 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-BrownConrady: Prediction of Camera Calibration and Distortion Parameters Using Deep Learning and Synthetic Data
Jan 24, 2025



This research addresses the challenge of camera calibration and distortion parameter prediction from a single image using deep learning models. The main contributions of this work are: (1) demonstrating that a deep learning model, trained on a mix of real and synthetic images, can accurately predict camera and lens parameters from a single image, and (2) developing a comprehensive synthetic dataset using the AILiveSim simulation platform. This dataset includes variations in focal length and lens distortion parameters, providing a robust foundation for model training and testing. The training process predominantly relied on these synthetic images, complemented by a small subset of real images, to explore how well models trained on synthetic data can perform calibration tasks on real-world images. Traditional calibration methods require multiple images of a calibration object from various orientations, which is often not feasible due to the lack of such images in publicly available datasets. A deep learning network based on the ResNet architecture was trained on this synthetic dataset to predict camera calibration parameters following the Brown-Conrady lens model. The ResNet architecture, adapted for regression tasks, is capable of predicting continuous values essential for accurate camera calibration in applications such as autonomous driving, robotics, and augmented reality. Keywords: Camera calibration, distortion, synthetic data, deep learning, residual networks (ResNet), AILiveSim, horizontal field-of-view, principal point, Brown-Conrady Model.
Channel-wise Feature Decorrelation for Enhanced Learned Image Compression
Mar 16, 2024The emerging Learned Compression (LC) replaces the traditional codec modules with Deep Neural Networks (DNN), which are trained end-to-end for rate-distortion performance. This approach is considered as the future of image/video compression, and major efforts have been dedicated to improving its compression efficiency. However, most proposed works target compression efficiency by employing more complex DNNS, which contributes to higher computational complexity. Alternatively, this paper proposes to improve compression by fully exploiting the existing DNN capacity. To do so, the latent features are guided to learn a richer and more diverse set of features, which corresponds to better reconstruction. A channel-wise feature decorrelation loss is designed and is integrated into the LC optimization. Three strategies are proposed and evaluated, which optimize (1) the transformation network, (2) the context model, and (3) both networks. Experimental results on two established LC methods show that the proposed method improves the compression with a BD-Rate of up to 8.06%, with no added complexity. The proposed solution can be applied as a plug-and-play solution to optimize any similar LC method.
Joint End-to-End Image Compression and Denoising: Leveraging Contrastive Learning and Multi-Scale Self-ONNs
Feb 08, 2024



Noisy images are a challenge to image compression algorithms due to the inherent difficulty of compressing noise. As noise cannot easily be discerned from image details, such as high-frequency signals, its presence leads to extra bits needed for compression. Since the emerging learned image compression paradigm enables end-to-end optimization of codecs, recent efforts were made to integrate denoising into the compression model, relying on clean image features to guide denoising. However, these methods exhibit suboptimal performance under high noise levels, lacking the capability to generalize across diverse noise types. In this paper, we propose a novel method integrating a multi-scale denoiser comprising of Self Organizing Operational Neural Networks, for joint image compression and denoising. We employ contrastive learning to boost the network ability to differentiate noise from high frequency signal components, by emphasizing the correlation between noisy and clean counterparts. Experimental results demonstrate the effectiveness of the proposed method both in rate-distortion performance, and codec speed, outperforming the current state-of-the-art.
Pixel-Wise Color Constancy via Smoothness Techniques in Multi-Illuminant Scenes
Feb 05, 2024



Most scenes are illuminated by several light sources, where the traditional assumption of uniform illumination is invalid. This issue is ignored in most color constancy methods, primarily due to the complex spatial impact of multiple light sources on the image. Moreover, most existing multi-illuminant methods fail to preserve the smooth change of illumination, which stems from spatial dependencies in natural images. Motivated by this, we propose a novel multi-illuminant color constancy method, by learning pixel-wise illumination maps caused by multiple light sources. The proposed method enforces smoothness within neighboring pixels, by regularizing the training with the total variation loss. Moreover, a bilateral filter is provisioned further to enhance the natural appearance of the estimated images, while preserving the edges. Additionally, we propose a label-smoothing technique that enables the model to generalize well despite the uncertainties in ground truth. Quantitative and qualitative experiments demonstrate that the proposed method outperforms the state-of-the-art.
Perceptual Learned Image Compression via End-to-End JND-Based Optimization
Feb 05, 2024



