 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-OptBench: A Solver-Grounded Benchmark for Multimodal Optimization Modeling
May 12, 2026Optimization modeling translates real decision-making problems into mathematical optimization models and solver-executable implementations. Although language models are increasingly used to generate optimization formulations and solver code, existing benchmarks are almost entirely text-only. This omits many optimization-modeling tasks that arise in operational practice, where requirements are described in text but instance information is conveyed through visual artifacts such as tables, graphs, maps, schedules, and dashboards. We introduce multimodal optimization modeling, a benchmark setting in which models must construct both a mathematical formulation and executable solver code from a text-and-visual problem specification. To evaluate this setting, we develop a solver-grounded framework that generates structured optimization instances, verifies each with an exact solver, and builds both the model-facing inputs and hidden reference files from the same verified source. We instantiate the framework as MM-OptBench, a benchmark of 780 solver-verified instances spanning 6 optimization families, 26 subcategories, and 3 structural difficulty levels. We evaluate 9 multimodal large language models (MLLMs), including 6 frontier general-purpose models and 3 math-specialized models, with aggregate, family-level, difficulty-level, and failure-mode analyses. The results show that the task remains far from solved: the best two models reach 52.1% and 51.3% pass@1, while on average across the six general-purpose MLLMs, pass@1 is 43.4% on easy instances and 15.9% on hard instances. All three math-specialized MLLMs solve 0/780 instances. Failure attribution shows that errors arise both when extracting instance data from text and visuals and when turning extracted data into solver-correct formulations and code. MM-OptBench provides a testbed for solver-grounded, decision-oriented multimodal intelligence.
ZoomR: Memory Efficient Reasoning through Multi-Granularity Key Value Retrieval
Apr 13, 2026Large language models (LLMs) have shown great performance on complex reasoning tasks but often require generating long intermediate thoughts before reaching a final answer. During generation, LLMs rely on a key-value (KV) cache for autoregressive decoding. However, the memory footprint of the KV cache grows with output length. Prior work on KV cache optimization mostly focus on compressing the long input context, while retaining the full KV cache for decoding. For tasks requiring long output generation, this leads to increased computational and memory costs. In this paper, we introduce ZoomR, a novel approach that enables LLMs to adaptively compress verbose reasoning thoughts into summaries and uses a dynamic KV cache selection policy that leverages these summaries while also strategically "zooming in" on fine-grained details. By using summary keys as a coarse-grained index during decoding, ZoomR uses the query to retrieve details for only the most important thoughts. This hierarchical strategy significantly reduces memory usage by avoiding full-cache attention at each step. Experiments across math and reasoning tasks show that our approach achieves competitive performance compared to baselines, while reducing inference memory requirements by more than $4\times$. These results demonstrate that a multi-granularity KV selection enables more memory efficient decoding, especially for long output generation.
ReViSQL: Achieving Human-Level Text-to-SQL
Mar 20, 2026Translating natural language to SQL (Text-to-SQL) is a critical challenge in both database research and data analytics applications. Recent efforts have focused on enhancing SQL reasoning by developing large language models and AI agents that decompose Text-to-SQL tasks into manually designed, step-by-step pipelines. However, despite these extensive architectural engineering efforts, a significant gap remains: even state-of-the-art (SOTA) AI agents have not yet achieved the human-level accuracy on the BIRD benchmark. In this paper, we show that closing this gap does not require further architectural complexity, but rather clean training data to improve SQL reasoning of the underlying models. We introduce ReViSQL, a streamlined framework that achieves human-level accuracy on BIRD for the first time. Instead of complex AI agents, ReViSQL leverages reinforcement learning with verifiable rewards (RLVR) on BIRD-Verified, a dataset we curated comprising 2.5k verified Text-to-SQL instances based on the BIRD Train set. To construct BIRD-Verified, we design a data correction and verification workflow involving SQL experts. We identified and corrected data errors in 61.1% of a subset of BIRD Train. By training on BIRD-Verified, we show that improving data quality alone boosts the single-generation accuracy by 8.2-13.9% under the same RLVR algorithm. To further enhance performance, ReViSQL performs inference-time scaling via execution-based reconciliation and majority voting. Empirically, we demonstrate the superiority of our framework with two model scales: ReViSQL-235B-A22B and ReViSQL-30B-A3B. On an expert-verified BIRD Mini-Dev set, ReViSQL-235B-A22B achieves 93.2% execution accuracy, exceeding the proxy human-level accuracy (92.96%) and outperforming the prior open-source SOTA method by 9.8%. Our lightweight ReViSQL-30B-A3B matches the prior SOTA at a 7.5$\times$ lower per-query cost.
