 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Éclair -- Extracting Content and Layout with Integrated Reading Order for Documents
Feb 06, 2025



Optical Character Recognition (OCR) technology is widely used to extract text from images of documents, facilitating efficient digitization and data retrieval. However, merely extracting text is insufficient when dealing with complex documents. Fully comprehending such documents requires an understanding of their structure -- including formatting, formulas, tables, and the reading order of multiple blocks and columns across multiple pages -- as well as semantic information for detecting elements like footnotes and image captions. This comprehensive understanding is crucial for downstream tasks such as retrieval, document question answering, and data curation for training Large Language Models (LLMs) and Vision Language Models (VLMs). To address this, we introduce \'Eclair, a general-purpose text-extraction tool specifically designed to process a wide range of document types. Given an image, \'Eclair is able to extract formatted text in reading order, along with bounding boxes and their corresponding semantic classes. To thoroughly evaluate these novel capabilities, we introduce our diverse human-annotated benchmark for document-level OCR and semantic classification. \'Eclair achieves state-of-the-art accuracy on this benchmark, outperforming other methods across key metrics. Additionally, we evaluate \'Eclair on established benchmarks, demonstrating its versatility and strength across several evaluation standards.
MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild
Apr 13, 2024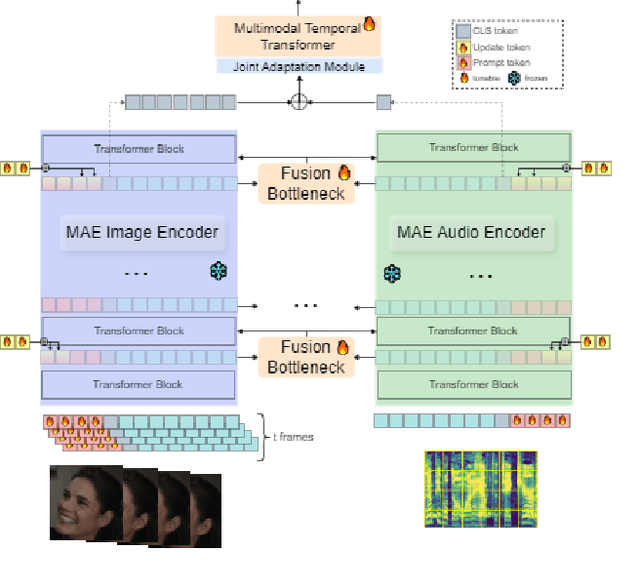
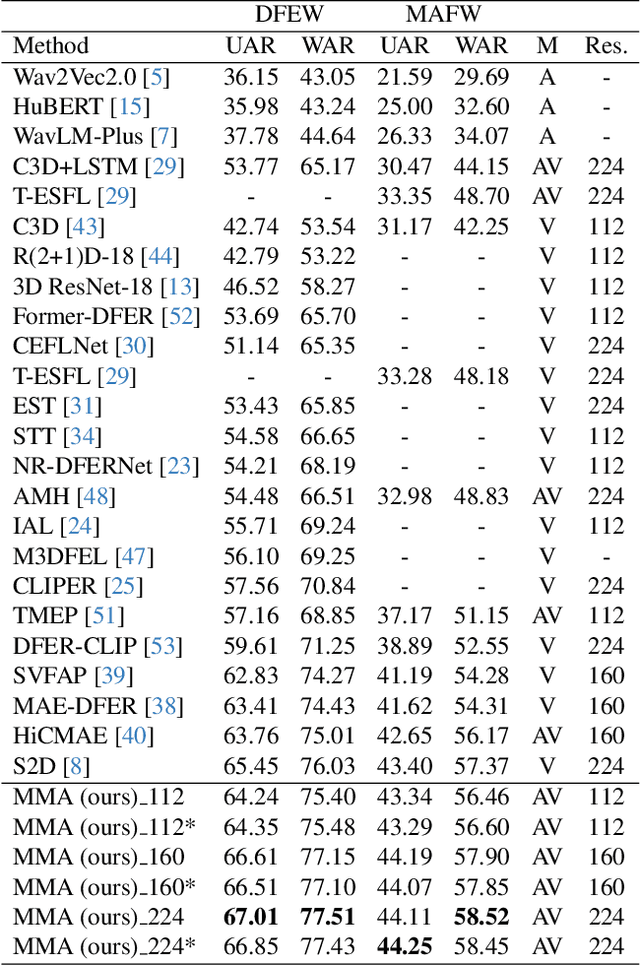
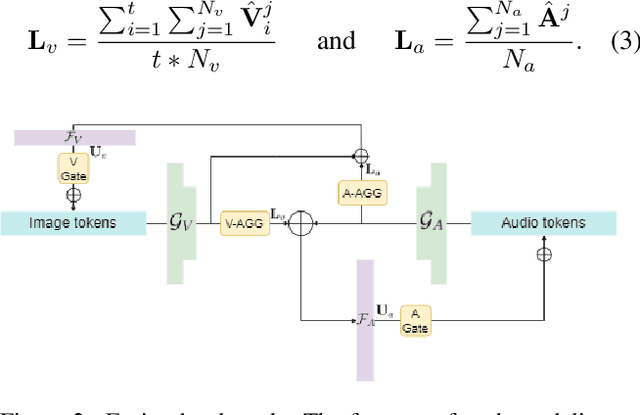
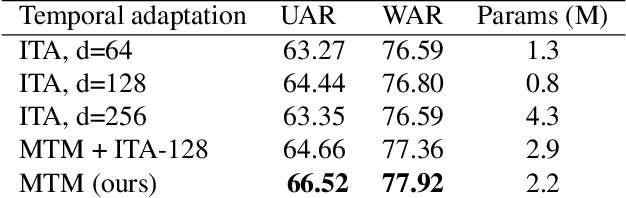
Dynamic Facial Expression Recognition (DFER) has received significant interest in the recent years dictated by its pivotal role in enabling empathic and human-compatible technologies. Achieving robustness towards in-the-wild data in DFER is particularly important for real-world applications. One of the directions aimed at improving such models is multimodal emotion recognition based on audio and video data. Multimodal learning in DFER increases the model capabilities by leveraging richer, complementary data representations. Within the field of multimodal DFER, recent methods have focused on exploiting advances of self-supervised learning (SSL) for pre-training of strong multimodal encoders. Another line of research has focused on adapting pre-trained static models for DFER. In this work, we propose a different perspective on the problem and investigate the advancement of multimodal DFER performance by adapting SSL-pre-trained disjoint unimodal encoders. We identify main challenges associated with this task, namely, intra-modality adaptation, cross-modal alignment, and temporal adaptation, and propose solutions to each of them. As a result, we demonstrate improvement over current state-of-the-art on two popular DFER benchmarks, namely DFEW and MFAW.
Improving Unimodal Inference with Multimodal Transformers
Nov 16, 2023



