 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuPPet: Multi-person 2D-to-3D Pose Lifting
Apr 08, 2026Multi-person social interactions are inherently built on coherence and relationships among all individuals within the group, making multi-person localization and body pose estimation essential to understanding these social dynamics. One promising approach is 2D-to-3D pose lifting which provides a 3D human pose consisting of rich spatial details by building on the significant advances in 2D pose estimation. However, the existing 2D-to-3D pose lifting methods often neglect inter-person relationships or cannot handle varying group sizes, limiting their effectiveness in multi-person settings. We propose MuPPet, a novel multi-person 2D-to-3D pose lifting framework that explicitly models inter-person correlations. To leverage these inter-person dependencies, our approach introduces Person Encoding to structure individual representations, Permutation Augmentation to enhance training diversity, and Dynamic Multi-Person Attention to adaptively model correlations between individuals. Extensive experiments on group interaction datasets demonstrate MuPPet significantly outperforms state-of-the-art single- and multi-person 2D-to-3D pose lifting methods, and improves robustness in occlusion scenarios. Our findings highlight the importance of modeling inter-person correlations, paving the way for accurate and socially-aware 3D pose estimation. Our code is available at: https://github.com/Thomas-Markhorst/MuPPet
Rare-Aware Autoencoding: Reconstructing Spatially Imbalanced Data
Apr 02, 2026Autoencoders can be challenged by spatially non-uniform sampling of image content. This is common in medical imaging, biology, and physics, where informative patterns occur rarely at specific image coordinates, as background dominates these locations in most samples, biasing reconstructions toward the majority appearance. In practice, autoencoders are biased toward dominant patterns resulting in the loss of fine-grained detail and causing blurred reconstructions for rare spatial inputs especially under spatial data imbalance. We address spatial imbalance by two complementary components: (i) self-entropy-based loss that upweights statistically uncommon spatial locations and (ii) Sample Propagation, a replay mechanism that selectively re-exposes the model to hard to reconstruct samples across batches during training. We benchmark existing data balancing strategies, originally developed for supervised classification, in the unsupervised reconstruction setting. Drawing on the limitations of these approaches, our method specifically targets spatial imbalance by encouraging models to focus on statistically rare locations, improving reconstruction consistency compared to existing baselines. We validate in a simulated dataset with controlled spatial imbalance conditions, and in three, uncontrolled, diverse real-world datasets spanning physical, biological, and astronomical domains. Our approach outperforms baselines on various reconstruction metrics, particularly under spatial imbalance distributions. These results highlight the importance of data representation in a batch and emphasize rare samples in unsupervised image reconstruction. We will make all code and related data available.
Assessing Situational and Spatial Awareness of VLMs with Synthetically Generated Video
Jan 22, 2026Spatial reasoning in vision language models (VLMs) remains fragile when semantics hinge on subtle temporal or geometric cues. We introduce a synthetic benchmark that probes two complementary skills: situational awareness (recognizing whether an interaction is harmful or benign) and spatial awareness (tracking who does what to whom, and reasoning about relative positions and motion). Through minimal video pairs, we test three challenges: distinguishing violence from benign activity, binding assailant roles across viewpoints, and judging fine-grained trajectory alignment. While we evaluate recent VLMs in a training-free setting, the benchmark is applicable to any video classification model. Results show performance only slightly above chance across tasks. A simple aid, stable color cues, partly reduces assailant role confusions but does not resolve the underlying weakness. By releasing data and code, we aim to provide reproducible diagnostics and seed exploration of lightweight spatial priors to complement large-scale pretraining.
LayoutGKN: Graph Similarity Learning of Floor Plans
Sep 03, 2025Floor plans depict building layouts and are often represented as graphs to capture the underlying spatial relationships. Comparison of these graphs is critical for applications like search, clustering, and data visualization. The most successful methods to compare graphs \ie, graph matching networks, rely on costly intermediate cross-graph node-level interactions, therefore being slow in inference time. We introduce \textbf{LayoutGKN}, a more efficient approach that postpones the cross-graph node-level interactions to the end of the joint embedding architecture. We do so by using a differentiable graph kernel as a distance function on the final learned node-level embeddings. We show that LayoutGKN computes similarity comparably or better than graph matching networks while significantly increasing the speed. \href{https://github.com/caspervanengelenburg/LayoutGKN}{Code and data} are open.
