 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDora: QoE-Aware Hybrid Parallelism for Distributed Edge AI
Dec 09, 2025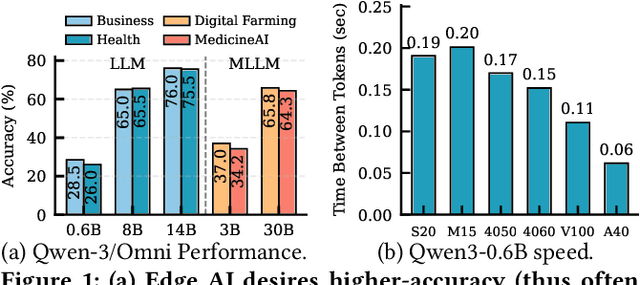
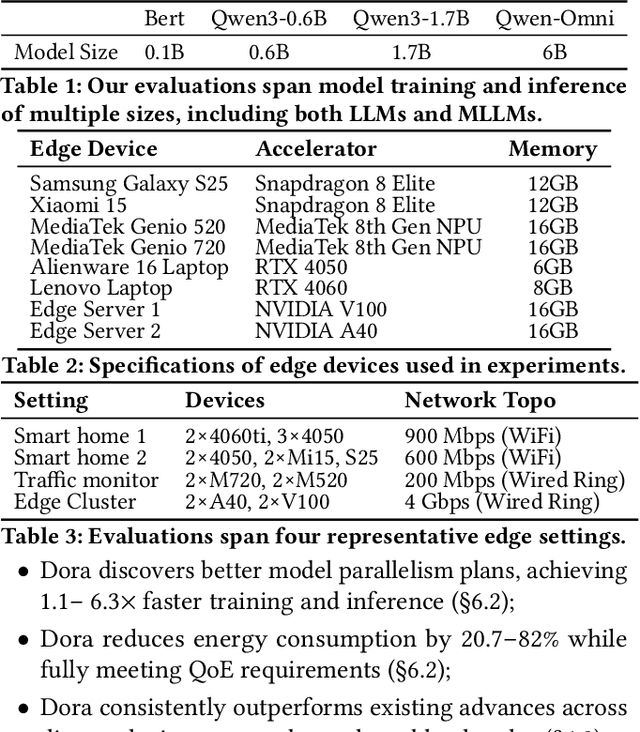
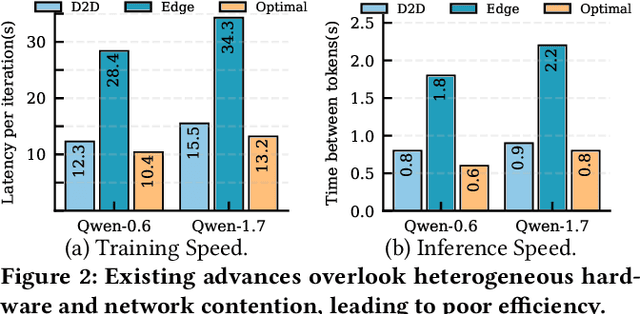
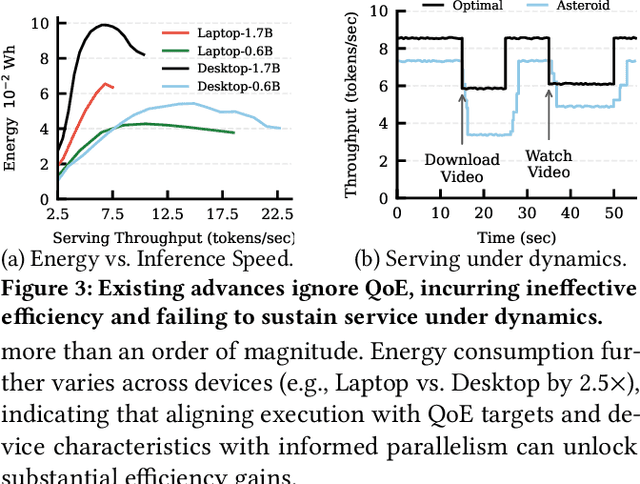
With the proliferation of edge AI applications, satisfying user quality of experience (QoE) requirements, such as model inference latency, has become a first class objective, as these models operate in resource constrained settings and directly interact with users. Yet, modern AI models routinely exceed the resource capacity of individual devices, necessitating distributed execution across heterogeneous devices over variable and contention prone networks. Existing planners for hybrid (e.g., data and pipeline) parallelism largely optimize for throughput or device utilization, overlooking QoE, leading to severe resource inefficiency (e.g., unnecessary energy drain) or QoE violations under runtime dynamics. We present Dora, a framework for QoE aware hybrid parallelism in distributed edge AI training and inference. Dora jointly optimizes heterogeneous computation, contention prone networks, and multi dimensional QoE objectives via three key mechanisms: (i) a heterogeneity aware model partitioner that determines and assigns model partitions across devices, forming a compact set of QoE compliant plans; (ii) a contention aware network scheduler that further refines these candidate plans by maximizing compute communication overlap; and (iii) a runtime adapter that adaptively composes multiple plans to maximize global efficiency while respecting overall QoEs. Across representative edge deployments, including smart homes, traffic analytics, and small edge clusters, Dora achieves 1.1--6.3 times faster execution and, alternatively, reduces energy consumption by 21--82 percent, all while maintaining QoE under runtime dynamics.
Inv-Entropy: A Fully Probabilistic Framework for Uncertainty Quantification in Language Models
Jun 11, 2025Large language models (LLMs) have transformed natural language processing, but their reliable deployment requires effective uncertainty quantification (UQ). Existing UQ methods are often heuristic and lack a probabilistic foundation. This paper begins by providing a theoretical justification for the role of perturbations in UQ for LLMs. We then introduce a dual random walk