 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiGeo: Sub-One-Shot NAS via Information Theory and Geometry of Loss Landscape
Nov 22, 2023Neural Architecture Search (NAS) has become a widely used tool for automating neural network design. While one-shot NAS methods have successfully reduced computational requirements, they often require extensive training. On the other hand, zero-shot NAS utilizes training-free proxies to evaluate a candidate architecture's test performance but has two limitations: (1) inability to use the information gained as a network improves with training and (2) unreliable performance, particularly in complex domains like RecSys, due to the multi-modal data inputs and complex architecture configurations. To synthesize the benefits of both methods, we introduce a "sub-one-shot" paradigm that serves as a bridge between zero-shot and one-shot NAS. In sub-one-shot NAS, the supernet is trained using only a small subset of the training data, a phase we refer to as "warm-up." Within this framework, we present SiGeo, a proxy founded on a novel theoretical framework that connects the supernet warm-up with the efficacy of the proxy. Extensive experiments have shown that SiGeo, with the benefit of warm-up, consistently outperforms state-of-the-art NAS proxies on various established NAS benchmarks. When a supernet is warmed up, it can achieve comparable performance to weight-sharing one-shot NAS methods, but with a significant reduction ($\sim 60$\%) in computational costs.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023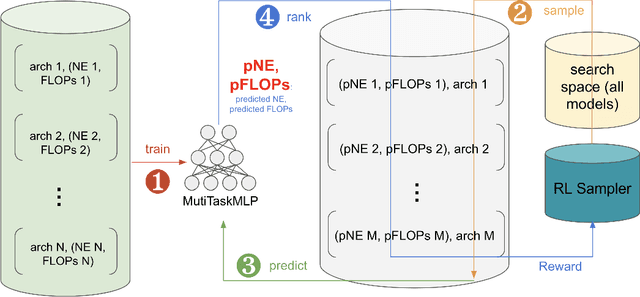
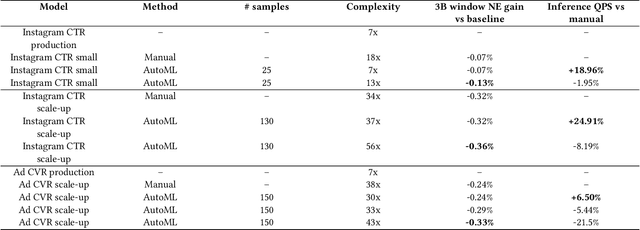
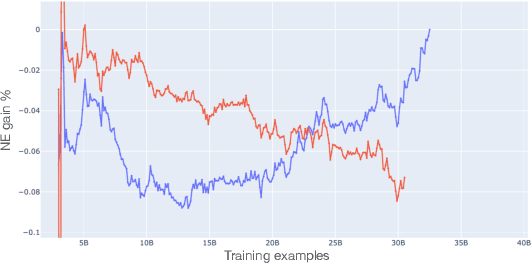

Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023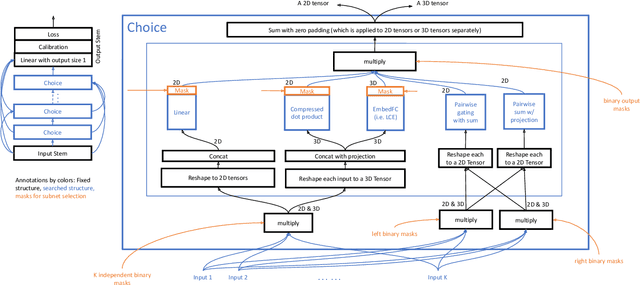
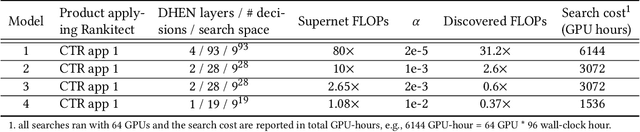
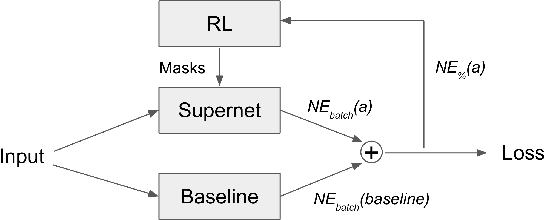
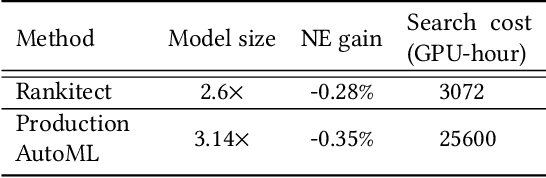
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.