 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Safe LLM Systems via Soft Prompts for On Device Settings
Jun 08, 2026Deploying safe large language models (LLMs) on resource-constrained edge devices presents a critical challenge: while dual-model systems combining LLMs with guard models provide effective safety guarantees, their substantial memory and computational demands make them prohibitively expensive for on-device deployment. This paper presents a comprehensive study of parameter-efficient safety alignment methods for resource-constrained settings. Through systematic evaluation across multiple LLM architectures, training objectives, and parameter-efficient fine-tuning approaches, we identify that soft prompts combined with distillation-based training consistently outperform alternative methods. We introduce distillation frameworks based on total variation and KL divergence that effectively transfer safety behaviors from guard models into learned soft prompts. Our evaluations on various benchmarks demonstrate that this combination achieves superior safety-usefulness trade-offs compared to LoRA adapters, steering vectors, and direct optimization methods, while requiring minimal additional memory and compute at inference time. These findings establish soft prompt distillation as the preferred approach for safety alignment in on-device LLM deployment.
* Accepted to UAI 2026
On Adaptivity in Zeroth-Order Optimization
May 05, 2026We investigate the effectiveness of adaptive zeroth-order (ZO) optimization for memory-constrained fine-tuning of large language models (LLMs). Contrary to prior claims, we show that adaptive ZO methods such as ZO-Adam offer no convergence advantage over well-tuned ZO-SGD, while incurring significant memory overhead. Our analysis reveals that in high dimensions, ZO gradients lack coordinate-wise heterogeneity, rendering adaptive mechanisms memory inefficient. Leveraging this insight, we propose MEAZO, a memory-efficient adaptive ZO optimizer that tracks only a single scalar for global step size adaptation. We support our method with theoretical convergence guarantees under standard assumptions. Experiments across multiple LLM families and tasks demonstrate that MEAZO matches ZO-Adam's performance with the memory footprint of ZO-SGD. Additional experiments on synthetic quadratic problems and LLM fine-tuning further demonstrate MEAZO's enhanced robustness to step size choices, particularly in grouped or block-structured optimization settings.
Search or Accelerate: Confidence-Switched Position Beam Search for Diffusion Language Models
Feb 11, 2026Diffusion Language Models (DLMs) generate text by iteratively denoising a masked sequence, repeatedly deciding which positions to commit at each step. Standard decoding follows a greedy rule: unmask the most confident positions, yet this local choice can lock the model into a suboptimal unmasking order, especially on reasoning-heavy prompts. We present SOAR, a training-free decoding algorithm that adapts its behavior to the model's uncertainty. When confidence is low, SOAR briefly widens the search over alternative unmasking decisions to avoid premature commitments; when confidence is high, it collapses the search and decodes many positions in parallel to reduce the number of denoising iterations. Across mathematical reasoning and code generation benchmarks (GSM8K, MBPP, HumanEval) on Dream-7B and LLaDA-8B, SOAR improves generation quality while maintaining competitive inference speed, offering a practical way to balance quality and efficiency in DLM decoding.
Private PoEtry: Private In-Context Learning via Product of Experts
Feb 04, 2026In-context learning (ICL) enables Large Language Models (LLMs) to adapt to new tasks with only a small set of examples at inference time, thereby avoiding task-specific fine-tuning. However, in-context examples may contain privacy-sensitive information that should not be revealed through model outputs. Existing differential privacy (DP) approaches to ICL are either computationally expensive or rely on heuristics with limited effectiveness, including context oversampling, synthetic data generation, or unnecessary thresholding. We reformulate private ICL through the lens of a Product-of-Experts model. This gives a theoretically grounded framework, and the algorithm can be trivially parallelized. We evaluate our method across five datasets in text classification, math, and vision-language. We find that our method improves accuracy by more than 30 percentage points on average compared to prior DP-ICL methods, while maintaining strong privacy guarantees.
