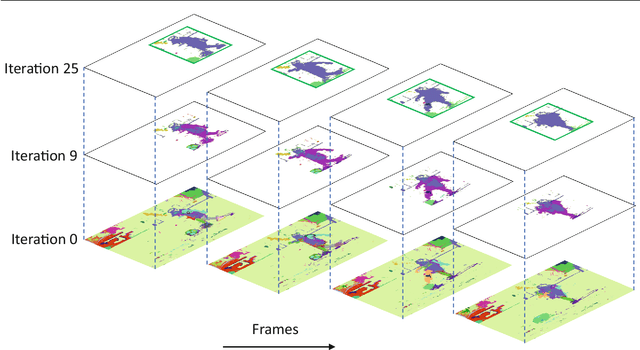
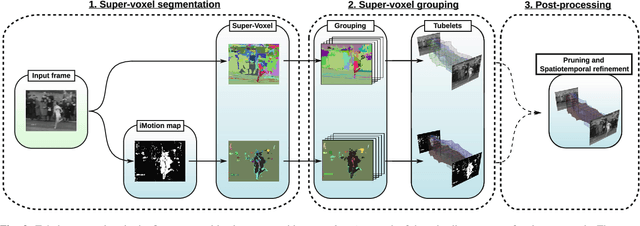
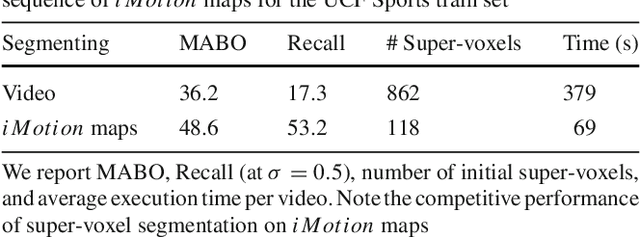

This paper considers the problem of localizing actions in videos as a sequences of bounding boxes. The objective is to generate action proposals that are likely to include the action of interest, ideally achieving high recall with few proposals. Our contributions are threefold. First, inspired by selective search for object proposals, we introduce an approach to generate action proposals from spatiotemporal super-voxels in an unsupervised manner, we call them Tubelets. Second, along with the static features from individual frames our approach advantageously exploits motion. We introduce independent motion evidence as a feature to characterize how the action deviates from the background and explicitly incorporate such motion information in various stages of the proposal generation. Finally, we introduce spatiotemporal refinement of Tubelets, for more precise localization of actions, and pruning to keep the number of Tubelets limited. We demonstrate the suitability of our approach by extensive experiments for action proposal quality and action localization on three public datasets: UCF Sports, MSR-II and UCF101. For action proposal quality, our unsupervised proposals beat all other existing approaches on the three datasets. For action localization, we show top performance on both the trimmed videos of UCF Sports and UCF101 as well as the untrimmed videos of MSR-II.
VideoLSTM Convolves, Attends and Flows for Action Recognition
Jul 06, 2016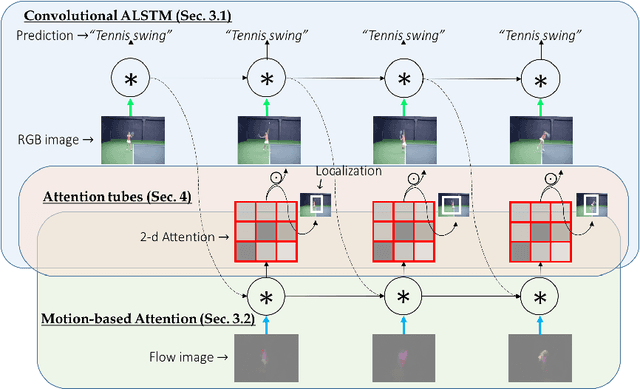
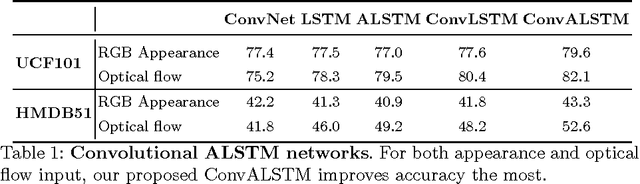
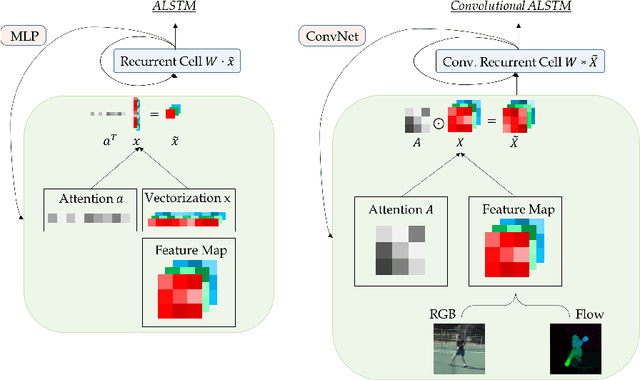

We present a new architecture for end-to-end sequence learning of actions in video, we call VideoLSTM. Rather than adapting the video to the peculiarities of established recurrent or convolutional architectures, we adapt the architecture to fit the requirements of the video medium. Starting from the soft-Attention LSTM, VideoLSTM makes three novel contributions. First, video has a spatial layout. To exploit the spatial correlation we hardwire convolutions in the soft-Attention LSTM architecture. Second, motion not only informs us about the action content, but also guides better the attention towards the relevant spatio-temporal locations. We introduce motion-based attention. And finally, we demonstrate how the attention from VideoLSTM can be used for action localization by relying on just the action class label. Experiments and comparisons on challenging datasets for action classification and localization support our claims.
