 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSM-CGM: Interpretable State-Space Forecasting Model of Continuous Glucose Monitoring for Personalized Diabetes Management
Oct 05, 2025Continuous glucose monitoring (CGM) generates dense data streams critical for diabetes management, but most used forecasting models lack interpretability for clinical use. We present SSM-CGM, a Mamba-based neural state-space forecasting model that integrates CGM and wearable activity signals from the AI-READI cohort. SSM-CGM improves short-term accuracy over a Temporal Fusion Transformer baseline, adds interpretability through variable selection and temporal attribution, and enables counterfactual forecasts simulating how planned changes in physiological signals (e.g., heart rate, respiration) affect near-term glucose. Together, these features make SSM-CGM an interpretable, physiologically grounded framework for personalized diabetes management.
An Agentic AI Workflow for Detecting Cognitive Concerns in Real-world Data
Feb 03, 2025Early identification of cognitive concerns is critical but often hindered by subtle symptom presentation. This study developed and validated a fully automated, multi-agent AI workflow using LLaMA 3 8B to identify cognitive concerns in 3,338 clinical notes from Mass General Brigham. The agentic workflow, leveraging task-specific agents that dynamically collaborate to extract meaningful insights from clinical notes, was compared to an expert-driven benchmark. Both workflows achieved high classification performance, with F1-scores of 0.90 and 0.91, respectively. The agentic workflow demonstrated improved specificity (1.00) and achieved prompt refinement in fewer iterations. Although both workflows showed reduced performance on validation data, the agentic workflow maintained perfect specificity. These findings highlight the potential of fully automated multi-agent AI workflows to achieve expert-level accuracy with greater efficiency, offering a scalable and cost-effective solution for detecting cognitive concerns in clinical settings.
How to Parameterize Asymmetric Quantization Ranges for Quantization-Aware Training
Apr 25, 2024



This paper investigates three different parameterizations of asymmetric uniform quantization for quantization-aware training: (1) scale and offset, (2) minimum and maximum, and (3) beta and gamma. We perform a comprehensive comparative analysis of these parameterizations' influence on quantization-aware training, using both controlled experiments and real-world large language models. Our particular focus is on their changing behavior in response to critical training hyperparameters, bit width and learning rate. Based on our investigation, we propose best practices to stabilize and accelerate quantization-aware training with learnable asymmetric quantization ranges.
DONNAv2 -- Lightweight Neural Architecture Search for Vision tasks
Sep 26, 2023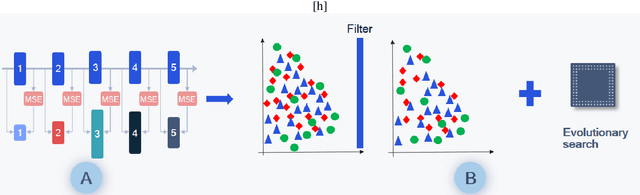

