 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriftXpress: Faster Drifting Models via Projected RKHS Fields
May 12, 2026Drifting Models have emerged as a new paradigm for one-step generative modeling, achieving strong image quality without iterative inference. The premise is to replace the iterative denoising process in diffusion models with a single evaluation of a generator. However, this creates a different trade-off: drifting reduces inference cost by moving much of the computation into training. We introduce DriftXpress, an accelerated formulation of drifting models based on projected RKHS fields. DriftXpress approximates the drifting kernel in a low-rank feature space. This preserves the attraction-repulsion structure of the original drifting field while reducing the cost of field evaluation. Across image-generation benchmarks, DriftXpress achieves comparable FID to standard drifting while reducing wall-clock training cost. These results show that the training-inference trade-off of drifting models can be pushed further without giving up their one-step inference advantage.
The Alignment Game: A Theory of Long-Horizon Alignment Through Recursive Curation
Nov 16, 2025In self-consuming generative models that train on their own outputs, alignment with user preferences becomes a recursive rather than one-time process. We provide the first formal foundation for analyzing the long-term effects of such recursive retraining on alignment. Under a two-stage curation mechanism based on the Bradley-Terry (BT) model, we model alignment as an interaction between two factions: the Model Owner, who filters which outputs should be learned by the model, and the Public User, who determines which outputs are ultimately shared and retained through interactions with the model. Our analysis reveals three structural convergence regimes depending on the degree of preference alignment: consensus collapse, compromise on shared optima, and asymmetric refinement. We prove a fundamental impossibility theorem: no recursive BT-based curation mechanism can simultaneously preserve diversity, ensure symmetric influence, and eliminate dependence on initialization. Framing the process as dynamic social choice, we show that alignment is not a static goal but an evolving equilibrium, shaped both by power asymmetries and path dependence.
SentenceKV: Efficient LLM Inference via Sentence-Level Semantic KV Caching
Apr 01, 2025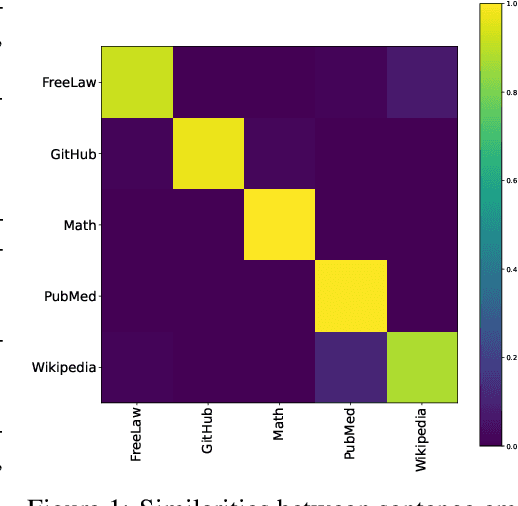
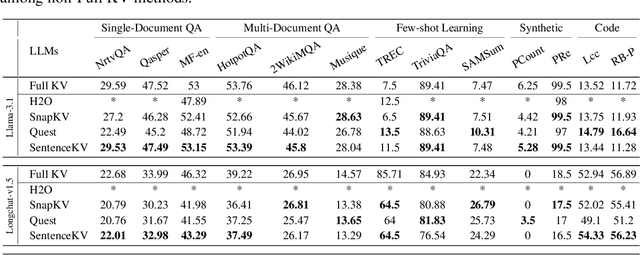
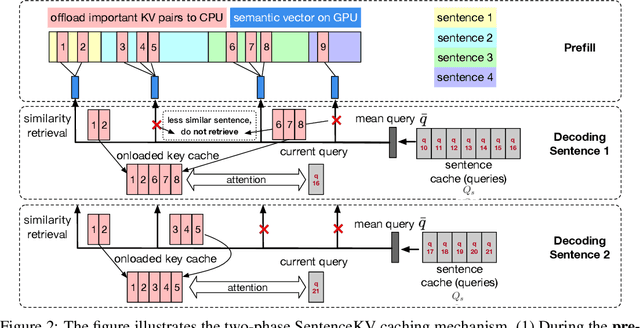
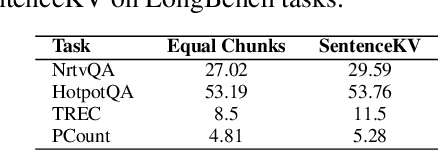
Large language models face significant computational and memory challenges when processing long contexts. During inference, efficient management of the key-value (KV) cache, which stores intermediate activations for autoregressive generation, is critical to reducing memory overhead and improving computational efficiency. Traditional token-level efficient KV caching methods overlook semantic information, treating tokens independently without considering their semantic relationships. Meanwhile, existing semantic-preserving KV cache management approaches often suffer from substantial memory usage and high time-to-first-token. To address these limitations, we propose SentenceKV, a novel sentence-level semantic KV caching approach designed to enhance inference efficiency while preserving semantic coherence. During prefilling, SentenceKV groups tokens based on sentence-level semantic similarity, compressing sentence representations into concise semantic vectors stored directly on the GPU, while individual KV pairs are offloaded to CPU. During decoding, SentenceKV generates tokens by selectively retrieving semantically relevant sentence-level KV entries, leveraging the semantic similarity between the prefilling-stage semantic vectors and decoding-stage queries. This ensures efficient and contextually accurate predictions, minimizing the loading of redundant or irrelevant data into GPU memory and significantly reducing memory overhead while maintaining stable inference latency, even for extremely long contexts. Extensive evaluations on benchmarks including PG-19, LongBench, and Needle-In-A-Haystack demonstrate that SentenceKV significantly outperforms state-of-the-art methods in both efficiency and memory usage, without compromising model accuracy.
