 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning to Explore: Curiosity-Driven Planning for LLM Test Generation
Apr 06, 2026The use of LLMs for code generation has naturally extended to code testing and evaluation. As codebases grow in size and complexity, so does the need for automated test generation. Current approaches for LLM-based test generation rely on strategies that maximize immediate coverage gain, a greedy approach that plateaus on code where reaching deep branches requires setup steps that individually yield zero new coverage. Drawing on principles of Bayesian exploration, we treat the program's branch structure as an unknown environment, and an evolving coverage map as a proxy probabilistic posterior representing what the LLM has discovered so far. Our method, CovQValue, feeds the coverage map back to the LLM, generates diverse candidate plans in parallel, and selects the most informative plan by LLM-estimated Q-values, seeking actions that balance immediate branch discovery with future reachability. Our method outperforms greedy selection on TestGenEval Lite, achieving 51-77% higher branch coverage across three popular LLMs and winning on 77-84% of targets. In addition, we build a benchmark for iterative test generation, RepoExploreBench, where they achieve 40-74%. These results show the potential of curiosity-driven planning methods for LLM-based exploration, enabling more effective discovery of program behavior through sequential interaction
Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
Oct 24, 2025Recent studies operationalize self-improvement through coding agents that edit their own codebases. They grow a tree of self-modifications through expansion strategies that favor higher software engineering benchmark performance, assuming that this implies more promising subsequent self-modifications. However, we identify a mismatch between the agent's self-improvement potential (metaproductivity) and its coding benchmark performance, namely the Metaproductivity-Performance Mismatch. Inspired by Huxley's concept of clade, we propose a metric ($\mathrm{CMP}$) that aggregates the benchmark performances of the descendants of an agent as an indicator of its potential for self-improvement. We show that, in our self-improving coding agent development setting, access to the true $\mathrm{CMP}$ is sufficient to simulate how the G\"odel Machine would behave under certain assumptions. We introduce the Huxley-G\"odel Machine (HGM), which, by estimating $\mathrm{CMP}$ and using it as guidance, searches the tree of self-modifications. On SWE-bench Verified and Polyglot, HGM outperforms prior self-improving coding agent development methods while using less wall-clock time. Last but not least, HGM demonstrates strong transfer to other coding datasets and large language models. The agent optimized by HGM on SWE-bench Verified with GPT-5-mini and evaluated on SWE-bench Lite with GPT-5 achieves human-level performance, matching the best officially checked results of human-engineered coding agents. Our code is available at https://github.com/metauto-ai/HGM.
Fairness Overfitting in Machine Learning: An Information-Theoretic Perspective
Jun 09, 2025Despite substantial progress in promoting fairness in high-stake applications using machine learning models, existing methods often modify the training process, such as through regularizers or other interventions, but lack formal guarantees that fairness achieved during training will generalize to unseen data. Although overfitting with respect to prediction performance has been extensively studied, overfitting in terms of fairness loss has received far less attention. This paper proposes a theoretical framework for analyzing fairness generalization error through an information-theoretic lens. Our novel bounding technique is based on Efron-Stein inequality, which allows us to derive tight information-theoretic fairness generalization bounds with both Mutual Information (MI) and Conditional Mutual Information (CMI). Our empirical results validate the tightness and practical relevance of these bounds across diverse fairness-aware learning algorithms. Our framework offers valuable insights to guide the design of algorithms improving fairness generalization.
FACTS: A Factored State-Space Framework For World Modelling
Oct 28, 2024



World modelling is essential for understanding and predicting the dynamics of complex systems by learning both spatial and temporal dependencies. However, current frameworks, such as Transformers and selective state-space models like Mambas, exhibit limitations in efficiently encoding spatial and temporal structures, particularly in scenarios requiring long-term high-dimensional sequence modelling. To address these issues, we propose a novel recurrent framework, the \textbf{FACT}ored \textbf{S}tate-space (\textbf{FACTS}) model, for spatial-temporal world modelling. The FACTS framework constructs a graph-structured memory with a routing mechanism that learns permutable memory representations, ensuring invariance to input permutations while adapting through selective state-space propagation. Furthermore, FACTS supports parallel computation of high-dimensional sequences. We empirically evaluate FACTS across diverse tasks, including multivariate time series forecasting and object-centric world modelling, demonstrating that it consistently outperforms or matches specialised state-of-the-art models, despite its general-purpose world modelling design.