Data-Efficient Challenges in Visual Inductive Priors: A Retrospective
Jun 10, 2025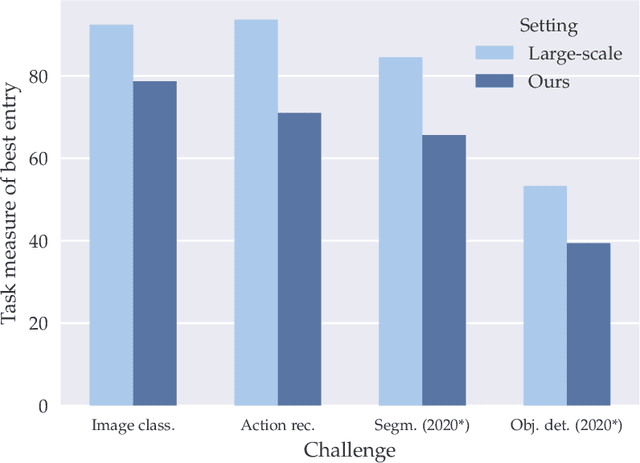
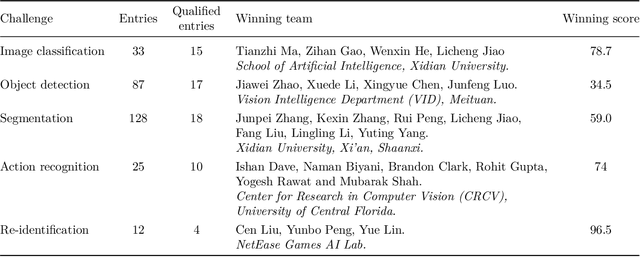

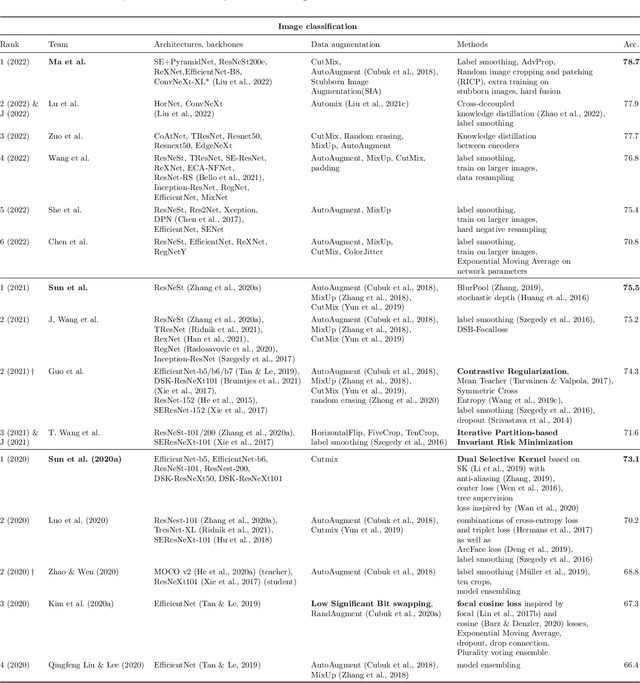
Deep Learning requires large amounts of data to train models that work well. In data-deficient settings, performance can be degraded. We investigate which Deep Learning methods benefit training models in a data-deficient setting, by organizing the "VIPriors: Visual Inductive Priors for Data-Efficient Deep Learning" workshop series, featuring four editions of data-impaired challenges. These challenges address the problem of training deep learning models for computer vision tasks with limited data. Participants are limited to training models from scratch using a low number of training samples and are not allowed to use any form of transfer learning. We aim to stimulate the development of novel approaches that incorporate prior knowledge to improve the data efficiency of deep learning models. Successful challenge entries make use of large model ensembles that mix Transformers and CNNs, as well as heavy data augmentation. Novel prior knowledge-based methods contribute to success in some entries.
