 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftmax Bias Correction for Quantized Generative Models
Sep 04, 2023Post-training quantization (PTQ) is the go-to compression technique for large generative models, such as stable diffusion or large language models. PTQ methods commonly keep the softmax activation in higher precision as it has been shown to be very sensitive to quantization noise. However, this can lead to a significant runtime and power overhead during inference on resource-constraint edge devices. In this work, we investigate the source of the softmax sensitivity to quantization and show that the quantization operation leads to a large bias in the softmax output, causing accuracy degradation. To overcome this issue, we propose an offline bias correction technique that improves the quantizability of softmax without additional compute during deployment, as it can be readily absorbed into the quantization parameters. We demonstrate the effectiveness of our method on stable diffusion v1.5 and 125M-size OPT language model, achieving significant accuracy improvement for 8-bit quantized softmax.
QBitOpt: Fast and Accurate Bitwidth Reallocation during Training
Jul 10, 2023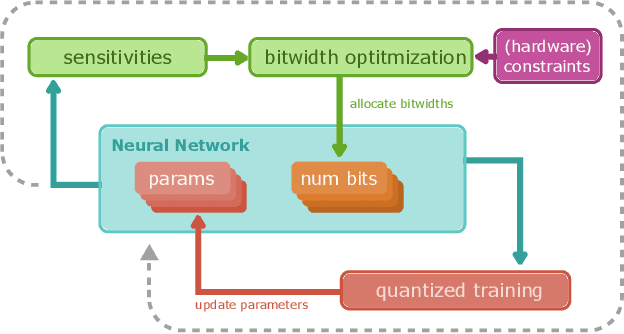
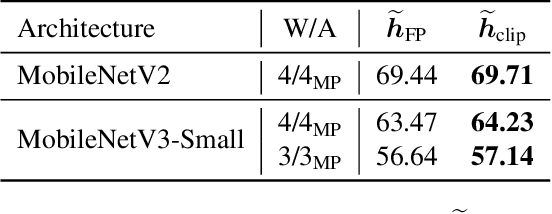
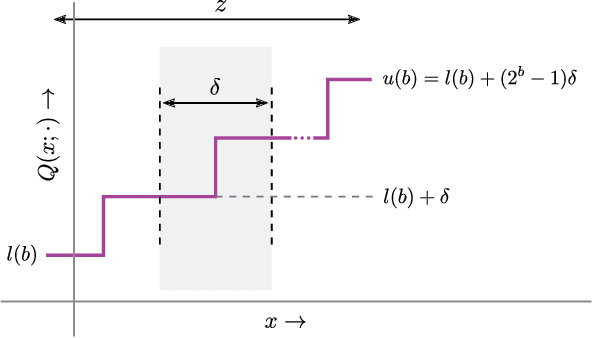
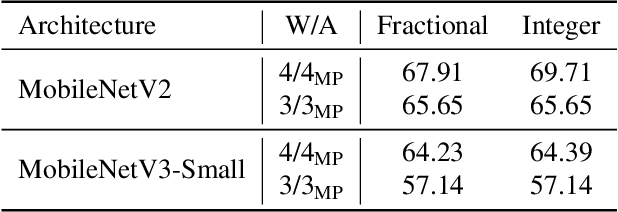
Quantizing neural networks is one of the most effective methods for achieving efficient inference on mobile and embedded devices. In particular, mixed precision quantized (MPQ) networks, whose layers can be quantized to different bitwidths, achieve better task performance for the same resource constraint compared to networks with homogeneous bitwidths. However, finding the optimal bitwidth allocation is a challenging problem as the search space grows exponentially with the number of layers in the network. In this paper, we propose QBitOpt, a novel algorithm for updating bitwidths during quantization-aware training (QAT). We formulate the bitwidth allocation problem as a constraint optimization problem. By combining fast-to-compute sensitivities with efficient solvers during QAT, QBitOpt can produce mixed-precision networks with high task performance guaranteed to satisfy strict resource constraints. This contrasts with existing mixed-precision methods that learn bitwidths using gradients and cannot provide such guarantees. We evaluate QBitOpt on ImageNet and confirm that we outperform existing fixed and mixed-precision methods under average bitwidth constraints commonly found in the literature.