This paper proposes an approach for improving performance of unimodal models with multimodal training. Our approach involves a multi-branch architecture that incorporates unimodal models with a multimodal transformer-based branch. By co-training these branches, the stronger multimodal branch can transfer its knowledge to the weaker unimodal branches through a multi-task objective, thereby improving the performance of the resulting unimodal models. We evaluate our approach on tasks of dynamic hand gesture recognition based on RGB and Depth, audiovisual emotion recognition based on speech and facial video, and audio-video-text based sentiment analysis. Our approach outperforms the conventionally trained unimodal counterparts. Interestingly, we also observe that optimization of the unimodal branches improves the multimodal branch, compared to a similar multimodal model trained from scratch.
Self-attention fusion for audiovisual emotion recognition with incomplete data
Jan 26, 2022



In this paper, we consider the problem of multimodal data analysis with a use case of audiovisual emotion recognition. We propose an architecture capable of learning from raw data and describe three variants of it with distinct modality fusion mechanisms. While most of the previous works consider the ideal scenario of presence of both modalities at all times during inference, we evaluate the robustness of the model in the unconstrained settings where one modality is absent or noisy, and propose a method to mitigate these limitations in a form of modality dropout. Most importantly, we find that following this approach not only improves performance drastically under the absence/noisy representations of one modality, but also improves the performance in a standard ideal setting, outperforming the competing methods.
Self-Attention Neural Bag-of-Features
Jan 26, 2022
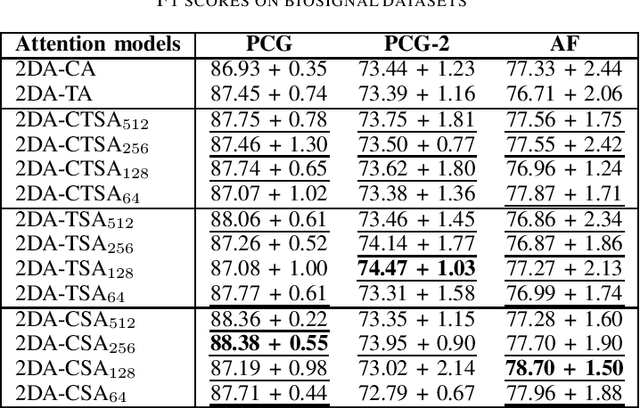