Disentangled Structural and Featural Representation for Task-Agnostic Graph Valuation
Aug 22, 2024With the emergence of data marketplaces, the demand for methods to assess the value of data has increased significantly. While numerous techniques have been proposed for this purpose, none have specifically addressed graphs as the main data modality. Graphs are widely used across various fields, ranging from chemical molecules to social networks. In this study, we break down graphs into two main components: structural and featural, and we focus on evaluating data without relying on specific task-related metrics, making it applicable in practical scenarios where validation requirements may be lacking. We introduce a novel framework called blind message passing, which aligns the seller's and buyer's graphs using a shared node permutation based on graph matching. This allows us to utilize the graph Wasserstein distance to quantify the differences in the structural distribution of graph datasets, called the structural disparities. We then consider featural aspects of buyers' and sellers' graphs for data valuation and capture their statistical similarities and differences, referred to as relevance and diversity, respectively. Our approach ensures that buyers and sellers remain unaware of each other's datasets. Our experiments on real datasets demonstrate the effectiveness of our approach in capturing the relevance, diversity, and structural disparities of seller data for buyers, particularly in graph-based data valuation scenarios.
Efficient Bitrate Ladder Construction using Transfer Learning and Spatio-Temporal Features
Jan 06, 2024

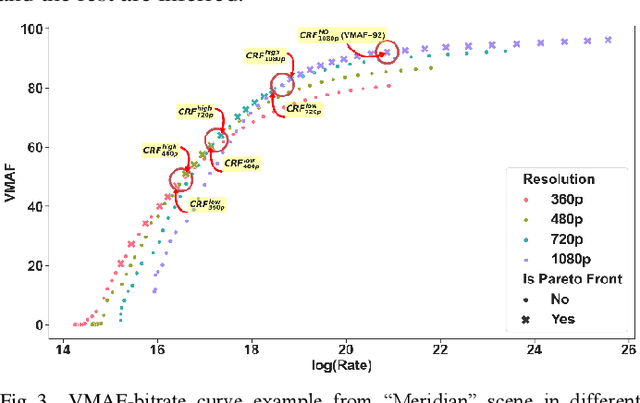
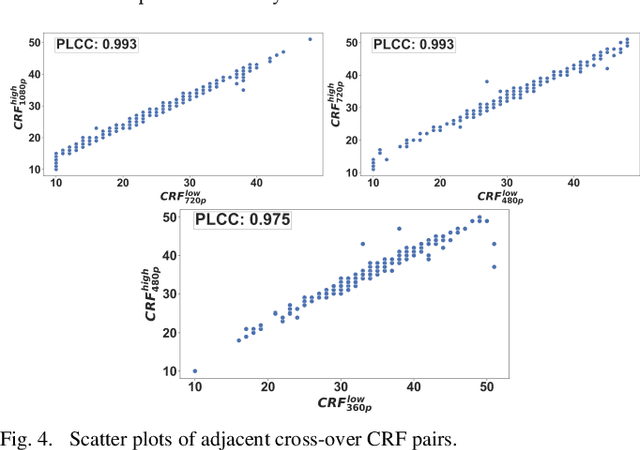
Providing high-quality video with efficient bitrate is a main challenge in video industry. The traditional one-size-fits-all scheme for bitrate ladders is inefficient and reaching the best content-aware decision computationally impractical due to extensive encodings required. To mitigate this, we propose a bitrate and complexity efficient bitrate ladder prediction method using transfer learning and spatio-temporal features. We propose: (1) using feature maps from well-known pre-trained DNNs to predict rate-quality behavior with limited training data; and (2) improving highest quality rung efficiency by predicting minimum bitrate for top quality and using it for the top rung. The method tested on 102 video scenes demonstrates 94.1% reduction in complexity versus brute-force at 1.71% BD-Rate expense. Additionally, transfer learning was thoroughly studied through four networks and ablation studies.