Pixel-Wise Color Constancy via Smoothness Techniques in Multi-Illuminant Scenes
Feb 05, 2024



Most scenes are illuminated by several light sources, where the traditional assumption of uniform illumination is invalid. This issue is ignored in most color constancy methods, primarily due to the complex spatial impact of multiple light sources on the image. Moreover, most existing multi-illuminant methods fail to preserve the smooth change of illumination, which stems from spatial dependencies in natural images. Motivated by this, we propose a novel multi-illuminant color constancy method, by learning pixel-wise illumination maps caused by multiple light sources. The proposed method enforces smoothness within neighboring pixels, by regularizing the training with the total variation loss. Moreover, a bilateral filter is provisioned further to enhance the natural appearance of the estimated images, while preserving the edges. Additionally, we propose a label-smoothing technique that enables the model to generalize well despite the uncertainties in ground truth. Quantitative and qualitative experiments demonstrate that the proposed method outperforms the state-of-the-art.
Class-wise Generalization Error: an Information-Theoretic Analysis
Jan 05, 2024Existing generalization theories of supervised learning typically take a holistic approach and provide bounds for the expected generalization over the whole data distribution, which implicitly assumes that the model generalizes similarly for all the classes. In practice, however, there are significant variations in generalization performance among different classes, which cannot be captured by the existing generalization bounds. In this work, we tackle this problem by theoretically studying the class-generalization error, which quantifies the generalization performance of each individual class. We derive a novel information-theoretic bound for class-generalization error using the KL divergence, and we further obtain several tighter bounds using the conditional mutual information (CMI), which are significantly easier to estimate in practice. We empirically validate our proposed bounds in different neural networks and show that they accurately capture the complex class-generalization error behavior. Moreover, we show that the theoretical tools developed in this paper can be applied in several applications beyond this context.
Convolutional autoencoder-based multimodal one-class classification
Sep 25, 2023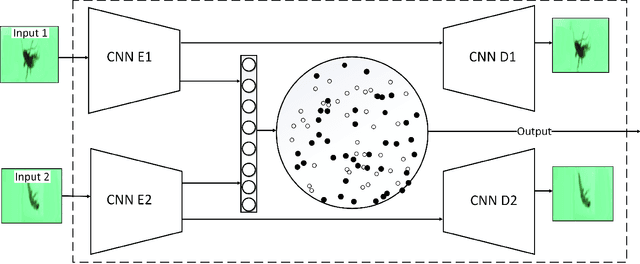
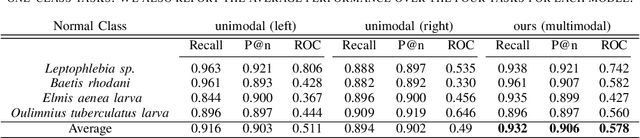

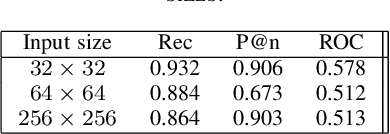
One-class classification refers to approaches of learning using data from a single class only. In this paper, we propose a deep learning one-class classification method suitable for multimodal data, which relies on two convolutional autoencoders jointly trained to reconstruct the positive input data while obtaining the data representations in the latent space as compact as possible. During inference, the distance of the latent representation of an input to the origin can be used as an anomaly score. Experimental results using a multimodal macroinvertebrate image classification dataset show that the proposed multimodal method yields better results as compared to the unimodal approach. Furthermore, study the effect of different input image sizes, and we investigate how recently proposed feature diversity regularizers affect the performance of our approach. We show that such regularizers improve performance.
