 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Object Detector Bounding Boxes with Human Preference
Aug 20, 2024Previous work shows that humans tend to prefer large bounding boxes over small bounding boxes with the same IoU. However, we show here that commonly used object detectors predict large and small boxes equally often. In this work, we investigate how to align automatically detected object boxes with human preference and study whether this improves human quality perception. We evaluate the performance of three commonly used object detectors through a user study (N = 123). We find that humans prefer object detections that are upscaled with factors of 1.5 or 2, even if the corresponding AP is close to 0. Motivated by this result, we propose an asymmetric bounding box regression loss that encourages large over small predicted bounding boxes. Our evaluation study shows that object detectors fine-tuned with the asymmetric loss are better aligned with human preference and are preferred over fixed scaling factors. A qualitative evaluation shows that human preference might be influenced by some object characteristics, like object shape.
Video BagNet: short temporal receptive fields increase robustness in long-term action recognition
Aug 22, 2023Previous work on long-term video action recognition relies on deep 3D-convolutional models that have a large temporal receptive field (RF). We argue that these models are not always the best choice for temporal modeling in videos. A large temporal receptive field allows the model to encode the exact sub-action order of a video, which causes a performance decrease when testing videos have a different sub-action order. In this work, we investigate whether we can improve the model robustness to the sub-action order by shrinking the temporal receptive field of action recognition models. For this, we design Video BagNet, a variant of the 3D ResNet-50 model with the temporal receptive field size limited to 1, 9, 17 or 33 frames. We analyze Video BagNet on synthetic and real-world video datasets and experimentally compare models with varying temporal receptive fields. We find that short receptive fields are robust to sub-action order changes, while larger temporal receptive fields are sensitive to the sub-action order.
Are current long-term video understanding datasets long-term?
Aug 22, 2023Many real-world applications, from sport analysis to surveillance, benefit from automatic long-term action recognition. In the current deep learning paradigm for automatic action recognition, it is imperative that models are trained and tested on datasets and tasks that evaluate if such models actually learn and reason over long-term information. In this work, we propose a method to evaluate how suitable a video dataset is to evaluate models for long-term action recognition. To this end, we define a long-term action as excluding all the videos that can be correctly recognized using solely short-term information. We test this definition on existing long-term classification tasks on three popular real-world datasets, namely Breakfast, CrossTask and LVU, to determine if these datasets are truly evaluating long-term recognition. Our study reveals that these datasets can be effectively solved using shortcuts based on short-term information. Following this finding, we encourage long-term action recognition researchers to make use of datasets that need long-term information to be solved.
The Functional Neural Process
Jun 19, 2019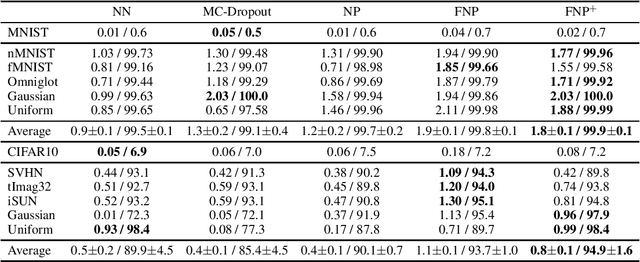
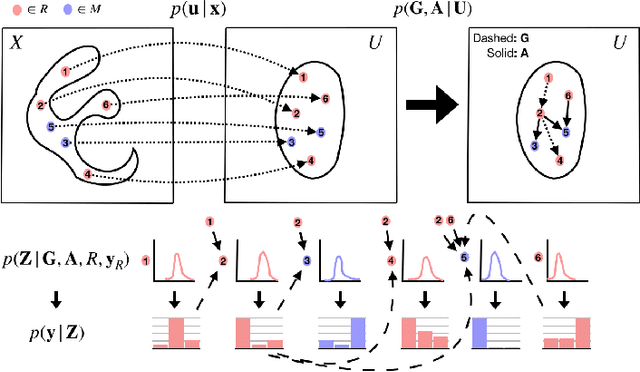
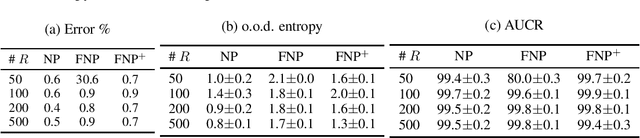

We present a new family of exchangeable stochastic processes, the Functional Neural Processes (FNPs). FNPs model distributions over functions by learning a graph of dependencies on top of latent representations of the points in the given dataset. In doing so, they define a Bayesian model without explicitly positing a prior distribution over latent global parameters; they instead adopt priors over the relational structure of the given dataset, a task that is much simpler. We show how we can learn such models from data, demonstrate that they are scalable to large datasets through mini-batch optimization and describe how we can make predictions for new points via their posterior predictive distribution. We experimentally evaluate FNPs on the tasks of toy regression and image classification and show that, when compared to baselines that employ global latent parameters, they offer both competitive predictions as well as more robust uncertainty estimates.