 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTR: Neural Token Reconstruction for Scene Token Bottleneck in End-to-End Driving
May 29, 2026Recent perception-free end-to-end (E2E) autonomous driving methods bypass explicit perception outputs by compressing dense image patch tokens into compact scene tokens for downstream trajectory generation and scoring. While these scene tokens form a compact visual bottleneck for the planner, they receive supervision solely from the planning objective, providing limited constraints on the encoded visual information. To address this limitation, we introduce Neural Token Reconstruction (NTR), a representation learning framework to directly constrain the compact scene-token bottleneck in perception-free driving. NTR introduces a self-distillation masked latent reconstruction objective that reconstructs masked patch-level latent features using only compact scene tokens as reconstruction memory. This forces reconstruction gradients to pass exclusively through the scene-token bottleneck, encouraging scene tokens to preserve richer and less redundant visual representations for planning. We further introduce semantic priors derived from foundation-model annotations as a weak semantic interface biasing reconstruction targets toward driving-related structures without introducing explicit perception heads. All auxiliary reconstruction components are removed at inference time, leaving the deployed planner unchanged. NTR achieves state-of-the-art performance on three public autonomous driving benchmarks, including 8.0461 RFS on Waymo E2E and 94.1 PDMS / 90.9 EPDMS on NavSim1&2. The learned scene tokens exhibit lower pairwise redundancy and higher effective rank, indicating that effective bottleneck supervision improves both compact visual representation learning and planning performance.
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
Jun 18, 2023