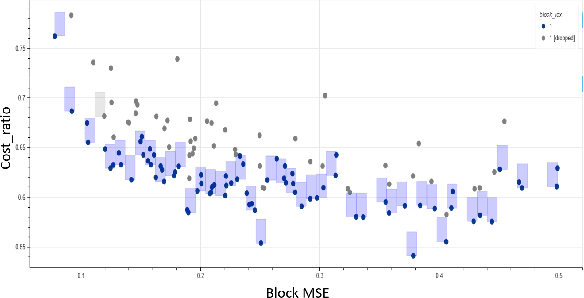

With the growing demand for vision applications and deployment across edge devices, the development of hardware-friendly architectures that maintain performance during device deployment becomes crucial. Neural architecture search (NAS) techniques explore various approaches to discover efficient architectures for diverse learning tasks in a computationally efficient manner. In this paper, we present the next-generation neural architecture design for computationally efficient neural architecture distillation - DONNAv2 . Conventional NAS algorithms rely on a computationally extensive stage where an accuracy predictor is learned to estimate model performance within search space. This building of accuracy predictors helps them predict the performance of models that are not being finetuned. Here, we have developed an elegant approach to eliminate building the accuracy predictor and extend DONNA to a computationally efficient setting. The loss metric of individual blocks forming the network serves as the surrogate performance measure for the sampled models in the NAS search stage. To validate the performance of DONNAv2 we have performed extensive experiments involving a range of diverse vision tasks including classification, object detection, image denoising, super-resolution, and panoptic perception network (YOLOP). The hardware-in-the-loop experiments were carried out using the Samsung Galaxy S10 mobile platform. Notably, DONNAv2 reduces the computational cost of DONNA by 10x for the larger datasets. Furthermore, to improve the quality of NAS search space, DONNAv2 leverages a block knowledge distillation filter to remove blocks with high inference costs.
Softmax Bias Correction for Quantized Generative Models
Sep 04, 2023Post-training quantization (PTQ) is the go-to compression technique for large generative models, such as stable diffusion or large language models. PTQ methods commonly keep the softmax activation in higher precision as it has been shown to be very sensitive to quantization noise. However, this can lead to a significant runtime and power overhead during inference on resource-constraint edge devices. In this work, we investigate the source of the softmax sensitivity to quantization and show that the quantization operation leads to a large bias in the softmax output, causing accuracy degradation. To overcome this issue, we propose an offline bias correction technique that improves the quantizability of softmax without additional compute during deployment, as it can be readily absorbed into the quantization parameters. We demonstrate the effectiveness of our method on stable diffusion v1.5 and 125M-size OPT language model, achieving significant accuracy improvement for 8-bit quantized softmax.
Speaker Diaphragm Excursion Prediction: deep attention and online adaptation
May 11, 2023Speaker protection algorithm is to leverage the playback signal properties to prevent over excursion while maintaining maximum loudness, especially for the mobile phone with tiny loudspeakers. This paper proposes efficient DL solutions to accurately model and predict the nonlinear excursion, which is challenging for conventional solutions. Firstly, we build the experiment and pre-processing pipeline, where the feedback current and voltage are sampled as input, and laser is employed to measure the excursion as ground truth. Secondly, one FFTNet model is proposed to explore the dominant low-frequency and other unknown harmonics, and compares to a baseline ConvNet model. In addition, BN re-estimation is designed to explore the online adaptation; and INT8 quantization based on AI Model efficiency toolkit (AIMET\footnote{AIMET is a product of Qualcomm Innovation Center, Inc.}) is applied to further reduce the complexity. The proposed algorithm is verified in two speakers and 3 typical deployment scenarios, and $>$99\% residual DC is less than 0.1 mm, much better than traditional solutions.
FP8 versus INT8 for efficient deep learning inference
Mar 31, 2023



Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
A Practical Mixed Precision Algorithm for Post-Training Quantization
Feb 10, 2023



Neural network quantization is frequently used to optimize model size, latency and power consumption for on-device deployment of neural networks. In many cases, a target bit-width is set for an entire network, meaning every layer get quantized to the same number of bits. However, for many networks some layers are significantly more robust to quantization noise than others, leaving an important axis of improvement unused. As many hardware solutions provide multiple different bit-width settings, mixed-precision quantization has emerged as a promising solution to find a better performance-efficiency trade-off than homogeneous quantization. However, most existing mixed precision algorithms are rather difficult to use for practitioners as they require access to the training data, have many hyper-parameters to tune or even depend on end-to-end retraining of the entire model. In this work, we present a simple post-training mixed precision algorithm that only requires a small unlabeled calibration dataset to automatically select suitable bit-widths for each layer for desirable on-device performance. Our algorithm requires no hyper-parameter tuning, is robust to data variation and takes into account practical hardware deployment constraints making it a great candidate for practical use. We experimentally validate our proposed method on several computer vision tasks, natural language processing tasks and many different networks, and show that we can find mixed precision networks that provide a better trade-off between accuracy and efficiency than their homogeneous bit-width equivalents.
Hand gesture recognition using 802.11ad mmWave sensor in the mobile device
Nov 14, 2022