Quantization Robust Federated Learning for Efficient Inference on Heterogeneous Devices
Jun 22, 2022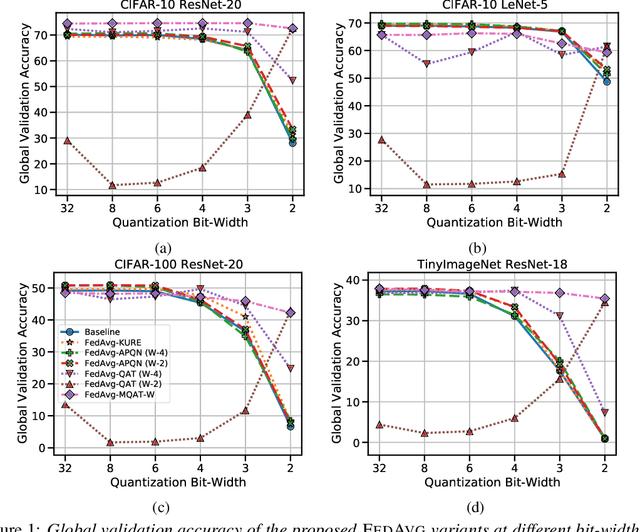
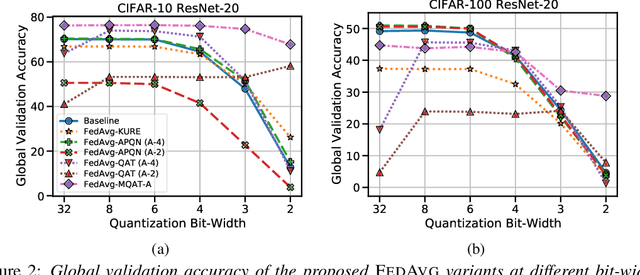
Federated Learning (FL) is a machine learning paradigm to distributively learn machine learning models from decentralized data that remains on-device. Despite the success of standard Federated optimization methods, such as Federated Averaging (FedAvg) in FL, the energy demands and hardware induced constraints for on-device learning have not been considered sufficiently in the literature. Specifically, an essential demand for on-device learning is to enable trained models to be quantized to various bit-widths based on the energy needs and heterogeneous hardware designs across the federation. In this work, we introduce multiple variants of federated averaging algorithm that train neural networks robust to quantization. Such networks can be quantized to various bit-widths with only limited reduction in full precision model accuracy. We perform extensive experiments on standard FL benchmarks to evaluate our proposed FedAvg variants for quantization robustness and provide a convergence analysis for our Quantization-Aware variants in FL. Our results demonstrate that integrating quantization robustness results in FL models that are significantly more robust to different bit-widths during quantized on-device inference.