Vectorized high-definition (HD) map is essential for autonomous driving, providing detailed and precise environmental information for advanced perception and planning. However, current map vectorization methods often exhibit deviations, and the existing evaluation metric for map vectorization lacks sufficient sensitivity to detect these deviations. To address these limitations, we propose integrating the philosophy of rasterization into map vectorization. Specifically, we introduce a new rasterization-based evaluation metric, which has superior sensitivity and is better suited to real-world autonomous driving scenarios. Furthermore, we propose MapVR (Map Vectorization via Rasterization), a novel framework that applies differentiable rasterization to vectorized outputs and then performs precise and geometry-aware supervision on rasterized HD maps. Notably, MapVR designs tailored rasterization strategies for various geometric shapes, enabling effective adaptation to a wide range of map elements. Experiments show that incorporating rasterization into map vectorization greatly enhances performance with no extra computational cost during inference, leading to more accurate map perception and ultimately promoting safer autonomous driving.
DASNet: Dynamic Activation Sparsity for Neural Network Efficiency Improvement
Sep 13, 2019
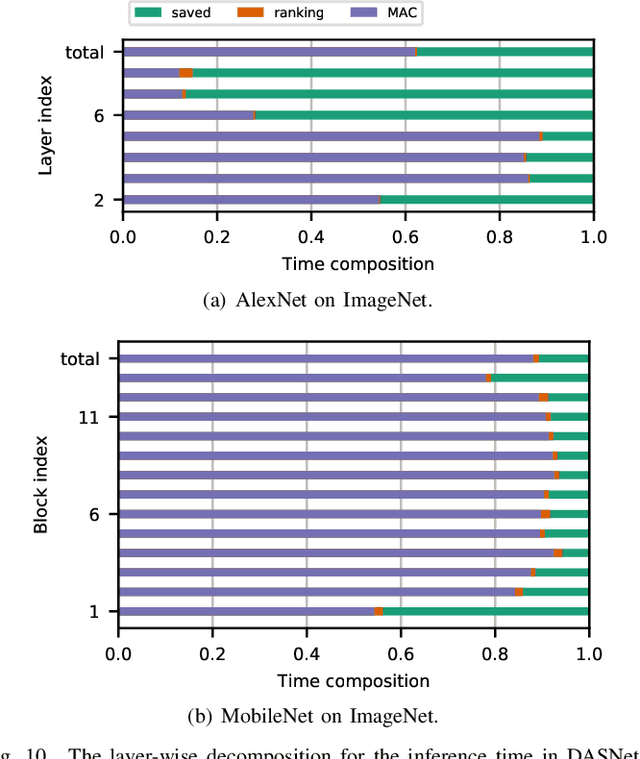
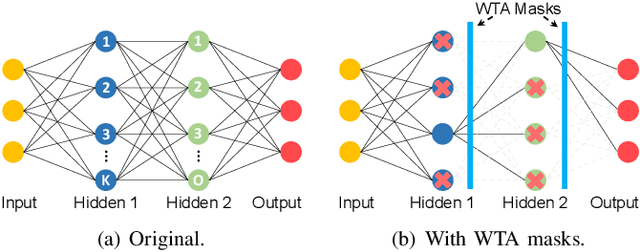
To improve the execution speed and efficiency of neural networks in embedded systems, it is crucial to decrease the model size and computational complexity. In addition to conventional compression techniques, e.g., weight pruning and quantization, removing unimportant activations can reduce the amount of data communication and the computation cost. Unlike weight parameters, the pattern of activations is directly related to input data and thereby changes dynamically. To regulate the dynamic activation sparsity (DAS), in this work, we propose a generic low-cost approach based on winners-take-all (WTA) dropout technique. The network enhanced by the proposed WTA dropout, namely \textit{DASNet}, features structured activation sparsity with an improved sparsity level. Compared to the static feature map pruning methods, DASNets provide better computation cost reduction. The WTA technique can be easily applied in deep neural networks without incurring additional training variables. More importantly, DASNet can be seamlessly integrated with other compression techniques, such as weight pruning and quantization, without compromising on accuracy. Our experiments on various networks and datasets present significant run-time speedups with negligible accuracy loss.
