 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Vision-Language Models are Smart Compressors for Long Video Understanding
Apr 09, 2026Adapting Multimodal Large Language Models (MLLMs) for hour-long videos is bottlenecked by context limits. Dense visual streams saturate token budgets and exacerbate the lost-in-the-middle phenomenon. Existing heuristics, like sparse sampling or uniform pooling, blindly sacrifice fidelity by discarding decisive moments and wasting bandwidth on irrelevant backgrounds. We propose Tempo, an efficient query-aware framework compressing long videos for downstream understanding. Tempo leverages a Small Vision-Language Model (SVLM) as a local temporal compressor, casting token reduction as an early cross-modal distillation process to generate compact, intent-aligned representations in a single forward pass. To enforce strict budgets without breaking causality, we introduce Adaptive Token Allocation (ATA). Exploiting the SVLM's zero-shot relevance prior and semantic front-loading, ATA acts as a training-free $O(1)$ dynamic router. It allocates dense bandwidth to query-critical segments while compressing redundancies into minimal temporal anchors to maintain the global storyline. Extensive experiments show our 6B architecture achieves state-of-the-art performance with aggressive dynamic compression (0.5-16 tokens/frame). On the extreme-long LVBench (4101s), Tempo scores 52.3 under a strict 8K visual budget, outperforming GPT-4o and Gemini 1.5 Pro. Scaling to 2048 frames reaches 53.7. Crucially, Tempo compresses hour-long videos substantially below theoretical limits, proving true long-form video understanding relies on intent-driven efficiency rather than greedily padded context windows.
Rethinking Model Efficiency: Multi-Agent Inference with Large Models
Apr 06, 2026Most vision-language models (VLMs) apply a large language model (LLM) as the decoder, where the response tokens are generated sequentially through autoregression. Therefore, the number of output tokens can be the bottleneck of the end-to-end latency. However, different models may require vastly different numbers of output tokens to achieve comparable performance. In this work, we conduct a comprehensive analysis of the latency across different components of VLMs on simulated data. The experiment shows that a large model with fewer output tokens can be more efficient than a small model with a long output sequence. The empirical study on diverse real-world benchmarks confirms the observation that a large model can achieve better or comparable performance as a small model with significantly fewer output tokens. To leverage the efficiency of large models, we propose a multi-agent inference framework that keeps large models with short responses but transfers the key reasoning tokens from the small model when necessary. The comparison on benchmark tasks demonstrates that by reusing the reasoning tokens from small models, it can help approach the performance of a large model with its own reasoning, which confirms the effectiveness of our proposal.
Efficient Universal Perception Encoder
Mar 23, 2026Running AI models on smart edge devices can unlock versatile user experiences, but presents challenges due to limited compute and the need to handle multiple tasks simultaneously. This requires a vision encoder with small size but powerful and versatile representations. We present our method, Efficient Universal Perception Encoder (EUPE), which offers both inference efficiency and universally good representations for diverse downstream tasks. We achieve this by distilling from multiple domain-expert foundation vision encoders. Unlike previous agglomerative methods that directly scale down from multiple teachers to an efficient encoder, we demonstrate the importance of first scaling up to a large proxy teacher and then scaling down from this single teacher. Experiments show that EUPE achieves on-par or better performance than individual domain experts of the same size on diverse task domains and also outperforms previous agglomerative encoders. We will release the full family of EUPE models and the code to foster future research.
dTRPO: Trajectory Reduction in Policy Optimization of Diffusion Large Language Models
Mar 19, 2026Diffusion Large Language Models (dLLMs) introduce a new paradigm for language generation, which in turn presents new challenges for aligning them with human preferences. In this work, we aim to improve the policy optimization for dLLMs by reducing the cost of the trajectory probability calculation, thereby enabling scaled-up offline policy training. We prove that: (i) under reference policy regularization, the probability ratio of the newly unmasked tokens is an unbiased estimate of that of intermediate diffusion states, and (ii) the probability of the full trajectory can be effectively estimated with a single forward pass of a re-masked final state. By integrating these two trajectory reduction strategies into a policy optimization objective, we propose Trajectory Reduction Policy Optimization (dTRPO). We evaluate dTRPO on 7B dLLMs across instruction-following and reasoning benchmarks. Results show that it substantially improves the core performance of state-of-the-art dLLMs, achieving gains of up to 9.6% on STEM tasks, up to 4.3% on coding tasks, and up to 3.0% on instruction-following tasks. Moreover, dTRPO exhibits strong training efficiency due to its offline, single-forward nature, and achieves improved generation efficiency through high-quality outputs.