Objects2action: Classifying and localizing actions without any video example
Oct 23, 2015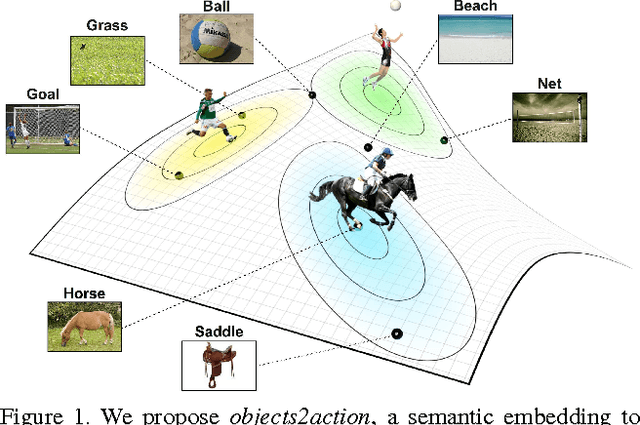
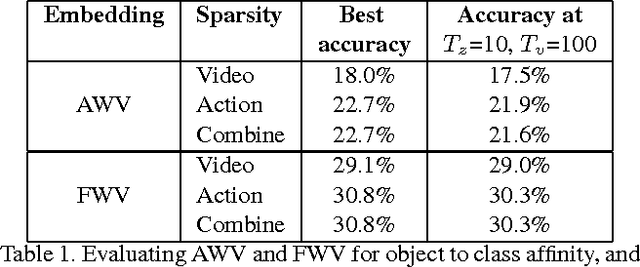
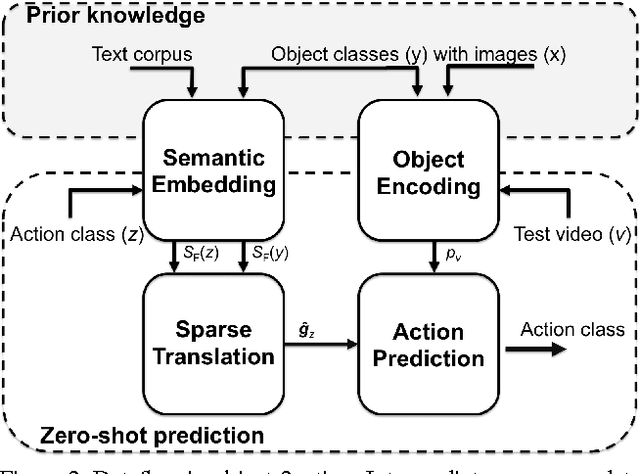
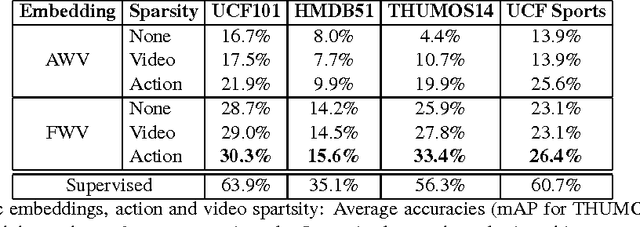
The goal of this paper is to recognize actions in video without the need for examples. Different from traditional zero-shot approaches we do not demand the design and specification of attribute classifiers and class-to-attribute mappings to allow for transfer from seen classes to unseen classes. Our key contribution is objects2action, a semantic word embedding that is spanned by a skip-gram model of thousands of object categories. Action labels are assigned to an object encoding of unseen video based on a convex combination of action and object affinities. Our semantic embedding has three main characteristics to accommodate for the specifics of actions. First, we propose a mechanism to exploit multiple-word descriptions of actions and objects. Second, we incorporate the automated selection of the most responsive objects per action. And finally, we demonstrate how to extend our zero-shot approach to the spatio-temporal localization of actions in video. Experiments on four action datasets demonstrate the potential of our approach.