 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023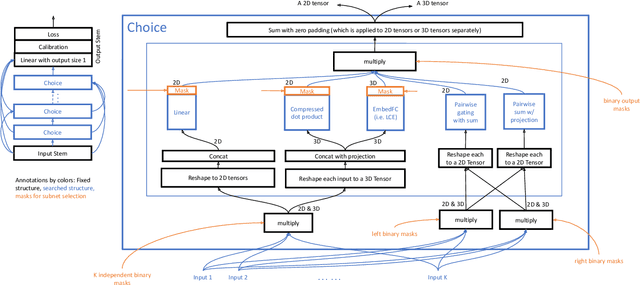
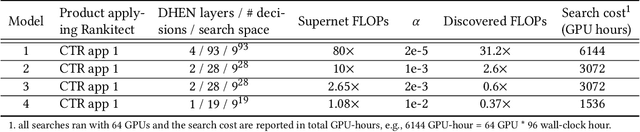
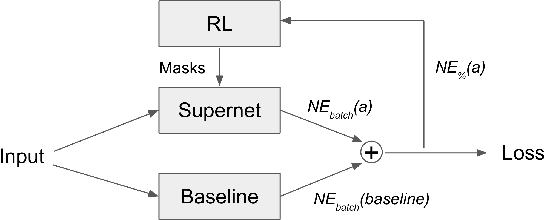
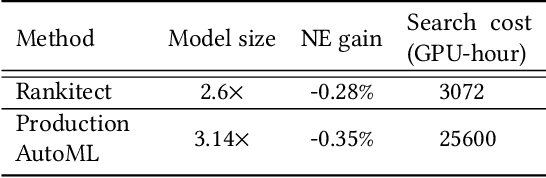
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
DistDNAS: Search Efficient Feature Interactions within 2 Hours
Nov 01, 2023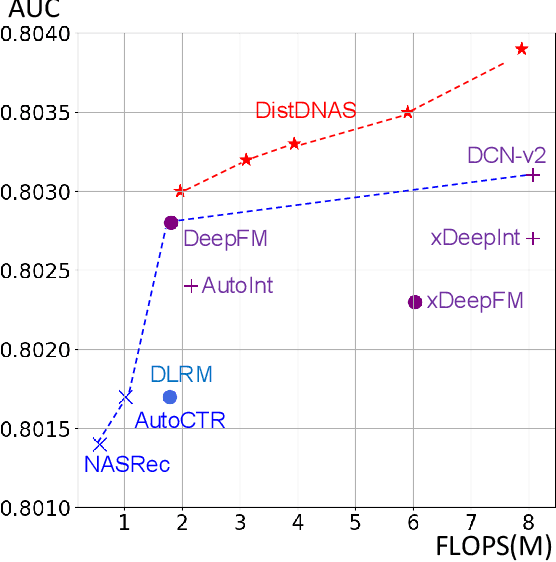

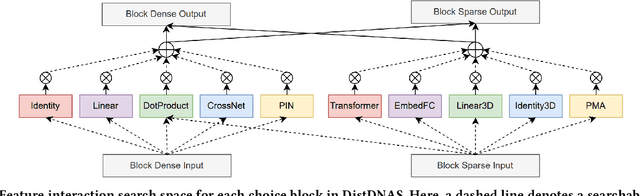

Search efficiency and serving efficiency are two major axes in building feature interactions and expediting the model development process in recommender systems. On large-scale benchmarks, searching for the optimal feature interaction design requires extensive cost due to the sequential workflow on the large volume of data. In addition, fusing interactions of various sources, orders, and mathematical operations introduces potential conflicts and additional redundancy toward recommender models, leading to sub-optimal trade-offs in performance and serving cost. In this paper, we present DistDNAS as a neat solution to brew swift and efficient feature interaction design. DistDNAS proposes a supernet to incorporate interaction modules of varying orders and types as a search space. To optimize search efficiency, DistDNAS distributes the search and aggregates the choice of optimal interaction modules on varying data dates, achieving over 25x speed-up and reducing search cost from 2 days to 2 hours. To optimize serving efficiency, DistDNAS introduces a differentiable cost-aware loss to penalize the selection of redundant interaction modules, enhancing the efficiency of discovered feature interactions in serving. We extensively evaluate the best models crafted by DistDNAS on a 1TB Criteo Terabyte dataset. Experimental evaluations demonstrate 0.001 AUC improvement and 60% FLOPs saving over current state-of-the-art CTR models.
mvn2vec: Preservation and Collaboration in Multi-View Network Embedding
Oct 30, 2018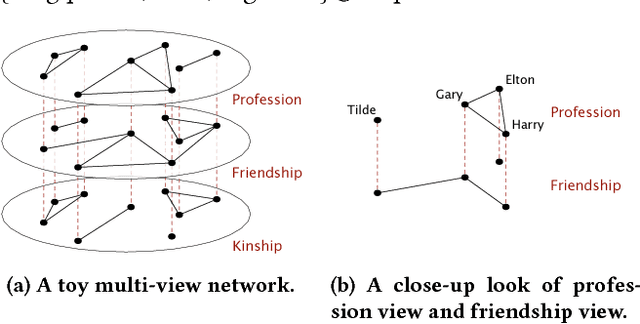

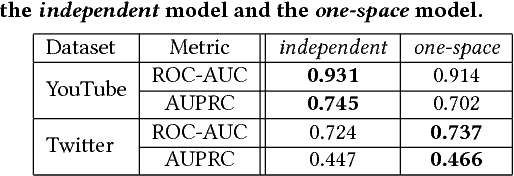
Multi-view networks are ubiquitous in real-world applications. In order to extract knowledge or business value, it is of interest to transform such networks into representations that are easily machine-actionable. Meanwhile, network embedding has emerged as an effective approach to generate distributed network representations. Therefore, we are motivated to study the problem of multi-view network embedding, with a focus on the characteristics that are specific and important in embedding this type of networks. In our practice of embedding real-world multi-view networks, we identify two such characteristics, which we refer to as preservation and collaboration. We then explore the feasibility of achieving better embedding quality by simultaneously modeling preservation and collaboration, and propose the mvn2vec algorithms. With experiments on a series of synthetic datasets, an internal Snapchat dataset, and two public datasets, we further confirm the presence and importance of preservation and collaboration. These experiments also demonstrate that better embedding can be obtained by simultaneously modeling the two characteristics, while not over-complicating the model or requiring additional supervision.
Collective Decision Dynamics in Group Evacuation: Behavioral Experiment and Machine Learning Models
Dec 01, 2016


Identifying factors that affect human decision making and quantifying their influence remain essential and challenging tasks for the design and implementation of social and technological communication systems. We report results of a behavioral experiment involving decision making in the face of an impending natural disaster. In a controlled laboratory setting, we characterize individual and group evacuation decision making influenced by several key factors, including the likelihood of the disaster, available shelter capacity, group size, and group decision protocol. Our results show that success in individual decision making is not a strong predictor of group performance. We use an artificial neural network trained on the collective behavior of subjects to predict individual and group outcomes. Overall model accuracy increases with the inclusion of a subject-specific performance parameter based on laboratory trials that captures individual differences. In parallel, we demonstrate that the social media activity of individual subjects, specifically their Facebook use, can be used to generate an alternative individual personality profile that leads to comparable model accuracy. Quantitative characterization and prediction of collective decision making is crucial for the development of effective policies to guide the action of populations in the face of threat or uncertainty.