Guarding the Meaning: Self-Supervised Training for Semantic Robustness in Guard Models
Nov 06, 2025
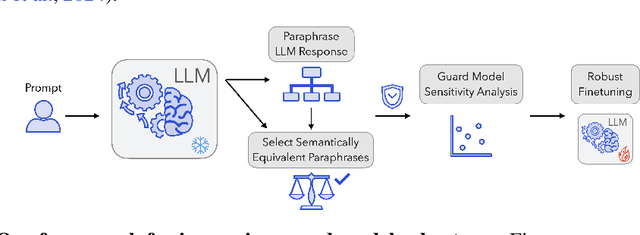
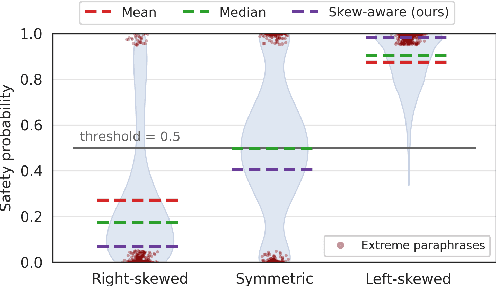
Guard models are a critical component of LLM safety, but their sensitivity to superficial linguistic variations remains a key vulnerability. We show that even meaning-preserving paraphrases can cause large fluctuations in safety scores, revealing a lack of semantic grounding. To address this, we introduce a practical, self-supervised framework for improving the semantic robustness of guard models. Our method leverages paraphrase sets to enforce prediction consistency using a novel, skew-aware aggregation strategy for robust target computation. Notably, we find that standard aggregation methods like mean and median can degrade safety, underscoring the need for skew-aware alternatives. We analyze six open-source guard models and show that our approach reduces semantic variability across paraphrases by ~58%, improves benchmark accuracy by ~2.5% on average, and generalizes to unseen stylistic variations. Intriguingly, we discover a bidirectional relationship between model calibration and consistency: our robustness training improves calibration by up to 40%, revealing a fundamental connection between these properties. These results highlight the value of treating semantic consistency as a first-class training objective and provide a scalable recipe for building more reliable guard models.
Fundamental bounds on efficiency-confidence trade-off for transductive conformal prediction
Sep 04, 2025Transductive conformal prediction addresses the simultaneous prediction for multiple data points. Given a desired confidence level, the objective is to construct a prediction set that includes the true outcomes with the prescribed confidence. We demonstrate a fundamental trade-off between confidence and efficiency in transductive methods, where efficiency is measured by the size of the prediction sets. Specifically, we derive a strict finite-sample bound showing that any non-trivial confidence level leads to exponential growth in prediction set size for data with inherent uncertainty. The exponent scales linearly with the number of samples and is proportional to the conditional entropy of the data. Additionally, the bound includes a second-order term, dispersion, defined as the variance of the log conditional probability distribution. We show that this bound is achievable in an idealized setting. Finally, we examine a special case of transductive prediction where all test data points share the same label. We show that this scenario reduces to the hypothesis testing problem with empirically observed statistics and provide an asymptotically optimal confidence predictor, along with an analysis of the error exponent.
Approximating Full Conformal Prediction for Neural Network Regression with Gauss-Newton Influence
Jul 27, 2025Uncertainty quantification is an important prerequisite for the deployment of deep learning models in safety-critical areas. Yet, this hinges on the uncertainty estimates being useful to the extent the prediction intervals are well-calibrated and sharp. In the absence of inherent uncertainty estimates (e.g. pretrained models predicting only point estimates), popular approaches that operate post-hoc include Laplace's method and split conformal prediction (split-CP). However, Laplace's method can be miscalibrated when the model is misspecified and split-CP requires sample splitting, and thus comes at the expense of statistical efficiency. In this work, we construct prediction intervals for neural network regressors post-hoc without held-out data. This is achieved by approximating the full conformal prediction method (full-CP). Whilst full-CP nominally requires retraining the model for every test point and candidate label, we propose to train just once and locally perturb model parameters using Gauss-Newton influence to approximate the effect of retraining. Coupled with linearization of the network, we express the absolute residual nonconformity score as a piecewise linear function of the candidate label allowing for an efficient procedure that avoids the exhaustive search over the output space. On standard regression benchmarks and bounding box localization, we show the resulting prediction intervals are locally-adaptive and often tighter than those of split-CP.