We explore the feasibility of AI assisted hand-gesture recognition using 802.11ad 60GHz (mmWave) technology in smartphones. Range-Doppler information (RDI) is obtained by using pulse Doppler radar for gesture recognition. We built a prototype system, where radar sensing and WLAN communication waveform can coexist by time-division duplex (TDD), to demonstrate the real-time hand-gesture inference. It can gather sensing data and predict gestures within 100 milliseconds. First, we build the pipeline for the real-time feature processing, which is robust to occasional frame drops in the data stream. RDI sequence restoration is implemented to handle the frame dropping in the continuous data stream, and also applied to data augmentation. Second, different gestures RDI are analyzed, where finger and hand motions can clearly show distinctive features. Third, five typical gestures (swipe, palm-holding, pull-push, finger-sliding and noise) are experimented with, and a classification framework is explored to segment the different gestures in the continuous gesture sequence with arbitrary inputs. We evaluate our architecture on a large multi-person dataset and report > 95% accuracy with one CNN + LSTM model. Further, a pure CNN model is developed to fit to on-device implementation, which minimizes the inference latency, power consumption and computation cost. And the accuracy of this CNN model is more than 93% with only 2.29K parameters.
* 6 pages, 12 figures
Neural Network Quantization with AI Model Efficiency Toolkit (AIMET)
Jan 20, 2022
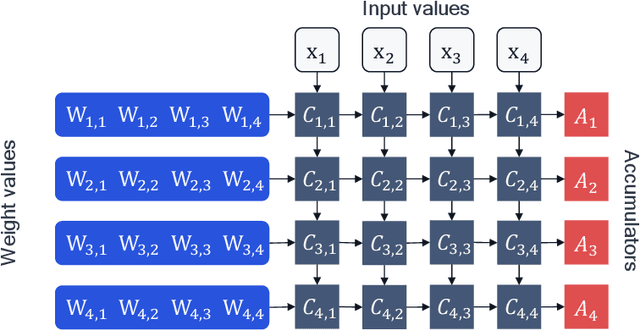

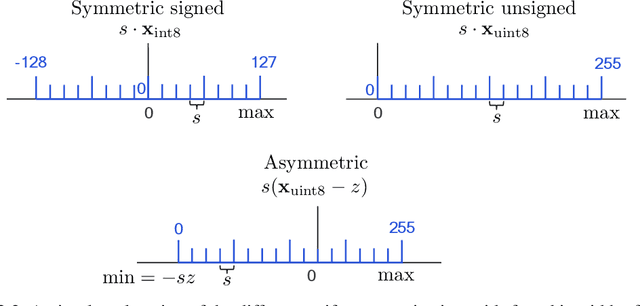
While neural networks have advanced the frontiers in many machine learning applications, they often come at a high computational cost. Reducing the power and latency of neural network inference is vital to integrating modern networks into edge devices with strict power and compute requirements. Neural network quantization is one of the most effective ways of achieving these savings, but the additional noise it induces can lead to accuracy degradation. In this white paper, we present an overview of neural network quantization using AI Model Efficiency Toolkit (AIMET). AIMET is a library of state-of-the-art quantization and compression algorithms designed to ease the effort required for model optimization and thus drive the broader AI ecosystem towards low latency and energy-efficient inference. AIMET provides users with the ability to simulate as well as optimize PyTorch and TensorFlow models. Specifically for quantization, AIMET includes various post-training quantization (PTQ, cf. chapter 4) and quantization-aware training (QAT, cf. chapter 5) techniques that guarantee near floating-point accuracy for 8-bit fixed-point inference. We provide a practical guide to quantization via AIMET by covering PTQ and QAT workflows, code examples and practical tips that enable users to efficiently and effectively quantize models using AIMET and reap the benefits of low-bit integer inference.