 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Embedding Dimension Optimization During Training for Recommender Systems
Jan 09, 2024



Huge embedding tables in modern Deep Learning Recommender Models (DLRM) require prohibitively large memory during training and inference. Aiming to reduce the memory footprint of training, this paper proposes FIne-grained In-Training Embedding Dimension optimization (FIITED). Given the observation that embedding vectors are not equally important, FIITED adjusts the dimension of each individual embedding vector continuously during training, assigning longer dimensions to more important embeddings while adapting to dynamic changes in data. A novel embedding storage system based on virtually-hashed physically-indexed hash tables is designed to efficiently implement the embedding dimension adjustment and effectively enable memory saving. Experiments on two industry models show that FIITED is able to reduce the size of embeddings by more than 65% while maintaining the trained model's quality, saving significantly more memory than a state-of-the-art in-training embedding pruning method. On public click-through rate prediction datasets, FIITED is able to prune up to 93.75%-99.75% embeddings without significant accuracy loss.
DASNet: Dynamic Activation Sparsity for Neural Network Efficiency Improvement
Sep 13, 2019
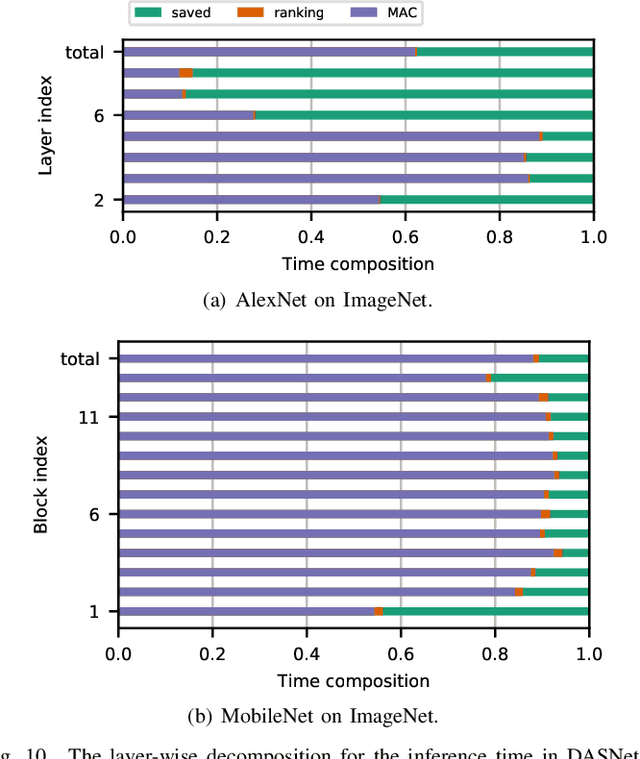
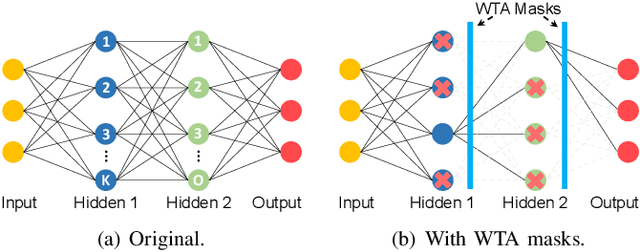
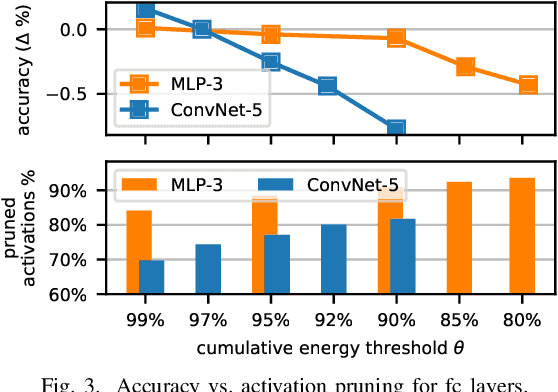
To improve the execution speed and efficiency of neural networks in embedded systems, it is crucial to decrease the model size and computational complexity. In addition to conventional compression techniques, e.g., weight pruning and quantization, removing unimportant activations can reduce the amount of data communication and the computation cost. Unlike weight parameters, the pattern of activations is directly related to input data and thereby changes dynamically. To regulate the dynamic activation sparsity (DAS), in this work, we propose a generic low-cost approach based on winners-take-all (WTA) dropout technique. The network enhanced by the proposed WTA dropout, namely \textit{DASNet}, features structured activation sparsity with an improved sparsity level. Compared to the static feature map pruning methods, DASNets provide better computation cost reduction. The WTA technique can be easily applied in deep neural networks without incurring additional training variables. More importantly, DASNet can be seamlessly integrated with other compression techniques, such as weight pruning and quantization, without compromising on accuracy. Our experiments on various networks and datasets present significant run-time speedups with negligible accuracy loss.