Emerging Learned image Compression (LC) achieves significant improvements in coding efficiency by end-to-end training of neural networks for compression. An important benefit of this approach over traditional codecs is that any optimization criteria can be directly applied to the encoder-decoder networks during training. Perceptual optimization of LC to comply with the Human Visual System (HVS) is among such criteria, which has not been fully explored yet. This paper addresses this gap by proposing a novel framework to integrate Just Noticeable Distortion (JND) principles into LC. Leveraging existing JND datasets, three perceptual optimization methods are proposed to integrate JND into the LC training process: (1) Pixel-Wise JND Loss (PWL) prioritizes pixel-by-pixel fidelity in reproducing JND characteristics, (2) Image-Wise JND Loss (IWL) emphasizes on overall imperceptible degradation levels, and (3) Feature-Wise JND Loss (FWL) aligns the reconstructed image features with perceptually significant features. Experimental evaluations demonstrate the effectiveness of JND integration, highlighting improvements in rate-distortion performance and visual quality, compared to baseline methods. The proposed methods add no extra complexity after training.
Panoramic Image Inpainting With Gated Convolution And Contextual Reconstruction Loss
Feb 05, 2024



Deep learning-based methods have demonstrated encouraging results in tackling the task of panoramic image inpainting. However, it is challenging for existing methods to distinguish valid pixels from invalid pixels and find suitable references for corrupted areas, thus leading to artifacts in the inpainted results. In response to these challenges, we propose a panoramic image inpainting framework that consists of a Face Generator, a Cube Generator, a side branch, and two discriminators. We use the Cubemap Projection (CMP) format as network input. The generator employs gated convolutions to distinguish valid pixels from invalid ones, while a side branch is designed utilizing contextual reconstruction (CR) loss to guide the generators to find the most suitable reference patch for inpainting the missing region. The proposed method is compared with state-of-the-art (SOTA) methods on SUN360 Street View dataset in terms of PSNR and SSIM. Experimental results and ablation study demonstrate that the proposed method outperforms SOTA both quantitatively and qualitatively.
Efficient Bitrate Ladder Construction using Transfer Learning and Spatio-Temporal Features
Jan 06, 2024

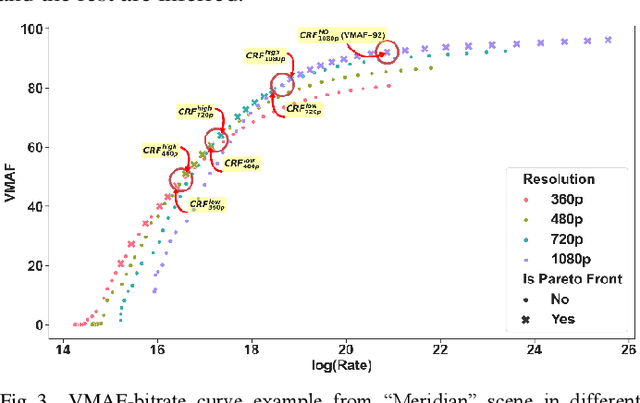
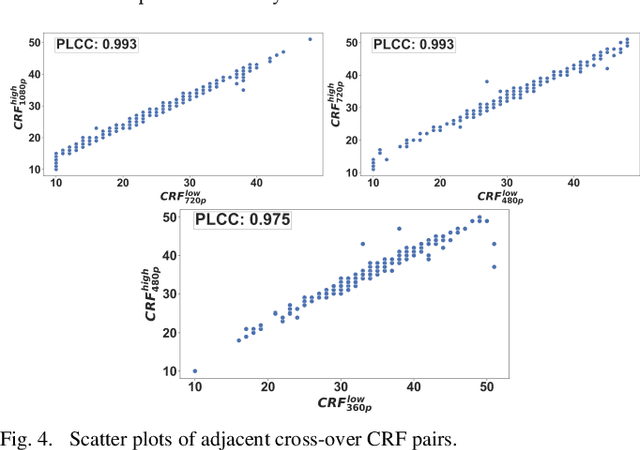
Providing high-quality video with efficient bitrate is a main challenge in video industry. The traditional one-size-fits-all scheme for bitrate ladders is inefficient and reaching the best content-aware decision computationally impractical due to extensive encodings required. To mitigate this, we propose a bitrate and complexity efficient bitrate ladder prediction method using transfer learning and spatio-temporal features. We propose: (1) using feature maps from well-known pre-trained DNNs to predict rate-quality behavior with limited training data; and (2) improving highest quality rung efficiency by predicting minimum bitrate for top quality and using it for the top rung. The method tested on 102 video scenes demonstrates 94.1% reduction in complexity versus brute-force at 1.71% BD-Rate expense. Additionally, transfer learning was thoroughly studied through four networks and ablation studies.
Comprehensive Complexity Assessment of Emerging Learned Image Compression on CPU and GPU
Dec 11, 2022