Overcoming Oscillations in Quantization-Aware Training
Mar 21, 2022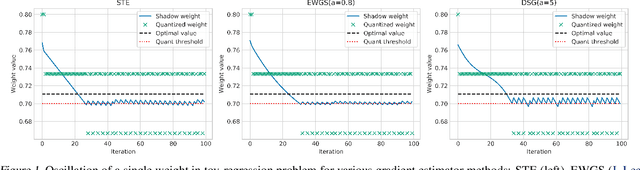
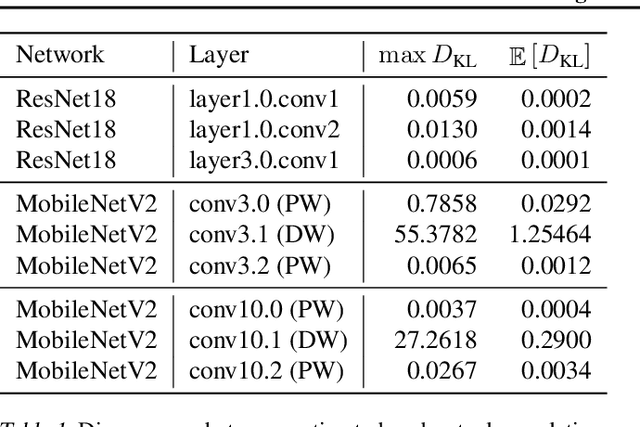
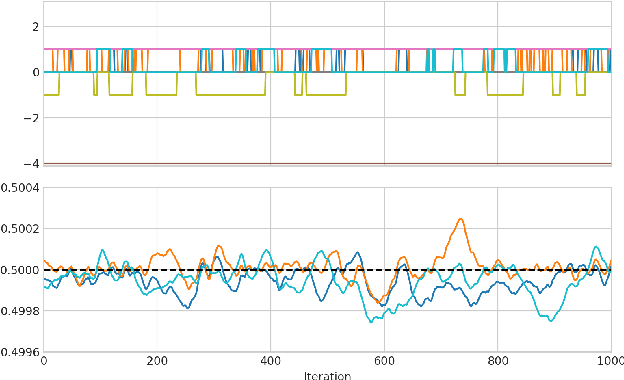
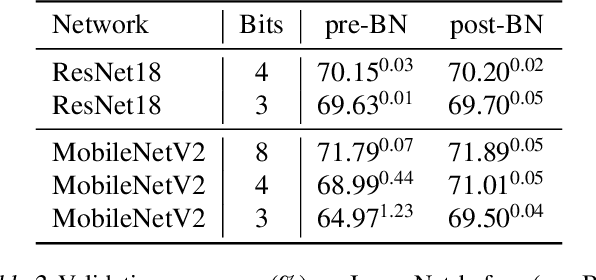
When training neural networks with simulated quantization, we observe that quantized weights can, rather unexpectedly, oscillate between two grid-points. The importance of this effect and its impact on quantization-aware training are not well-understood or investigated in literature. In this paper, we delve deeper into the phenomenon of weight oscillations and show that it can lead to a significant accuracy degradation due to wrongly estimated batch-normalization statistics during inference and increased noise during training. These effects are particularly pronounced in low-bit ($\leq$ 4-bits) quantization of efficient networks with depth-wise separable layers, such as MobileNets and EfficientNets. In our analysis we investigate several previously proposed quantization-aware training (QAT) algorithms and show that most of these are unable to overcome oscillations. Finally, we propose two novel QAT algorithms to overcome oscillations during training: oscillation dampening and iterative weight freezing. We demonstrate that our algorithms achieve state-of-the-art accuracy for low-bit (3 & 4 bits) weight and activation quantization of efficient architectures, such as MobileNetV2, MobileNetV3, and EfficentNet-lite on ImageNet.
Neural Network Quantization with AI Model Efficiency Toolkit (AIMET)
Jan 20, 2022
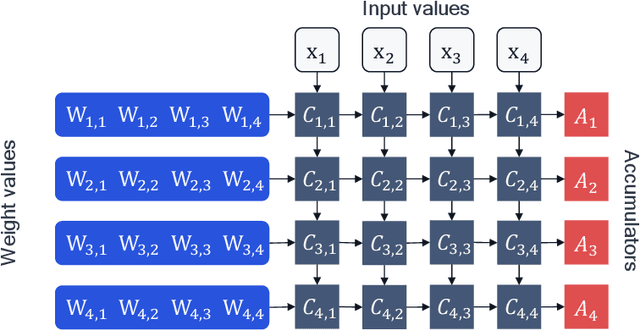

While neural networks have advanced the frontiers in many machine learning applications, they often come at a high computational cost. Reducing the power and latency of neural network inference is vital to integrating modern networks into edge devices with strict power and compute requirements. Neural network quantization is one of the most effective ways of achieving these savings, but the additional noise it induces can lead to accuracy degradation. In this white paper, we present an overview of neural network quantization using AI Model Efficiency Toolkit (AIMET). AIMET is a library of state-of-the-art quantization and compression algorithms designed to ease the effort required for model optimization and thus drive the broader AI ecosystem towards low latency and energy-efficient inference. AIMET provides users with the ability to simulate as well as optimize PyTorch and TensorFlow models. Specifically for quantization, AIMET includes various post-training quantization (PTQ, cf. chapter 4) and quantization-aware training (QAT, cf. chapter 5) techniques that guarantee near floating-point accuracy for 8-bit fixed-point inference. We provide a practical guide to quantization via AIMET by covering PTQ and QAT workflows, code examples and practical tips that enable users to efficiently and effectively quantize models using AIMET and reap the benefits of low-bit integer inference.
