 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Éclair -- Extracting Content and Layout with Integrated Reading Order for Documents
Feb 06, 2025



Optical Character Recognition (OCR) technology is widely used to extract text from images of documents, facilitating efficient digitization and data retrieval. However, merely extracting text is insufficient when dealing with complex documents. Fully comprehending such documents requires an understanding of their structure -- including formatting, formulas, tables, and the reading order of multiple blocks and columns across multiple pages -- as well as semantic information for detecting elements like footnotes and image captions. This comprehensive understanding is crucial for downstream tasks such as retrieval, document question answering, and data curation for training Large Language Models (LLMs) and Vision Language Models (VLMs). To address this, we introduce \'Eclair, a general-purpose text-extraction tool specifically designed to process a wide range of document types. Given an image, \'Eclair is able to extract formatted text in reading order, along with bounding boxes and their corresponding semantic classes. To thoroughly evaluate these novel capabilities, we introduce our diverse human-annotated benchmark for document-level OCR and semantic classification. \'Eclair achieves state-of-the-art accuracy on this benchmark, outperforming other methods across key metrics. Additionally, we evaluate \'Eclair on established benchmarks, demonstrating its versatility and strength across several evaluation standards.
Temporal Lidar Depth Completion
Jun 17, 2024Given the lidar measurements from an autonomous vehicle, we can project the points and generate a sparse depth image. Depth completion aims at increasing the resolution of such a depth image by infilling and interpolating the sparse depth values. Like most existing approaches, we make use of camera images as guidance in very sparse or occluded regions. In addition, we propose a temporal algorithm that utilizes information from previous timesteps using recurrence. In this work, we show how a state-of-the-art method PENet can be modified to benefit from recurrency. Our algorithm achieves state-of-the-art results on the KITTI depth completion dataset while adding only less than one percent of additional overhead in terms of both neural network parameters and floating point operations. The accuracy is especially improved for faraway objects and regions containing a low amount of lidar depth samples. Even in regions without any ground truth (like sky and rooftops) we observe large improvements which are not captured by the existing evaluation metrics.
What Makes Good Synthetic Training Data for Learning Disparity and Optical Flow Estimation?
Mar 22, 2018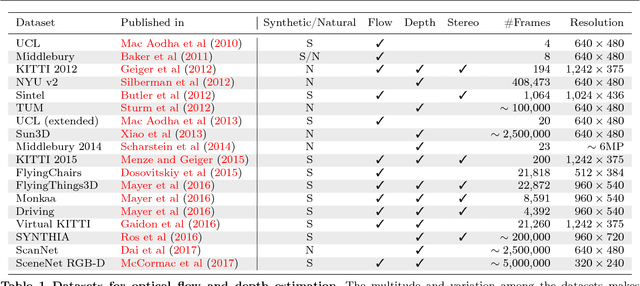

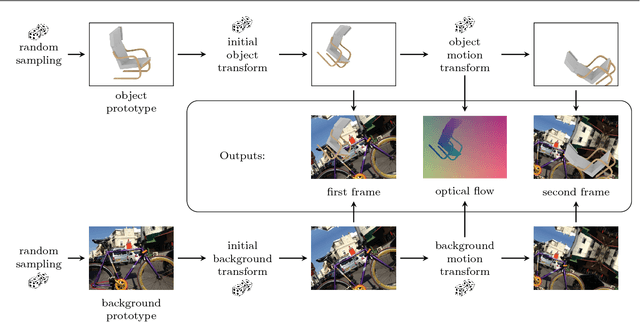

The finding that very large networks can be trained efficiently and reliably has led to a paradigm shift in computer vision from engineered solutions to learning formulations. As a result, the research challenge shifts from devising algorithms to creating suitable and abundant training data for supervised learning. How to efficiently create such training data? The dominant data acquisition method in visual recognition is based on web data and manual annotation. Yet, for many computer vision problems, such as stereo or optical flow estimation, this approach is not feasible because humans cannot manually enter a pixel-accurate flow field. In this paper, we promote the use of synthetically generated data for the purpose of training deep networks on such tasks.We suggest multiple ways to generate such data and evaluate the influence of dataset properties on the performance and generalization properties of the resulting networks. We also demonstrate the benefit of learning schedules that use different types of data at selected stages of the training process.
A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation
Dec 07, 2015
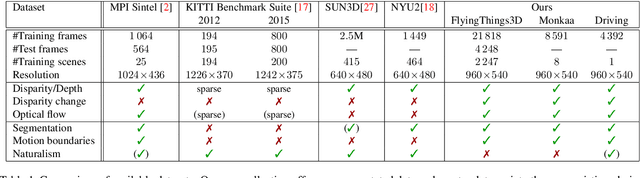

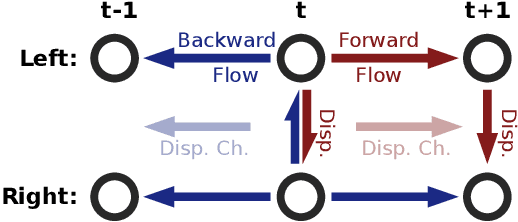
Recent work has shown that optical flow estimation can be formulated as a supervised learning task and can be successfully solved with convolutional networks. Training of the so-called FlowNet was enabled by a large synthetically generated dataset. The present paper extends the concept of optical flow estimation via convolutional networks to disparity and scene flow estimation. To this end, we propose three synthetic stereo video datasets with sufficient realism, variation, and size to successfully train large networks. Our datasets are the first large-scale datasets to enable training and evaluating scene flow methods. Besides the datasets, we present a convolutional network for real-time disparity estimation that provides state-of-the-art results. By combining a flow and disparity estimation network and training it jointly, we demonstrate the first scene flow estimation with a convolutional network.
Descriptor Matching with Convolutional Neural Networks: a Comparison to SIFT
Jun 24, 2015
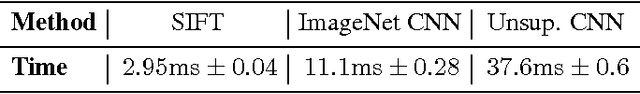