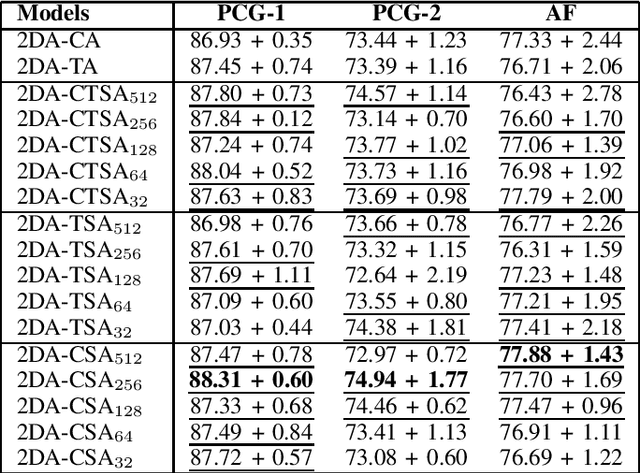
In this work, we propose several attention formulations for multivariate sequence data. We build on top of the recently introduced 2D-Attention and reformulate the attention learning methodology by quantifying the relevance of feature/temporal dimensions through latent spaces based on self-attention rather than learning them directly. In addition, we propose a joint feature-temporal attention mechanism that learns a joint 2D attention mask highlighting relevant information without treating feature and temporal representations independently. The proposed approaches can be used in various architectures and we specifically evaluate their application together with Neural Bag of Features feature extraction module. Experiments on several sequence data analysis tasks show the improved performance yielded by our approach compared to standard methods.
Learning to ignore: rethinking attention in CNNs
Nov 10, 2021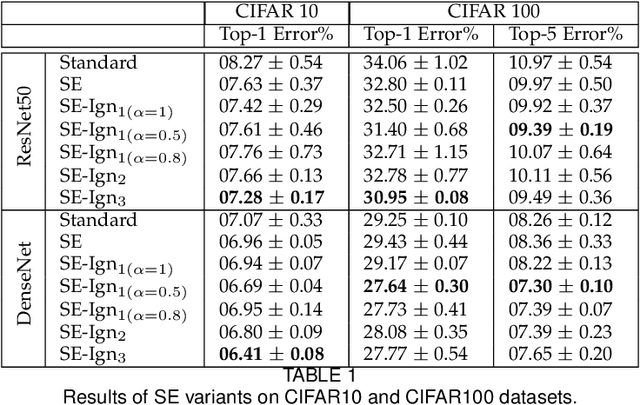



Recently, there has been an increasing interest in applying attention mechanisms in Convolutional Neural Networks (CNNs) to solve computer vision tasks. Most of these methods learn to explicitly identify and highlight relevant parts of the scene and pass the attended image to further layers of the network. In this paper, we argue that such an approach might not be optimal. Arguably, explicitly learning which parts of the image are relevant is typically harder than learning which parts of the image are less relevant and, thus, should be ignored. In fact, in vision domain, there are many easy-to-identify patterns of irrelevant features. For example, image regions close to the borders are less likely to contain useful information for a classification task. Based on this idea, we propose to reformulate the attention mechanism in CNNs to learn to ignore instead of learning to attend. Specifically, we propose to explicitly learn irrelevant information in the scene and suppress it in the produced representation, keeping only important attributes. This implicit attention scheme can be incorporated into any existing attention mechanism. In this work, we validate this idea using two recent attention methods Squeeze and Excitation (SE) block and Convolutional Block Attention Module (CBAM). Experimental results on different datasets and model architectures show that learning to ignore, i.e., implicit attention, yields superior performance compared to the standard approaches.
Ensembling object detectors for image and video data analysis
Feb 09, 2021


In this paper, we propose a method for ensembling the outputs of multiple object detectors for improving detection performance and precision of bounding boxes on image data. We further extend it to video data by proposing a two-stage tracking-based scheme for detection refinement. The proposed method can be used as a standalone approach for improving object detection performance, or as a part of a framework for faster bounding box annotation in unseen datasets, assuming that the objects of interest are those present in some common public datasets.
Incremental Fast Subclass Discriminant Analysis
Feb 11, 2020
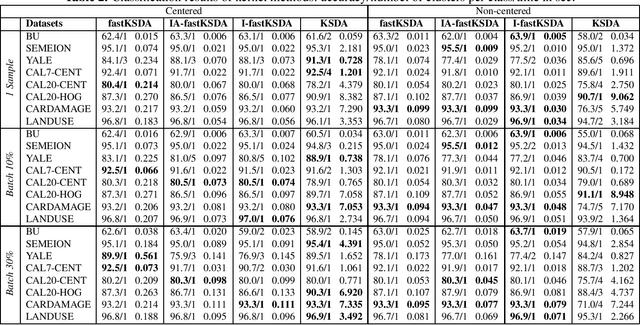
This paper proposes an incremental solution to Fast Subclass Discriminant Analysis (fastSDA). We present an exact and an approximate linear solution, along with an approximate kernelized variant. Extensive experiments on eight image datasets with different incremental batch sizes show the superiority of the proposed approach in terms of training time and accuracy being equal or close to fastSDA solution and outperforming other methods.