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array
Jan 07, 2019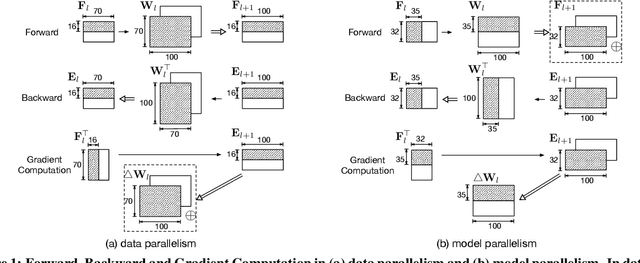
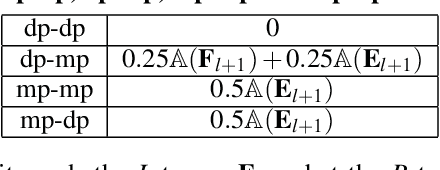
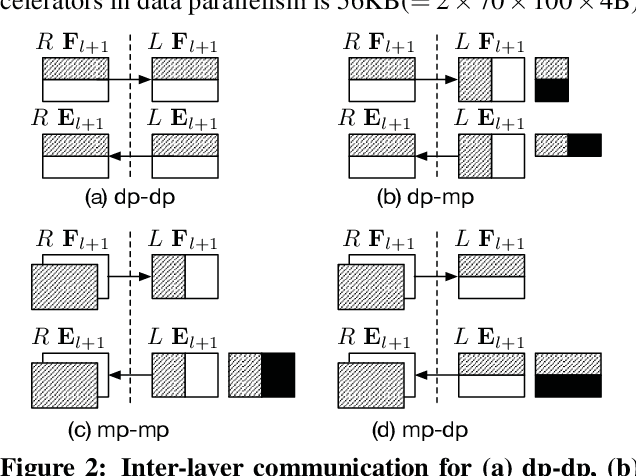
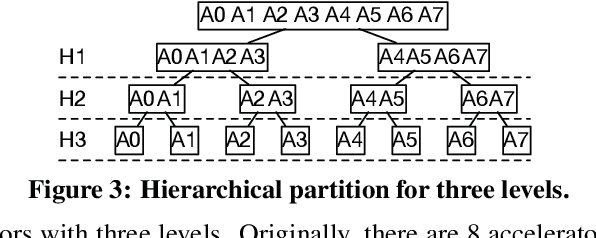
With the rise of artificial intelligence in recent years, Deep Neural Networks (DNNs) have been widely used in many domains. To achieve high performance and energy efficiency, hardware acceleration (especially inference) of DNNs is intensively studied both in academia and industry. However, we still face two challenges: large DNN models and datasets, which incur frequent off-chip memory accesses; and the training of DNNs, which is not well-explored in recent accelerator designs. To truly provide high throughput and energy efficient acceleration for the training of deep and large models, we inevitably need to use multiple accelerators to explore the coarse-grain parallelism, compared to the fine-grain parallelism inside a layer considered in most of the existing architectures. It poses the key research question to seek the best organization of computation and dataflow among accelerators. In this paper, we propose a solution HyPar to determine layer-wise parallelism for deep neural network training with an array of DNN accelerators. HyPar partitions the feature map tensors (input and output), the kernel tensors, the gradient tensors, and the error tensors for the DNN accelerators. A partition constitutes the choice of parallelism for weighted layers. The optimization target is to search a partition that minimizes the total communication during training a complete DNN. To solve this problem, we propose a communication model to explain the source and amount of communications. Then, we use a hierarchical layer-wise dynamic programming method to search for the partition for each layer.