Newton Method-based Subspace Support Vector Data Description
Sep 25, 2023In this paper, we present an adaptation of Newton's method for the optimization of Subspace Support Vector Data Description (S-SVDD). The objective of S-SVDD is to map the original data to a subspace optimized for one-class classification, and the iterative optimization process of data mapping and description in S-SVDD relies on gradient descent. However, gradient descent only utilizes first-order information, which may lead to suboptimal results. To address this limitation, we leverage Newton's method to enhance data mapping and data description for an improved optimization of subspace learning-based one-class classification. By incorporating this auxiliary information, Newton's method offers a more efficient strategy for subspace learning in one-class classification as compared to gradient-based optimization. The paper discusses the limitations of gradient descent and the advantages of using Newton's method in subspace learning for one-class classification tasks. We provide both linear and nonlinear formulations of Newton's method-based optimization for S-SVDD. In our experiments, we explored both the minimization and maximization strategies of the objective. The results demonstrate that the proposed optimization strategy outperforms the gradient-based S-SVDD in most cases.
On Feature Diversity in Energy-based Models
Jun 02, 2023Energy-based learning is a powerful learning paradigm that encapsulates various discriminative and generative approaches. An energy-based model (EBM) is typically formed of inner-model(s) that learn a combination of the different features to generate an energy mapping for each input configuration. In this paper, we focus on the diversity of the produced feature set. We extend the probably approximately correct (PAC) theory of EBMs and analyze the effect of redundancy reduction on the performance of EBMs. We derive generalization bounds for various learning contexts, i.e., regression, classification, and implicit regression, with different energy functions and we show that indeed reducing redundancy of the feature set can consistently decrease the gap between the true and empirical expectation of the energy and boosts the performance of the model.
WLD-Reg: A Data-dependent Within-layer Diversity Regularizer
Jan 03, 2023
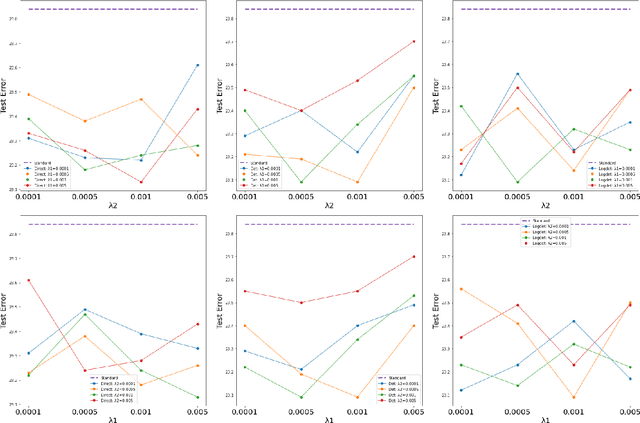

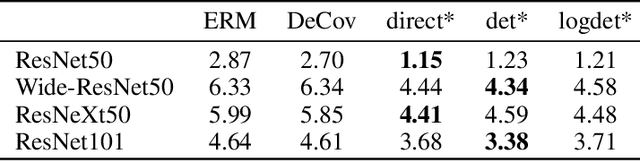
Neural networks are composed of multiple layers arranged in a hierarchical structure jointly trained with a gradient-based optimization, where the errors are back-propagated from the last layer back to the first one. At each optimization step, neurons at a given layer receive feedback from neurons belonging to higher layers of the hierarchy. In this paper, we propose to complement this traditional 'between-layer' feedback with additional 'within-layer' feedback to encourage the diversity of the activations within the same layer. To this end, we measure the pairwise similarity between the outputs of the neurons and use it to model the layer's overall diversity. We present an extensive empirical study confirming that the proposed approach enhances the performance of several state-of-the-art neural network models in multiple tasks. The code is publically available at \url{https://github.com/firasl/AAAI-23-WLD-Reg}