A White Paper on Neural Network Quantization
Jun 15, 2021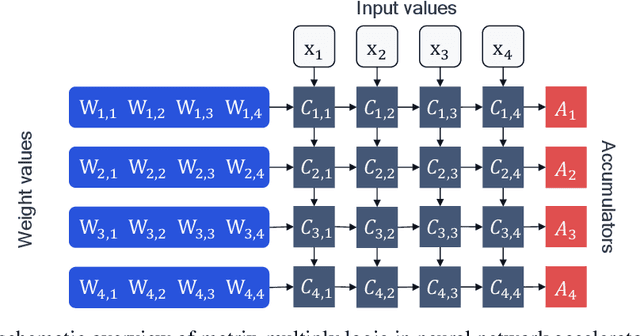
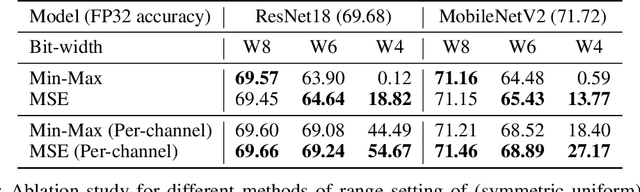
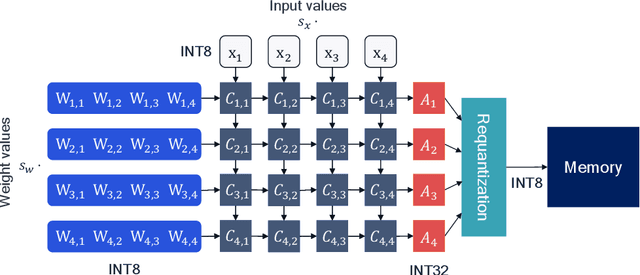
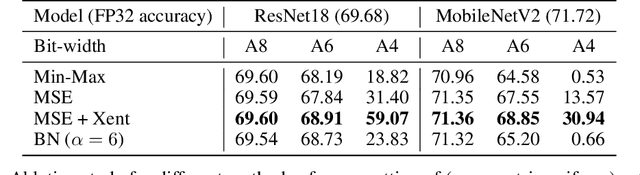
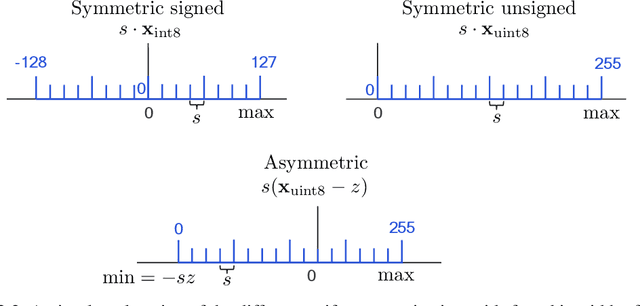
While neural networks have advanced the frontiers in many applications, they often come at a high computational cost. Reducing the power and latency of neural network inference is key if we want to integrate modern networks into edge devices with strict power and compute requirements. Neural network quantization is one of the most effective ways of achieving these savings but the additional noise it induces can lead to accuracy degradation. In this white paper, we introduce state-of-the-art algorithms for mitigating the impact of quantization noise on the network's performance while maintaining low-bit weights and activations. We start with a hardware motivated introduction to quantization and then consider two main classes of algorithms: Post-Training Quantization (PTQ) and Quantization-Aware-Training (QAT). PTQ requires no re-training or labelled data and is thus a lightweight push-button approach to quantization. In most cases, PTQ is sufficient for achieving 8-bit quantization with close to floating-point accuracy. QAT requires fine-tuning and access to labeled training data but enables lower bit quantization with competitive results. For both solutions, we provide tested pipelines based on existing literature and extensive experimentation that lead to state-of-the-art performance for common deep learning models and tasks.