On Sampling Strategies for Spectral Model Sharding
Oct 31, 2024
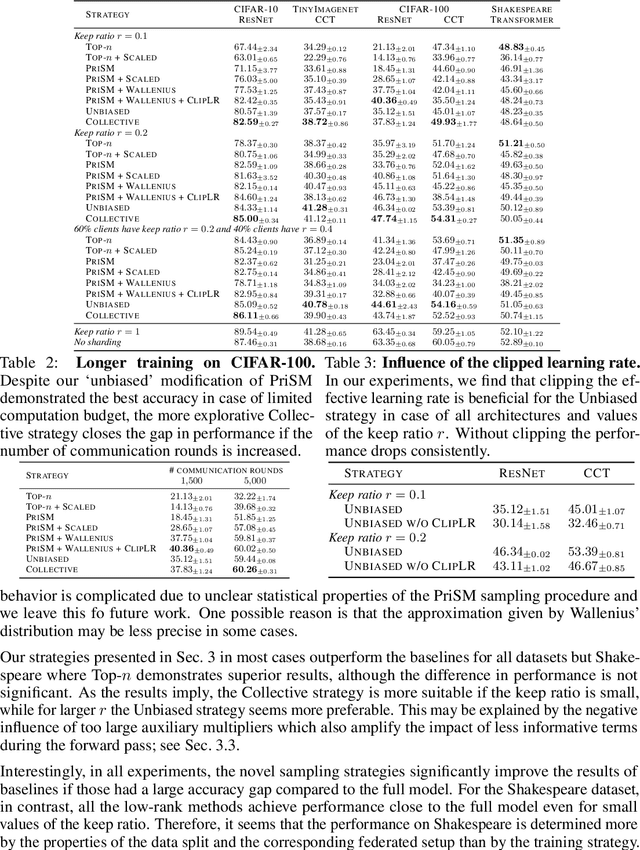
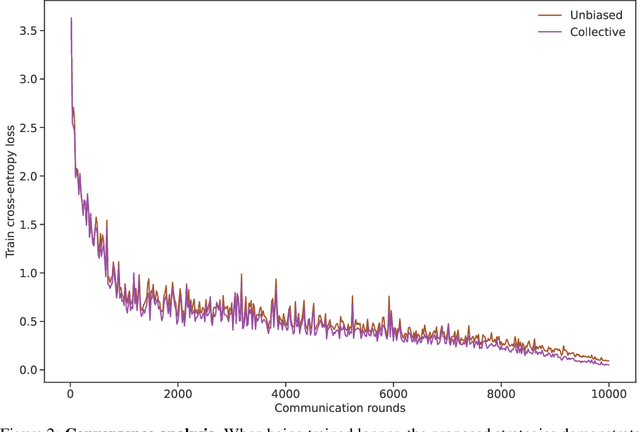
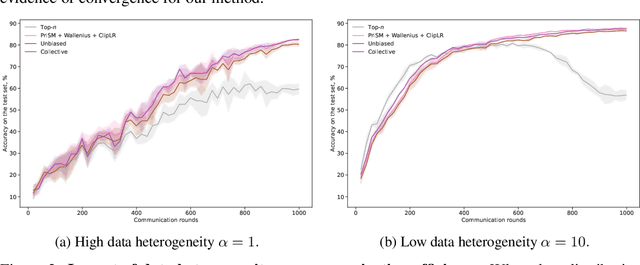
The problem of heterogeneous clients in federated learning has recently drawn a lot of attention. Spectral model sharding, i.e., partitioning the model parameters into low-rank matrices based on the singular value decomposition, has been one of the proposed solutions for more efficient on-device training in such settings. In this work, we present two sampling strategies for such sharding, obtained as solutions to specific optimization problems. The first produces unbiased estimators of the original weights, while the second aims to minimize the squared approximation error. We discuss how both of these estimators can be incorporated in the federated learning loop and practical considerations that arise during local training. Empirically, we demonstrate that both of these methods can lead to improved performance on various commonly used datasets.
Multi-Draft Speculative Sampling: Canonical Architectures and Theoretical Limits
Oct 23, 2024We consider multi-draft speculative sampling, where the proposal sequences are sampled independently from different draft models. At each step, a token-level draft selection scheme takes a list of valid tokens as input and produces an output token whose distribution matches that of the target model. Previous works have demonstrated that the optimal scheme (which maximizes the probability of accepting one of the input tokens) can be cast as a solution to a linear program. In this work we show that the optimal scheme can be decomposed into a two-step solution: in the first step an importance sampling (IS) type scheme is used to select one intermediate token; in the second step (single-draft) speculative sampling is applied to generate the output token. For the case of two identical draft models we further 1) establish a necessary and sufficient condition on the distributions of the target and draft models for the acceptance probability to equal one and 2) provide an explicit expression for the optimal acceptance probability. Our theoretical analysis also motives a new class of token-level selection scheme based on weighted importance sampling. Our experimental results demonstrate consistent improvements in the achievable block efficiency and token rates over baseline schemes in a number of scenarios.
Variational Learning ISTA
Jul 09, 2024Compressed sensing combines the power of convex optimization techniques with a sparsity-inducing prior on the signal space to solve an underdetermined system of equations. For many problems, the sparsifying dictionary is not directly given, nor its existence can be assumed. Besides, the sensing matrix can change across different scenarios. Addressing these issues requires solving a sparse representation learning problem, namely dictionary learning, taking into account the epistemic uncertainty of the learned dictionaries and, finally, jointly learning sparse representations and reconstructions under varying sensing matrix conditions. We address both concerns by proposing a variant of the LISTA architecture. First, we introduce Augmented Dictionary Learning ISTA (A-DLISTA), which incorporates an augmentation module to adapt parameters to the current measurement setup. Then, we propose to learn a distribution over dictionaries via a variational approach, dubbed Variational Learning ISTA (VLISTA). VLISTA exploits A-DLISTA as the likelihood model and approximates a posterior distribution over the dictionaries as part of an unfolded LISTA-based recovery algorithm. As a result, VLISTA provides a probabilistic way to jointly learn the dictionary distribution and the reconstruction algorithm with varying sensing matrices. We provide theoretical and experimental support for our architecture and show that our model learns calibrated uncertainties.