Feedback Learning for Improving the Robustness of Neural Networks
Sep 12, 2019
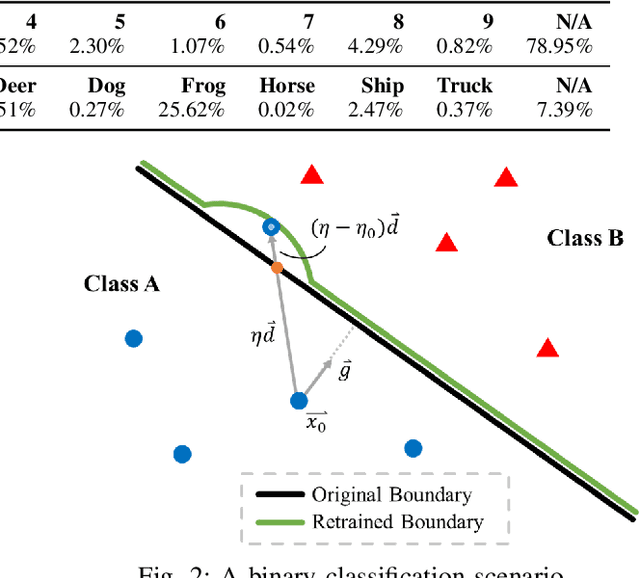
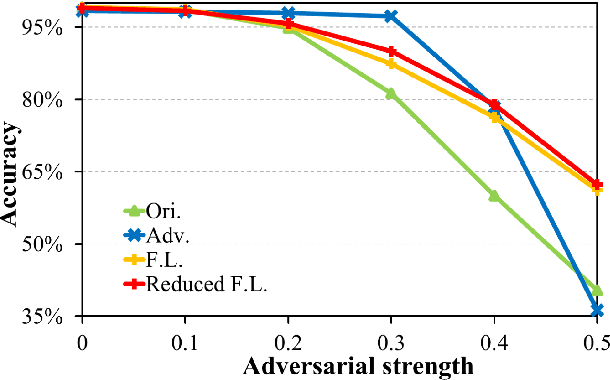
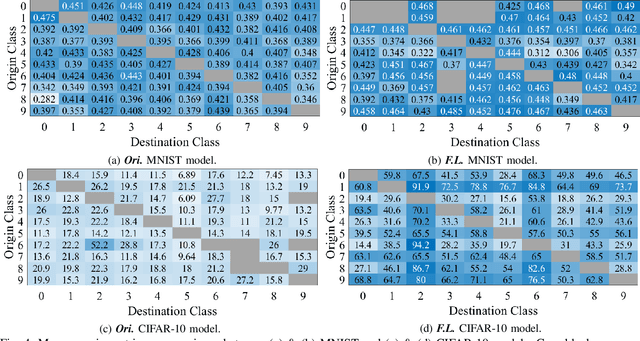
Recent research studies revealed that neural networks are vulnerable to adversarial attacks. State-of-the-art defensive techniques add various adversarial examples in training to improve models' adversarial robustness. However, these methods are not universal and can't defend unknown or non-adversarial evasion attacks. In this paper, we analyze the model robustness in the decision space. A feedback learning method is then proposed, to understand how well a model learns and to facilitate the retraining process of remedying the defects. The evaluations according to a set of distance-based criteria show that our method can significantly improve models' accuracy and robustness against different types of evasion attacks. Moreover, we observe the existence of inter-class inequality and propose to compensate it by changing the proportions of examples generated in different classes.
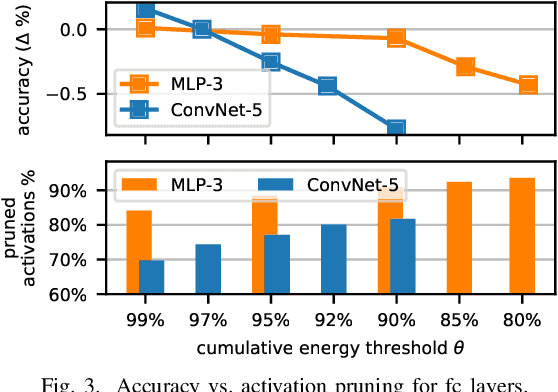
Joint Pruning on Activations and Weights for Efficient Neural Networks
Jun 19, 2019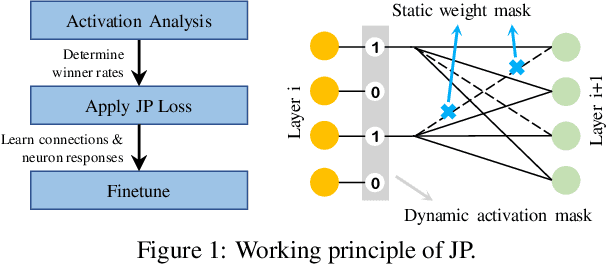
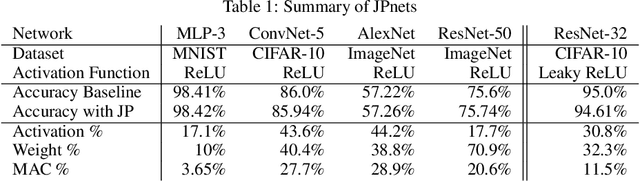
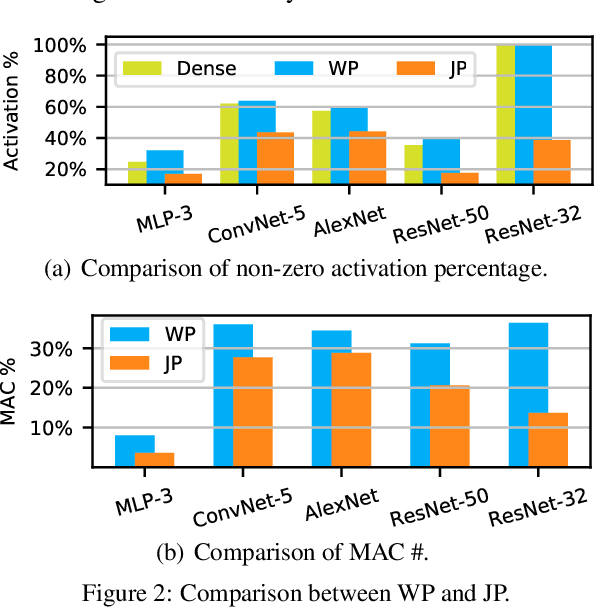
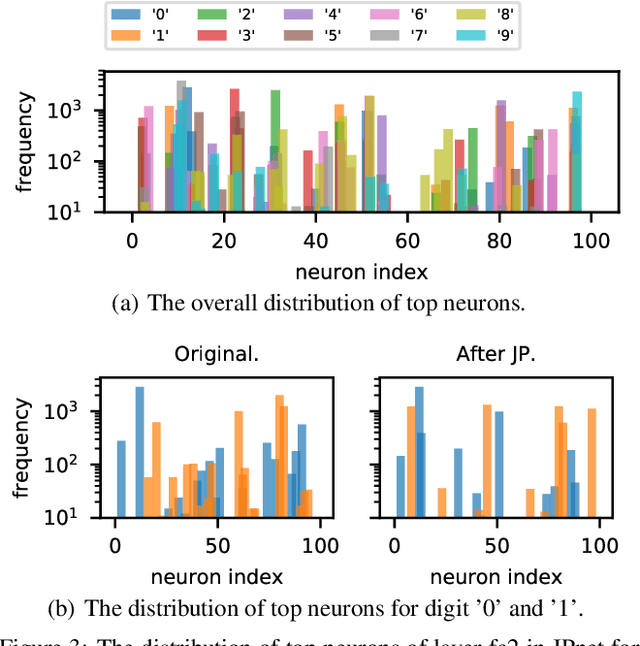
With rapidly scaling up of deep neural networks (DNNs), extensive research studies on network model compression such as weight pruning have been performed for improving deployment efficiency. This work aims to advance the compression beyond the weights to neuron activations. We propose an end-to-end Joint Pruning (JP) technique which integrates the activation pruning with the weight pruning. By distinguishing and taking on the different significance of neuron