 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Éclair -- Extracting Content and Layout with Integrated Reading Order for Documents
Feb 06, 2025



Optical Character Recognition (OCR) technology is widely used to extract text from images of documents, facilitating efficient digitization and data retrieval. However, merely extracting text is insufficient when dealing with complex documents. Fully comprehending such documents requires an understanding of their structure -- including formatting, formulas, tables, and the reading order of multiple blocks and columns across multiple pages -- as well as semantic information for detecting elements like footnotes and image captions. This comprehensive understanding is crucial for downstream tasks such as retrieval, document question answering, and data curation for training Large Language Models (LLMs) and Vision Language Models (VLMs). To address this, we introduce \'Eclair, a general-purpose text-extraction tool specifically designed to process a wide range of document types. Given an image, \'Eclair is able to extract formatted text in reading order, along with bounding boxes and their corresponding semantic classes. To thoroughly evaluate these novel capabilities, we introduce our diverse human-annotated benchmark for document-level OCR and semantic classification. \'Eclair achieves state-of-the-art accuracy on this benchmark, outperforming other methods across key metrics. Additionally, we evaluate \'Eclair on established benchmarks, demonstrating its versatility and strength across several evaluation standards.
Revisiting Single-gated Mixtures of Experts
Apr 11, 2023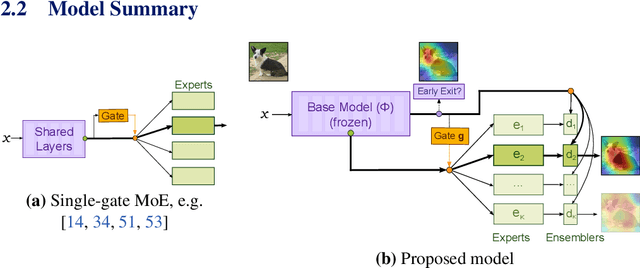
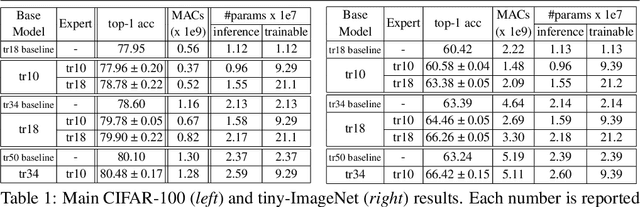
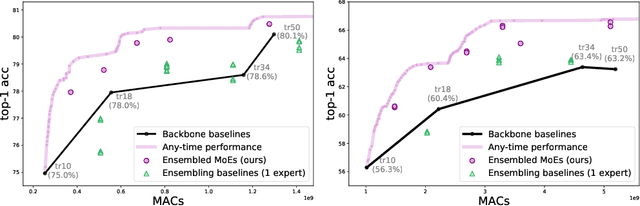
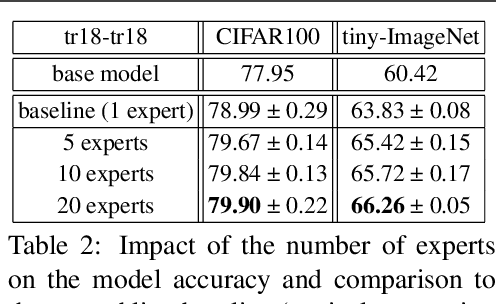
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.
Hand gesture recognition using 802.11ad mmWave sensor in the mobile device
Nov 14, 2022



We explore the feasibility of AI assisted hand-gesture recognition using 802.11ad 60GHz (mmWave) technology in smartphones. Range-Doppler information (RDI) is obtained by using pulse Doppler radar for gesture recognition. We built a prototype system, where radar sensing and WLAN communication waveform can coexist by time-division duplex (TDD), to demonstrate the real-time hand-gesture inference. It can gather sensing data and predict gestures within 100 milliseconds. First, we build the pipeline for the real-time feature processing, which is robust to occasional frame drops in the data stream. RDI sequence restoration is implemented to handle the frame dropping in the continuous data stream, and also applied to data augmentation. Second, different gestures RDI are analyzed, where finger and hand motions can clearly show distinctive features. Third, five typical gestures (swipe, palm-holding, pull-push, finger-sliding and noise) are experimented with, and a classification framework is explored to segment the different gestures in the continuous gesture sequence with arbitrary inputs. We evaluate our architecture on a large multi-person dataset and report > 95% accuracy with one CNN + LSTM model. Further, a pure CNN model is developed to fit to on-device implementation, which minimizes the inference latency, power consumption and computation cost. And the accuracy of this CNN model is more than 93% with only 2.29K parameters.
* 6 pages, 12 figures
Motion-Augmented Self-Training for Video Recognition at Smaller Scale
May 04, 2021
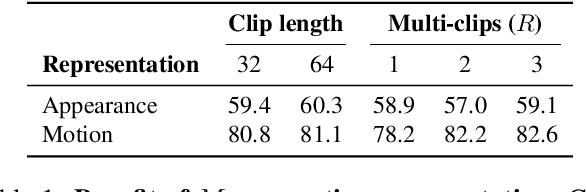


The goal of this paper is to self-train a 3D convolutional neural network on an unlabeled video collection for deployment on small-scale video collections. As smaller video datasets benefit more from motion than appearance, we strive to train our network using optical flow, but avoid its computation during inference. We propose the first motion-augmented self-training regime, we call MotionFit. We start with supervised training of a motion model on a small, and labeled, video collection. With the motion model we generate pseudo-labels for a large unlabeled video collection, which enables us to transfer knowledge by learning to predict these pseudo-labels with an appearance model. Moreover, we introduce a multi-clip loss as a simple yet efficient way to improve the quality of the pseudo-labeling, even without additional auxiliary tasks. We also take into consideration the temporal granularity of videos during self-training of the appearance model, which was missed in previous works. As a result we obtain a strong motion-augmented representation model suited for video downstream tasks like action recognition and clip retrieval. On small-scale video datasets, MotionFit outperforms alternatives for knowledge transfer by 5%-8%, video-only self-supervision by 1%-7% and semi-supervised learning by 9%-18% using the same amount of class labels.