perspective, modeling input-output pairs as two Markov chains with transition probabilities defined by semantic similarity. Building on this, we propose a fully probabilistic framework based on an inverse model, which quantifies uncertainty by evaluating the diversity of the input space conditioned on a given output through systematic perturbations. Within this framework, we define a new uncertainty measure, Inv-Entropy. A key strength of our framework is its flexibility: it supports various definitions of uncertainty measures, embeddings, perturbation strategies, and similarity metrics. We also propose GAAP, a perturbation algorithm based on genetic algorithms, which enhances the diversity of sampled inputs. In addition, we introduce a new evaluation metric, Temperature Sensitivity of Uncertainty (TSU), which directly assesses uncertainty without relying on correctness as a proxy. Extensive experiments demonstrate that Inv-Entropy outperforms existing semantic UQ methods. The code to reproduce the results can be found at https://github.com/UMDataScienceLab/Uncertainty-Quantification-for-LLMs.
Single-agent or Multi-agent Systems? Why Not Both?
May 23, 2025Multi-agent systems (MAS) decompose complex tasks and delegate subtasks to different large language model (LLM) agents and tools. Prior studies have reported the superior accuracy performance of MAS across diverse domains, enabled by long-horizon context tracking and error correction through role-specific agents. However, the design and deployment of MAS incur higher complexity and runtime cost compared to single-agent systems (SAS). Meanwhile, frontier LLMs, such as OpenAI-o3 and Gemini-2.5-Pro, have rapidly advanced in long-context reasoning, memory retention, and tool usage, mitigating many limitations that originally motivated MAS designs. In this paper, we conduct an extensive empirical study comparing MAS and SAS across various popular agentic applications. We find that the benefits of MAS over SAS diminish as LLM capabilities improve, and we propose efficient mechanisms to pinpoint the error-prone agent in MAS. Furthermore, the performance discrepancy between MAS and SAS motivates our design of a hybrid agentic paradigm, request cascading between MAS and SAS, to improve both efficiency and capability. Our design improves accuracy by 1.1-12% while reducing deployment costs by up to 20% across various agentic applications.