Noisy Data is Destructive to Reinforcement Learning with Verifiable Rewards
Mar 17, 2026Reinforcement learning with verifiable rewards (RLVR) has driven recent capability advances of large language models across various domains. Recent studies suggest that improved RLVR algorithms allow models to learn effectively from incorrect annotations, achieving performance comparable to learning from clean data. In this work, we show that these findings are invalid because the claimed 100% noisy training data is "contaminated" with clean data. After rectifying the dataset with a rigorous re-verification pipeline, we demonstrate that noise is destructive to RLVR. We show that existing RLVR algorithm improvements fail to mitigate the impact of noise, achieving similar performance to that of the basic GRPO. Furthermore, we find that the model trained on truly incorrect annotations performs 8-10% worse than the model trained on clean data across mathematical reasoning benchmarks. Finally, we show that these findings hold for real-world noise in Text2SQL tasks, where training on real-world, human annotation errors cause 5-12% lower accuracy than clean data. Our results show that current RLVR methods cannot yet compensate for poor data quality. High-quality data remains essential.
ManCAR: Manifold-Constrained Latent Reasoning with Adaptive Test-Time Computation for Sequential Recommendation
Feb 23, 2026Sequential recommendation increasingly employs latent multi-step reasoning to enhance test-time computation. Despite empirical gains, existing approaches largely drive intermediate reasoning states via target-dominant objectives without imposing explicit feasibility constraints. This results in latent drift, where reasoning trajectories deviate into implausible regions. We argue that effective recommendation reasoning should instead be viewed as navigation on a collaborative manifold rather than free-form latent refinement. To this end, we propose ManCAR (Manifold-Constrained Adaptive Reasoning), a principled framework that grounds reasoning within the topology of a global interaction graph. ManCAR constructs a local intent prior from the collaborative neighborhood of a user's recent actions, represented as a distribution over the item simplex. During training, the model progressively aligns its latent predictive distribution with this prior, forcing the reasoning trajectory to remain within the valid manifold. At test time, reasoning proceeds adaptively until the predictive distribution stabilizes, avoiding over-refinement. We provide a variational interpretation of ManCAR to theoretically validate its drift-prevention and adaptive test-time stopping mechanisms. Experiments on seven benchmarks demonstrate that ManCAR consistently outperforms state-of-the-art baselines, achieving up to a 46.88% relative improvement w.r.t. NDCG@10. Our code is available at https://github.com/FuCongResearchSquad/ManCAR.
Rethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs
Feb 02, 2026Semantic ID (SID)-based recommendation is a promising paradigm for scaling sequential recommender systems, but existing methods largely follow a semantic-centric pipeline: item embeddings are learned from foundation models and discretized using generic quantization schemes. This design is misaligned with generative recommendation objectives: semantic embeddings are weakly coupled with collaborative prediction, and generic quantization is inefficient at reducing sequential uncertainty for autoregressive modeling. To address these, we propose ReSID, a recommendation-native, principled SID framework that rethinks representation learning and quantization from the perspective of information preservation and sequential predictability, without relying on LLMs. ReSID consists of two components: (i) Field-Aware Masked Auto-Encoding (FAMAE), which learns predictive-sufficient item representations from structured features, and (ii) Globally Aligned Orthogonal Quantization (GAOQ), which produces compact and predictable SID sequences by jointly reducing semantic ambiguity and prefix-conditional uncertainty. Theoretical analysis and extensive experiments across ten datasets show the effectiveness of ReSID. ReSID consistently outperforms strong sequential and SID-based generative baselines by an average of over 10%, while reducing tokenization cost by up to 122x. Code is available at https://github.com/FuCongResearchSquad/ReSID.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Pervasive Annotation Errors Break Text-to-SQL Benchmarks and Leaderboards
Jan 13, 2026Researchers have proposed numerous text-to-SQL techniques to streamline data analytics and accelerate the development of database-driven applications. To compare these techniques and select the best one for deployment, the community depends on public benchmarks and their leaderboards. Since these benchmarks heavily rely on human annotations during question construction and answer evaluation, the validity of the annotations is crucial. In this paper, we conduct an empirical study that (i) benchmarks annotation error rates for two widely used text-to-SQL benchmarks, BIRD and Spider 2.0-Snow, and (ii) corrects a subset of the BIRD development (Dev) set to measure the impact of annotation errors on text-to-SQL agent performance and leaderboard rankings. Through expert analysis, we show that BIRD Mini-Dev and Spider 2.0-Snow have error rates of 52.8% and 62.8%, respectively. We re-evaluate all 16 open-source agents from the BIRD leaderboard on both the original and the corrected BIRD Dev subsets. We show that performance changes range from -7% to 31% (in relative terms) and rank changes range from $-9$ to $+9$ positions. We further assess whether these impacts generalize to the full BIRD Dev set. We find that the rankings of agents on the uncorrected subset correlate strongly with those on the full Dev set (Spearman's $r_s$=0.85, $p$=3.26e-5), whereas they correlate weakly with those on the corrected subset (Spearman's $r_s$=0.32, $p$=0.23). These findings show that annotation errors can significantly distort reported performance and rankings, potentially misguiding research directions or deployment choices. Our code and data are available at https://github.com/uiuc-kang-lab/text_to_sql_benchmarks.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025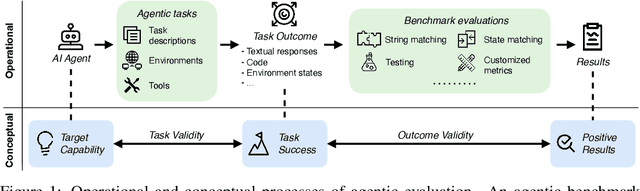
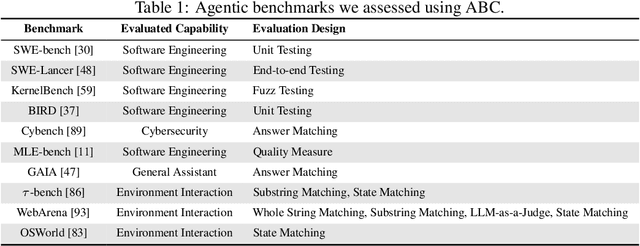
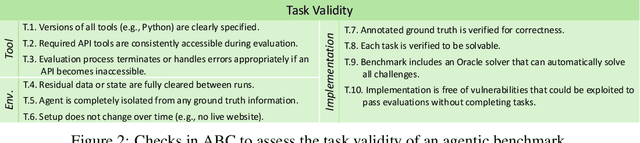
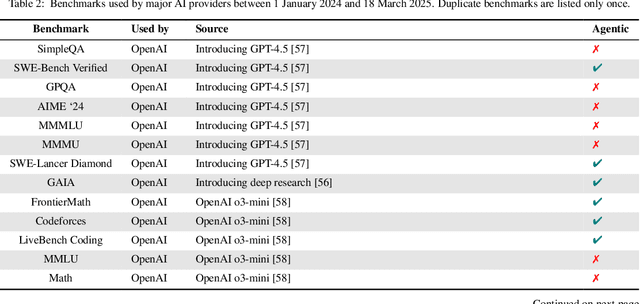
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.