T2S-Bench & Structure-of-Thought: Benchmarking and Prompting Comprehensive Text-to-Structure Reasoning
Mar 04, 2026Think about how human handles complex reading tasks: marking key points, inferring their relationships, and structuring information to guide understanding and responses. Likewise, can a large language model benefit from text structure to enhance text-processing performance? To explore it, in this work, we first introduce Structure of Thought (SoT), a prompting technique that explicitly guides models to construct intermediate text structures, consistently boosting performance across eight tasks and three model families. Building upon this insight, we present T2S-Bench, the first benchmark designed to evaluate and improve text-to-structure capabilities of models. T2S-Bench includes 1.8K samples across 6 scientific domains and 32 structural types, rigorously constructed to ensure accuracy, fairness, and quality. Evaluation on 45 mainstream models reveals substantial improvement potential: the average accuracy on the multi-hop reasoning task is only 52.1%, and even the most advanced model achieves 58.1% node accuracy in end-to-end extraction. Furthermore, on Qwen2.5-7B-Instruct, SoT alone yields an average +5.7% improvement across eight diverse text-processing tasks, and fine-tuning on T2S-Bench further increases this gain to +8.6%. These results highlight the value of explicit text structuring and the complementary contributions of SoT and T2S-Bench. Dataset and eval code have been released at https://t2s-bench.github.io/T2S-Bench-Page/.
When should I search more: Adaptive Complex Query Optimization with Reinforcement Learning
Jan 29, 2026Query optimization is a crucial component for the efficacy of Retrieval-Augmented Generation (RAG) systems. While reinforcement learning (RL)-based agentic and reasoning methods have recently emerged as a promising direction on query optimization, most existing approaches focus on the expansion and abstraction of a single query. However, complex user queries are prevalent in real-world scenarios, often requiring multiple parallel and sequential search strategies to handle disambiguation and decomposition. Directly applying RL to these complex cases introduces significant hurdles. Determining the optimal number of sub-queries and effectively re-ranking and merging retrieved documents vastly expands the search space and complicates reward design, frequently leading to training instability. To address these challenges, we propose a novel RL framework called Adaptive Complex Query Optimization (ACQO). Our framework is designed to adaptively determine when and how to expand the search process. It features two core components: an Adaptive Query Reformulation (AQR) module that dynamically decides when to decompose a query into multiple sub-queries, and a Rank-Score Fusion (RSF) module that ensures robust result aggregation and provides stable reward signals for the learning agent. To mitigate training instabilities, we adopt a Curriculum Reinforcement Learning (CRL) approach, which stabilizes the training process by progressively introducing more challenging queries through a two-stage strategy. Our comprehensive experiments demonstrate that ACQO achieves state-of-the-art performance on three complex query benchmarks, significantly outperforming established baselines. The framework also showcases improved computational efficiency and broad compatibility with different retrieval architectures, establishing it as a powerful and generalizable solution for next-generation RAG systems.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
ASPD: Unlocking Adaptive Serial-Parallel Decoding by Exploring Intrinsic Parallelism in LLMs
Aug 12, 2025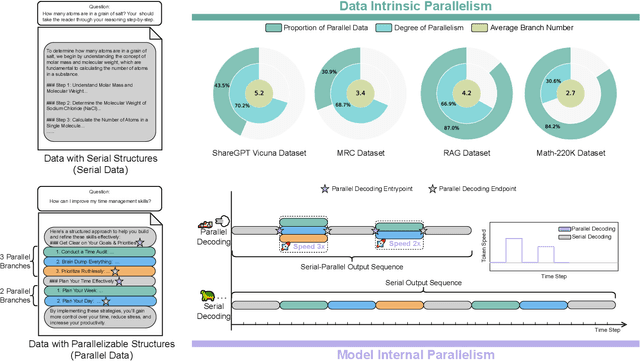
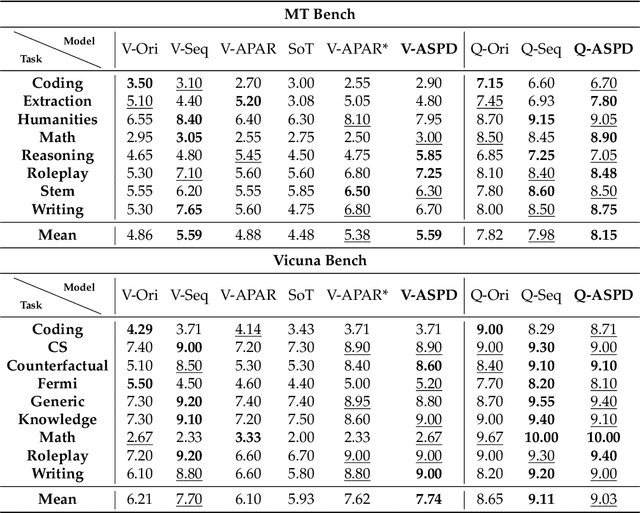
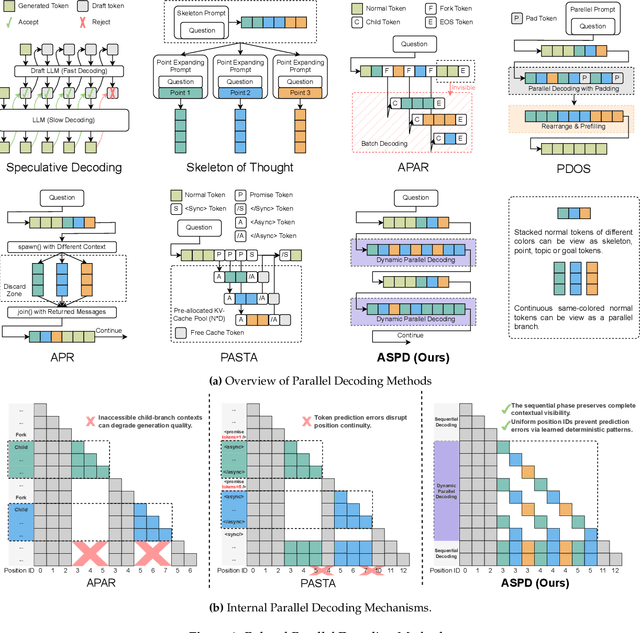
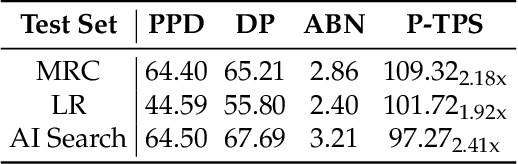
The increasing scale and complexity of large language models (LLMs) pose significant inference latency challenges, primarily due to their autoregressive decoding paradigm characterized by the sequential nature of next-token prediction. By re-examining the outputs of autoregressive models, we observed that some segments exhibit parallelizable structures, which we term intrinsic parallelism. Decoding each parallelizable branch simultaneously (i.e. parallel decoding) can significantly improve the overall inference speed of LLMs. In this paper, we propose an Adaptive Serial-Parallel Decoding (ASPD), which addresses two core challenges: automated construction of parallelizable data and efficient parallel decoding mechanism. More specifically, we introduce a non-invasive pipeline that automatically extracts and validates parallelizable structures from the responses of autoregressive models. To empower efficient adaptive serial-parallel decoding, we implement a Hybrid Decoding Engine which enables seamless transitions between serial and parallel decoding modes while maintaining a reusable KV cache, maximizing computational efficiency. Extensive evaluations across General Tasks, Retrieval-Augmented Generation, Mathematical Reasoning, demonstrate that ASPD achieves unprecedented performance in both effectiveness and efficiency. Notably, on Vicuna Bench, our method achieves up to 3.19x speedup (1.85x on average) while maintaining response quality within 1% difference compared to autoregressive models, realizing significant acceleration without compromising generation quality. Our framework sets a groundbreaking benchmark for efficient LLM parallel inference, paving the way for its deployment in latency-sensitive applications such as AI-powered customer service bots and answer retrieval engines.