 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterroGate: Learning to Share, Specialize, and Prune Representations for Multi-task Learning
Paper and Code
Feb 26, 2024
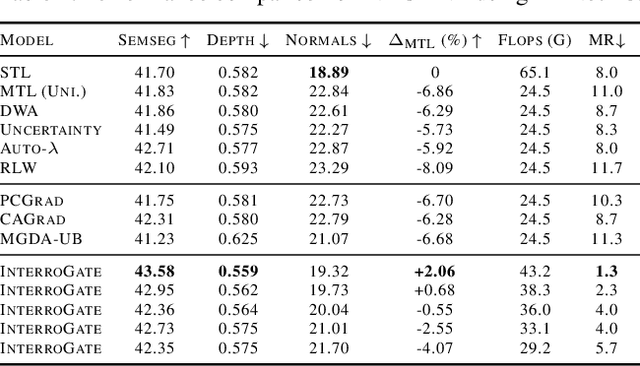

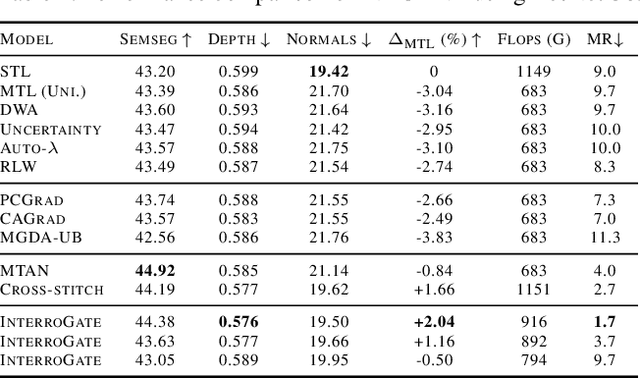
Jointly learning multiple tasks with a unified model can improve accuracy and data efficiency, but it faces the challenge of task interference, where optimizing one task objective may inadvertently compromise the performance of another. A solution to mitigate this issue is to allocate task-specific parameters, free from interference, on top of shared features. However, manually designing such architectures is cumbersome, as practitioners need to balance between the overall performance across all tasks and the higher computational cost induced by the newly added parameters. In this work, we propose \textit{InterroGate}, a novel multi-task learning (MTL) architecture designed to mitigate task interference while optimizing inference computational efficiency. We employ a learnable gating mechanism to automatically balance the shared and task-specific representations while preserving the performance of all tasks. Crucially, the patterns of parameter sharing and specialization dynamically learned during training, become fixed at inference, resulting in a static, optimized MTL architecture. Through extensive empirical evaluations, we demonstrate SoTA results on three MTL benchmarks using convolutional as well as transformer-based backbones on CelebA, NYUD-v2, and PASCAL-Context.