In-Hindsight Quantization Range Estimation for Quantized Training
May 10, 2021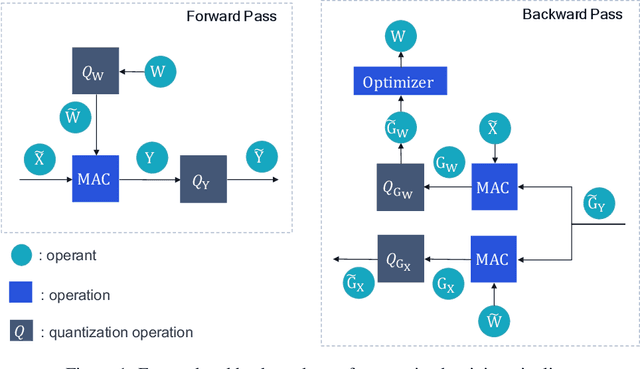

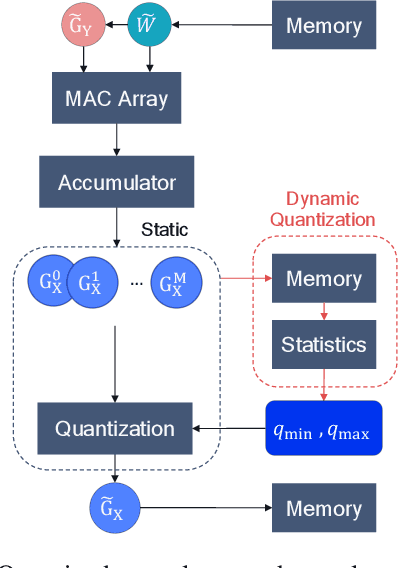
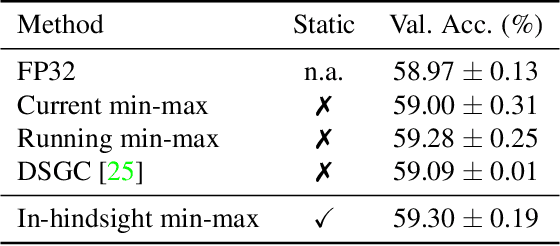
Quantization techniques applied to the inference of deep neural networks have enabled fast and efficient execution on resource-constraint devices. The success of quantization during inference has motivated the academic community to explore fully quantized training, i.e. quantizing back-propagation as well. However, effective gradient quantization is still an open problem. Gradients are unbounded and their distribution changes significantly during training, which leads to the need for dynamic quantization. As we show, dynamic quantization can lead to significant memory overhead and additional data traffic slowing down training. We propose a simple alternative to dynamic quantization, in-hindsight range estimation, that uses the quantization ranges estimated on previous iterations to quantize the present. Our approach enables fast static quantization of gradients and activations while requiring only minimal hardware support from the neural network accelerator to keep track of output statistics in an online fashion. It is intended as a drop-in replacement for estimating quantization ranges and can be used in conjunction with other advances in quantized training. We compare our method to existing methods for range estimation from the quantized training literature and demonstrate its effectiveness with a range of architectures, including MobileNetV2, on image classification benchmarks (Tiny ImageNet & ImageNet).