Tempo: Application-aware LLM Serving with Mixed SLO Requirements
Apr 24, 2025



The integration of Large Language Models (LLMs) into diverse applications, ranging from interactive chatbots and cloud AIOps to intelligent agents, has introduced a wide spectrum of Service Level Objectives (SLOs) for responsiveness. These workloads include latency-sensitive requests focused on per-token latency in streaming chat, throughput-intensive requests that require rapid full responses to invoke tools, and collective requests with dynamic dependencies arising from self-reflection or agent-based reasoning. This workload diversity, amplified by unpredictable request information such as response lengths and runtime dependencies, makes existing schedulers inadequate even within their design envelopes. In this paper, we define service gain as the useful service delivered by completing requests. We observe that as SLO directly reflects the actual performance needs of requests, completing a request much faster than its SLO (e.g., deadline) yields limited additional service gain. Based on this insight, we introduce Tempo, the first systematic SLO-aware scheduler designed to maximize service gain across diverse LLM workloads. Tempo allocates just enough serving bandwidth to meet each SLO, maximizing residual capacity for others best-effort workloads. Instead of assuming request information or none at all, it adopts a hybrid scheduling strategy: using quantile-based response upper bounds and dependency-graph matching for conservative initial estimates, prioritizing requests by service gain density, and refining decisions online as generation progresses. Our evaluation across diverse workloads, including chat, reasoning, and agentic pipelines, shows that Tempo improves end-to-end service gain by up to 8.3$\times$ and achieves up to 10.3$\times$ SLO goodput compared to state-of-the-art designs
Circinus: Efficient Query Planner for Compound ML Serving
Apr 23, 2025



The rise of compound AI serving -- integrating multiple operators in a pipeline that may span edge and cloud tiers -- enables end-user applications such as autonomous driving, generative AI-powered meeting companions, and immersive gaming. Achieving high service goodput -- i.e., meeting service level objectives (SLOs) for pipeline latency, accuracy, and costs -- requires effective planning of operator placement, configuration, and resource allocation across infrastructure tiers. However, the diverse SLO requirements, varying edge capabilities, and high query volumes create an enormous planning search space, rendering current solutions fundamentally limited for real-time serving and cost-efficient deployments. This paper presents Circinus, an SLO-aware query planner for large-scale compound AI workloads. Circinus novelly decomposes multi-query planning and multi-dimensional SLO objectives while preserving global decision quality. By exploiting plan similarities within and across queries, it significantly reduces search steps. It further improves per-step efficiency with a precision-aware plan profiler that incrementally profiles and strategically applies early stopping based on imprecise estimates of plan performance. At scale, Circinus selects query-plan combinations to maximize global SLO goodput. Evaluations in real-world settings show that Circinus improves service goodput by 3.2-5.0$\times$, accelerates query planning by 4.2-5.8$\times$, achieving query response in seconds, while reducing deployment costs by 3.2-4.0$\times$ over state of the arts even in their intended single-tier deployments.
DiSCo: Device-Server Collaborative LLM-Based Text Streaming Services
Feb 17, 2025The rapid rise of large language models (LLMs) in text streaming services has introduced significant cost and Quality of Experience (QoE) challenges in serving millions of daily requests, especially in meeting Time-To-First-Token (TTFT) and Time-Between-Token (TBT) requirements for real-time interactions. Our real-world measurements show that both server-based and on-device deployments struggle to meet diverse QoE demands: server deployments face high costs and last-hop issues (e.g., Internet latency and dynamics), while on-device LLM inference is constrained by resources. We introduce DiSCo, a device-server cooperative scheduler designed to optimize users' QoE by adaptively routing requests and migrating response generation between endpoints while maintaining cost constraints. DiSCo employs cost-aware scheduling, leveraging the predictable speed of on-device LLM inference with the flexible capacity of server-based inference to dispatch requests on the fly, while introducing a token-level migration mechanism to ensure consistent token delivery during migration. Evaluations on real-world workloads -- including commercial services like OpenAI GPT and DeepSeek, and open-source deployments such as LLaMA3 -- show that DiSCo can improve users' QoE by reducing tail TTFT (11-52\%) and mean TTFT (6-78\%) across different model-device configurations, while dramatically reducing serving costs by up to 84\% through its migration mechanism while maintaining comparable QoE levels.