Latest results indicate that features learned via convolutional neural networks outperform previous descriptors on classification tasks by a large margin. It has been shown that these networks still work well when they are applied to datasets or recognition tasks different from those they were trained on. However, descriptors like SIFT are not only used in recognition but also for many correspondence problems that rely on descriptor matching. In this paper we compare features from various layers of convolutional neural nets to standard SIFT descriptors. We consider a network that was trained on ImageNet and another one that was trained without supervision. Surprisingly, convolutional neural networks clearly outperform SIFT on descriptor matching. This paper has been merged with arXiv:1406.6909
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
Jun 19, 2015



Deep convolutional networks have proven to be very successful in learning task specific features that allow for unprecedented performance on various computer vision tasks. Training of such networks follows mostly the supervised learning paradigm, where sufficiently many input-output pairs are required for training. Acquisition of large training sets is one of the key challenges, when approaching a new task. In this paper, we aim for generic feature learning and present an approach for training a convolutional network using only unlabeled data. To this end, we train the network to discriminate between a set of surrogate classes. Each surrogate class is formed by applying a variety of transformations to a randomly sampled 'seed' image patch. In contrast to supervised network training, the resulting feature representation is not class specific. It rather provides robustness to the transformations that have been applied during training. This generic feature representation allows for classification results that outperform the state of the art for unsupervised learning on several popular datasets (STL-10, CIFAR-10, Caltech-101, Caltech-256). While such generic features cannot compete with class specific features from supervised training on a classification task, we show that they are advantageous on geometric matching problems, where they also outperform the SIFT descriptor.
U-Net: Convolutional Networks for Biomedical Image Segmentation
May 18, 2015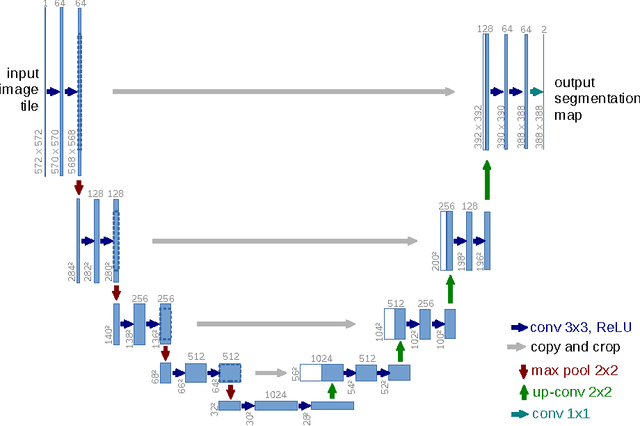

There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated samples more efficiently. The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. We show that such a network can be trained end-to-end from very few images and outperforms the prior best method (a sliding-window convolutional network) on the ISBI challenge for segmentation of neuronal structures in electron microscopic stacks. Using the same network trained on transmitted light microscopy images (phase contrast and DIC) we won the ISBI cell tracking challenge 2015 in these categories by a large margin. Moreover, the network is fast. Segmentation of a 512x512 image takes less than a second on a recent GPU. The full implementation (based on Caffe) and the trained networks are available at http://lmb.informatik.uni-freiburg.de/people/ronneber/u-net .
FlowNet: Learning Optical Flow with Convolutional Networks
May 04, 2015
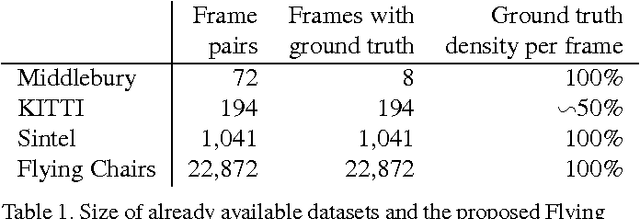

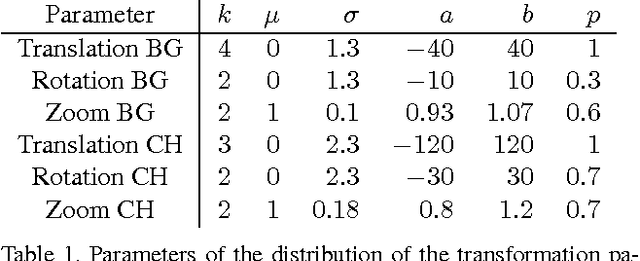
Convolutional neural networks (CNNs) have recently been very successful in a variety of computer vision tasks, especially on those linked to recognition. Optical flow estimation has not been among the tasks where CNNs were successful. In this paper we construct appropriate CNNs which are capable of solving the optical flow estimation problem as a supervised learning task. We propose and compare two architectures: a generic architecture and another one including a layer that correlates feature vectors at different image locations. Since existing ground truth data sets are not sufficiently large to train a CNN, we generate a synthetic Flying Chairs dataset. We show that networks trained on this unrealistic data still generalize very well to existing datasets such as Sintel and KITTI, achieving competitive accuracy at frame rates of 5 to 10 fps.