Learned Compression (LC) is the emerging technology for compressing image and video content, using deep neural networks. Despite being new, LC methods have already gained a compression efficiency comparable to state-of-the-art image compression, such as HEVC or even VVC. However, the existing solutions often require a huge computational complexity, which discourages their adoption in international standards or products. This paper provides a comprehensive complexity assessment of several notable methods, that shed light on the matter, and guide the future development of this field by presenting key findings. To do so, six existing methods have been evaluated for both encoding and decoding, on CPU and GPU platforms. Various aspects of complexity such as the overall complexity, share of each coding module, number of operations, number of parameters, most demanding GPU kernels, and memory requirements have been measured and compared on Kodak dataset. The reported results (1) quantify the complexity of LC methods, (2) fairly compare different methods, and (3) a major contribution of the work is identifying and quantifying the key factors affecting the complexity.
BLINC: Lightweight Bimodal Learning for Low-Complexity VVC Intra Coding
Jan 19, 2022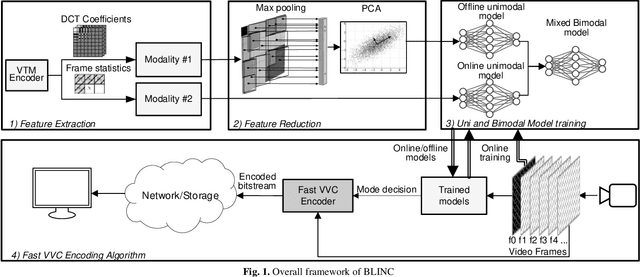

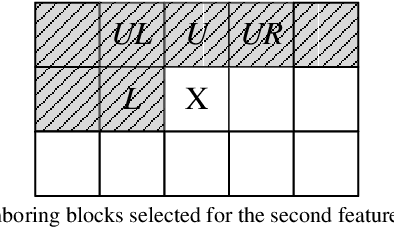
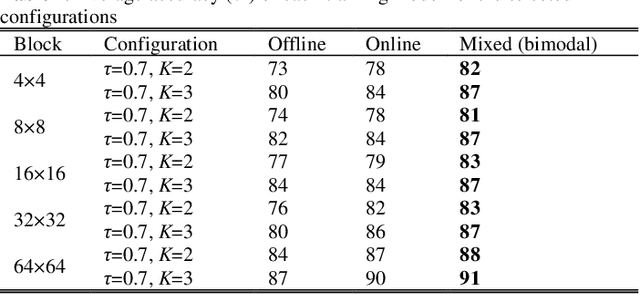
The latest video coding standard, Versatile Video Coding (VVC), achieves almost twice coding efficiency compared to its predecessor, the High Efficiency Video Coding (HEVC). However, achieving this efficiency (for intra coding) requires 31x computational complexity compared to HEVC, making it challenging for low power and real-time applications. This paper, proposes a novel machine learning approach that jointly and separately employs two modalities of features, to simplify the intra coding decision. First a set of features are extracted that use the existing DCT core of VVC, to assess the texture characteristics, and forms the first modality of data. This produces high quality features with almost no overhead. The distribution of intra modes at the neighboring blocks is also used to form the second modality of data, which provides statistical information about the frame. Second, a two-step feature reduction method is designed that reduces the size of feature set, such that a lightweight model with a limited number of parameters can be used to learn the intra mode decision task. Third, three separate training strategies are proposed (1) an offline training strategy using the first (single) modality of data, (2) an online training strategy that uses the second (single) modality, and (3) a mixed online-offline strategy that uses bimodal learning. Finally, a low-complexity encoding algorithms is proposed based on the proposed learning strategies. Extensive experimental results show that the proposed methods can reduce up to 24% of encoding time, with a negligible loss of coding efficiency. Moreover, it is demonstrated how a bimodal learning strategy can boost the performance of learning. Lastly, the proposed method has a very low computational overhead (0.2%), and uses existing components of a VVC encoder, which makes it much more practical compared to competing solutions.