FedTrans: Efficient Federated Learning via Multi-Model Transformation
Apr 25, 2024Federated learning (FL) aims to train machine learning (ML) models across potentially millions of edge client devices. Yet, training and customizing models for FL clients is notoriously challenging due to the heterogeneity of client data, device capabilities, and the massive scale of clients, making individualized model exploration prohibitively expensive. State-of-the-art FL solutions personalize a globally trained model or concurrently train multiple models, but they often incur suboptimal model accuracy and huge training costs. In this paper, we introduce FedTrans, a multi-model FL training framework that automatically produces and trains high-accuracy, hardware-compatible models for individual clients at scale. FedTrans begins with a basic global model, identifies accuracy bottlenecks in model architectures during training, and then employs model transformation to derive new models for heterogeneous clients on the fly. It judiciously assigns models to individual clients while performing soft aggregation on multi-model updates to minimize total training costs. Our evaluations using realistic settings show that FedTrans improves individual client model accuracy by 14% - 72% while slashing training costs by 1.6X - 20X over state-of-the-art solutions.
Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services
Apr 25, 2024



The advent of large language models (LLMs) has transformed text-based services, enabling capabilities ranging from real-time translation to AI-driven chatbots. However, existing serving systems primarily focus on optimizing server-side aggregate metrics like token generation throughput, ignoring individual user experience with streamed text. As a result, under high and/or bursty load, a significant number of users can receive unfavorable service quality or poor Quality-of-Experience (QoE). In this paper, we first formally define QoE of text streaming services, where text is delivered incrementally and interactively to users, by considering the end-to-end token delivery process throughout the entire interaction with the user. Thereafter, we propose Andes, a QoE-aware serving system that enhances user experience for LLM-enabled text streaming services. At its core, Andes strategically allocates contended GPU resources among multiple requests over time to optimize their QoE. Our evaluations demonstrate that, compared to the state-of-the-art LLM serving systems like vLLM, Andes improves the average QoE by up to 3.2$\times$ under high request rate, or alternatively, it attains up to 1.6$\times$ higher request rate while preserving high QoE.
Learn To be Efficient: Build Structured Sparsity in Large Language Models
Feb 13, 2024



Large Language Models (LLMs) have achieved remarkable success with their billion-level parameters, yet they incur high inference overheads. The emergence of activation sparsity in LLMs provides a natural approach to reduce this cost by involving only parts of the parameters for inference. Existing methods only focus on utilizing this naturally formed activation sparsity, overlooking the potential for further amplifying this inherent sparsity. In this paper, we hypothesize that LLMs can learn to be efficient by achieving more structured activation sparsity. To achieve this, we introduce a novel algorithm, Learn-To-be-Efficient (LTE), designed to train efficiency-aware LLMs to learn to activate fewer neurons and achieve a better trade-off between sparsity and performance. Furthermore, unlike SOTA MoEfication methods, which mainly focus on ReLU-based models, LTE can also be applied to LLMs like GPT and LLaMA with soft activation functions. We evaluate LTE on four models and eleven datasets. The experiments show that LTE achieves a better trade-off between sparsity and task performance. For instance, LTE with LLaMA provides a 1.83x-2.59x FLOPs speed-up on language generation tasks, outperforming the state-of-the-art methods.
Fine-Grained Embedding Dimension Optimization During Training for Recommender Systems
Jan 09, 2024



Huge embedding tables in modern Deep Learning Recommender Models (DLRM) require prohibitively large memory during training and inference. Aiming to reduce the memory footprint of training, this paper proposes FIne-grained In-Training Embedding Dimension optimization (FIITED). Given the observation that embedding vectors are not equally important, FIITED adjusts the dimension of each individual embedding vector continuously during training, assigning longer dimensions to more important embeddings while adapting to dynamic changes in data. A novel embedding storage system based on virtually-hashed physically-indexed hash tables is designed to efficiently implement the embedding dimension adjustment and effectively enable memory saving. Experiments on two industry models show that FIITED is able to reduce the size of embeddings by more than 65% while maintaining the trained model's quality, saving significantly more memory than a state-of-the-art in-training embedding pruning method. On public click-through rate prediction datasets, FIITED is able to prune up to 93.75%-99.75% embeddings without significant accuracy loss.