Making Every Event Count: Balancing Data Efficiency and Accuracy in Event Camera Subsampling
May 27, 2025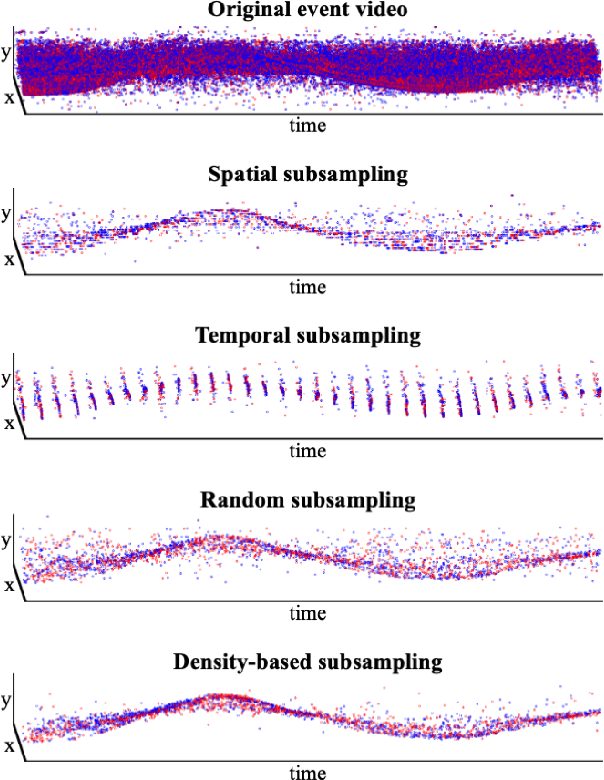
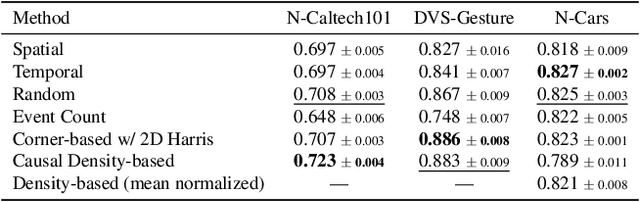
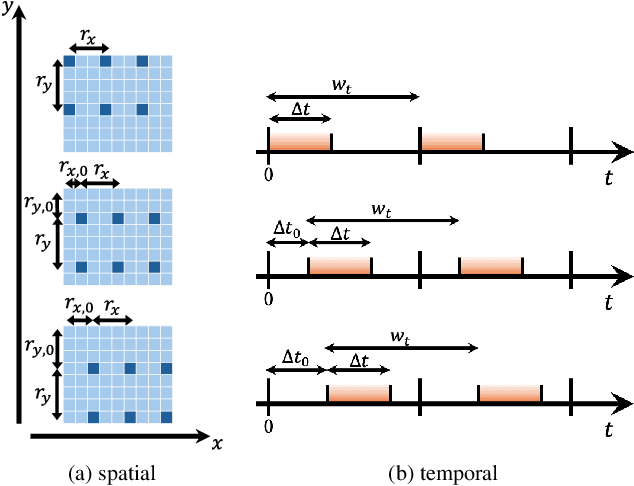
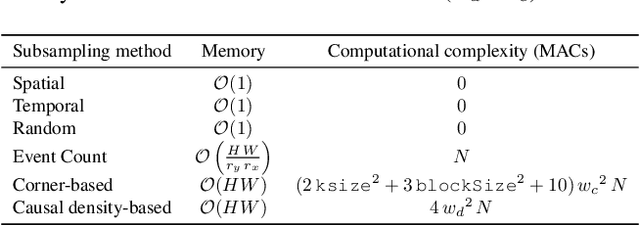
Event cameras offer high temporal resolution and power efficiency, making them well-suited for edge AI applications. However, their high event rates present challenges for data transmission and processing. Subsampling methods provide a practical solution, but their effect on downstream visual tasks remains underexplored. In this work, we systematically evaluate six hardware-friendly subsampling methods using convolutional neural networks for event video classification on various benchmark datasets. We hypothesize that events from high-density regions carry more task-relevant information and are therefore better suited for subsampling. To test this, we introduce a simple causal density-based subsampling method, demonstrating improved classification accuracy in sparse regimes. Our analysis further highlights key factors affecting subsampling performance, including sensitivity to hyperparameters and failure cases in scenarios with large event count variance. These findings provide insights for utilization of hardware-efficient subsampling strategies that balance data efficiency and task accuracy. The code for this paper will be released at: https://github.com/hesamaraghi/event-camera-subsampling-methods.
