 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Pruning on Activations and Weights for Efficient Neural Networks
Paper and Code
Jun 19, 2019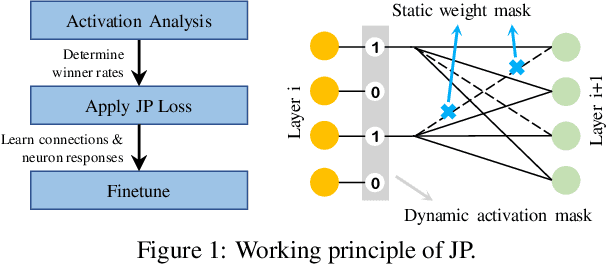
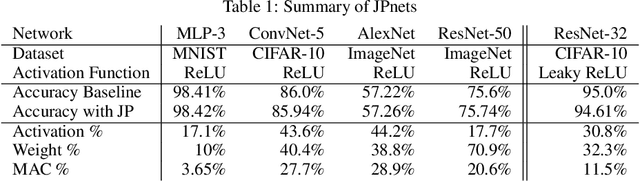
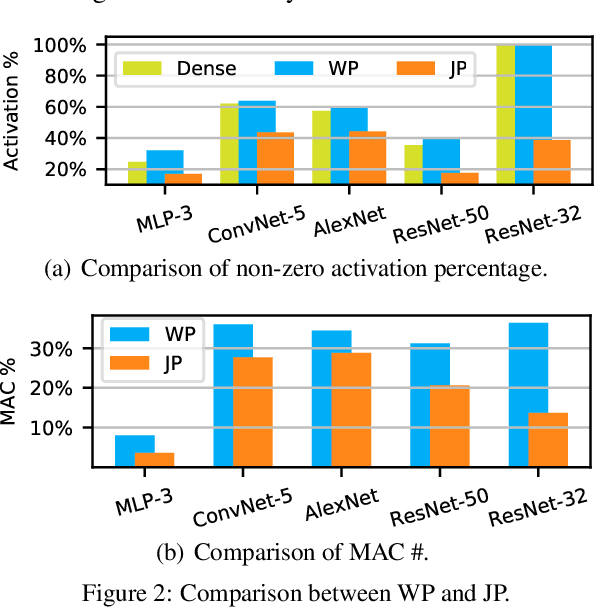
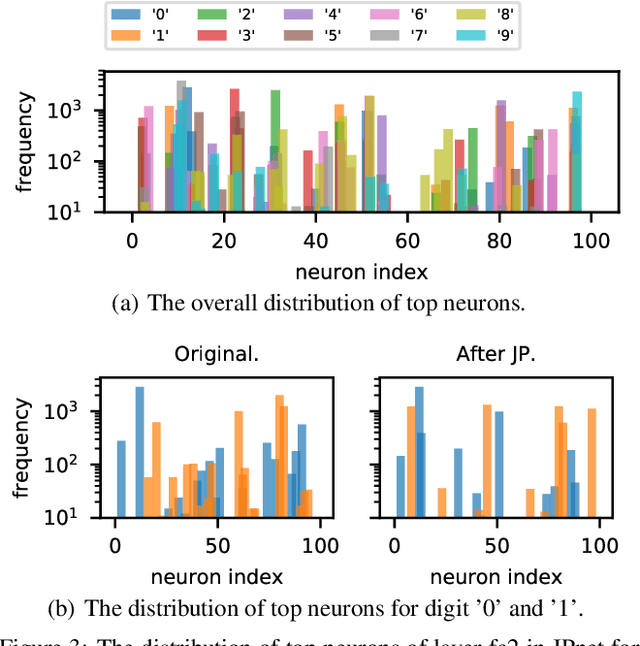
With rapidly scaling up of deep neural networks (DNNs), extensive research studies on network model compression such as weight pruning have been performed for improving deployment efficiency. This work aims to advance the compression beyond the weights to neuron activations. We propose an end-to-end Joint Pruning (JP) technique which integrates the activation pruning with the weight pruning. By distinguishing and taking on the different significance of neuron responses and connections during learning, the generated network, namely JPnet, optimizes the sparsity of activations and weights for improving execution efficiency. To our best knowledge, JP is the first technique that simultaneously explores the redundancy in both weights and activations. The derived deep sparsification in the JPnet reveals more optimizing potentialities for the existing DNN accelerators dedicated for sparse matrix operations. The effectiveness of JP technique is thoroughly evaluated through various network models with different activation functions and on different datasets. With $<0.4\%$ degradation on testing accuracy, a JPnet can save $71.1\% \sim 96.35\%$ of computation cost, compared to the original dense models with up to $5.8\times$ and $10\times$ reductions in activation and weight numbers, respectively. Compared to state-of-the-art weight pruning technique, JPnet can further reduce the computation cost $1.2\times \sim 2.7\times$.