responses and connections during learning, the generated network, namely JPnet, optimizes the sparsity of activations and weights for improving execution efficiency. To our best knowledge, JP is the first technique that simultaneously explores the redundancy in both weights and activations. The derived deep sparsification in the JPnet reveals more optimizing potentialities for the existing DNN accelerators dedicated for sparse matrix operations. The effectiveness of JP technique is thoroughly evaluated through various network models with different activation functions and on different datasets. With $<0.4\%$ degradation on testing accuracy, a JPnet can save $71.1\% \sim 96.35\%$ of computation cost, compared to the original dense models with up to $5.8\times$ and $10\times$ reductions in activation and weight numbers, respectively. Compared to state-of-the-art weight pruning technique, JPnet can further reduce the computation cost $1.2\times \sim 2.7\times$.
Facial Feature Tracking under Varying Facial Expressions and Face Poses based on Restricted Boltzmann Machines
Sep 18, 2017



Facial feature tracking is an active area in computer vision due to its relevance to many applications. It is a nontrivial task, since faces may have varying facial expressions, poses or occlusions. In this paper, we address this problem by proposing a face shape prior model that is constructed based on the Restricted Boltzmann Machines (RBM) and their variants. Specifically, we first construct a model based on Deep Belief Networks to capture the face shape variations due to varying facial expressions for near-frontal view. To handle pose variations, the frontal face shape prior model is incorporated into a 3-way RBM model that could capture the relationship between frontal face shapes and non-frontal face shapes. Finally, we introduce methods to systematically combine the face shape prior models with image measurements of facial feature points. Experiments on benchmark databases show that with the proposed method, facial feature points can be tracked robustly and accurately even if faces have significant facial expressions and poses.