Learning to Adapt to Position Bias in Vision Transformer Classifiers
May 19, 2025How discriminative position information is for image classification depends on the data. On the one hand, the camera position is arbitrary and objects can appear anywhere in the image, arguing for translation invariance. At the same time, position information is key for exploiting capture/center bias, and scene layout, e.g.: the sky is up. We show that position bias, the level to which a dataset is more easily solved when positional information on input features is used, plays a crucial role in the performance of Vision Transformers image classifiers. To investigate, we propose Position-SHAP, a direct measure of position bias by extending SHAP to work with position embeddings. We show various levels of position bias in different datasets, and find that the optimal choice of position embedding depends on the position bias apparent in the dataset. We therefore propose Auto-PE, a single-parameter position embedding extension, which allows the position embedding to modulate its norm, enabling the unlearning of position information. Auto-PE combines with existing PEs to match or improve accuracy on classification datasets.
ARC: Anchored Representation Clouds for High-Resolution INR Classification
Mar 19, 2025Implicit neural representations (INRs) encode signals in neural network weights as a memory-efficient representation, decoupling sampling resolution from the associated resource costs. Current INR image classification methods are demonstrated on low-resolution data and are sensitive to image-space transformations. We attribute these issues to the global, fully-connected MLP neural network architecture encoding of current INRs, which lack mechanisms for local representation: MLPs are sensitive to absolute image location and struggle with high-frequency details. We propose ARC: Anchored Representation Clouds, a novel INR architecture that explicitly anchors latent vectors locally in image-space. By introducing spatial structure to the latent vectors, ARC captures local image data which in our testing leads to state-of-the-art implicit image classification of both low- and high-resolution images and increased robustness against image-space translation. Code can be found at https://github.com/JLuij/anchored_representation_clouds.
Local Attention Transformers for High-Detail Optical Flow Upsampling
Dec 09, 2024Most recent works on optical flow use convex upsampling as the last step to obtain high-resolution flow. In this work, we show and discuss several issues and limitations of this currently widely adopted convex upsampling approach. We propose a series of changes, in an attempt to resolve current issues. First, we propose to decouple the weights for the final convex upsampler, making it easier to find the correct convex combination. For the same reason, we also provide extra contextual features to the convex upsampler. Then, we increase the convex mask size by using an attention-based alternative convex upsampler; Transformers for Convex Upsampling. This upsampler is based on the observation that convex upsampling can be reformulated as attention, and we propose to use local attention masks as a drop-in replacement for convex masks to increase the mask size. We provide empirical evidence that a larger mask size increases the likelihood of the existence of the convex combination. Lastly, we propose an alternative training scheme to remove bilinear interpolation artifacts from the model output. Our proposed ideas could theoretically be applied to almost every current state-of-the-art optical flow architecture. On the FlyingChairs + FlyingThings3D training setting we reduce the Sintel Clean training end-point-error of RAFT from 1.42 to 1.26, GMA from 1.31 to 1.18, and that of FlowFormer from 0.94 to 0.90, by solely adapting the convex upsampler.
Learning Physics From Video: Unsupervised Physical Parameter Estimation for Continuous Dynamical Systems
Oct 02, 2024



Extracting physical dynamical system parameters from videos is of great interest to applications in natural science and technology. The state-of-the-art in automatic parameter estimation from video is addressed by training supervised deep networks on large datasets. Such datasets require labels, which are difficult to acquire. While some unsupervised techniques -- which depend on frame prediction -- exist, they suffer from long training times, instability under different initializations, and are limited to hand-picked motion problems. In this work, we propose a method to estimate the physical parameters of any known, continuous governing equation from single videos; our solution is suitable for different dynamical systems beyond motion and is robust to initialization compared to previous approaches. Moreover, we remove the need for frame prediction by implementing a KL-divergence-based loss function in the latent space, which avoids convergence to trivial solutions and reduces model size and compute.