 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Radio Access Networks: Architecture, State-of-the-Art, and Future Directions
Dec 24, 2025Radio Access Network (RAN) is a bridge between user devices and the core network in mobile communication systems, responsible for the transmission and reception of wireless signals and air interface management. In recent years, Semantic Communication (SemCom) has represented a transformative communication paradigm that prioritizes meaning-level transmission over conventional bit-level delivery, thus providing improved spectrum efficiency, anti-interference ability in complex environments, flexible resource allocation, and enhanced user experience for RAN. However, there is still a lack of comprehensive reviews on the integration of SemCom into RAN. Motivated by this, we systematically explore recent advancements in Semantic RAN (SemRAN). We begin by introducing the fundamentals of RAN and SemCom, identifying the limitations of conventional RAN, and outlining the overall architecture of SemRAN. Subsequently, we review representative techniques of SemRAN across physical layer, data link layer, network layer, and security plane. Furthermore, we envision future services and applications enabled by SemRAN, alongside its current standardization progress. Finally, we conclude by identifying critical research challenges and outlining forward-looking directions to guide subsequent investigations in this burgeoning field.
Image Steganography For Securing Intellicise Wireless Networks: "Invisible Encryption" Against Eavesdroppers
May 07, 2025As one of the most promising technologies for intellicise (intelligent and consice) wireless networks, Semantic Communication (SemCom) significantly improves communication efficiency by extracting, transmitting, and recovering semantic information, while reducing transmission delay. However, an integration of communication and artificial intelligence (AI) also exposes SemCom to security and privacy threats posed by intelligent eavesdroppers. To address this challenge, image steganography in SemCom embeds secret semantic features within cover semantic features, allowing intelligent eavesdroppers to decode only the cover image. This technique offers a form of "invisible encryption" for SemCom. Motivated by these advancements, this paper conducts a comprehensive exploration of integrating image steganography into SemCom. Firstly, we review existing encryption techniques in SemCom and assess the potential of image steganography in enhancing its security. Secondly, we delve into various image steganographic paradigms designed to secure SemCom, encompassing three categories of joint source-channel coding (JSCC) models tailored for image steganography SemCom, along with multiple training strategies. Thirdly, we present a case study to illustrate the effectiveness of coverless steganography SemCom. Finally, we propose future research directions for image steganography SemCom.
Secure Semantic Communication With Homomorphic Encryption
Jan 17, 2025



In recent years, Semantic Communication (SemCom), which aims to achieve efficient and reliable transmission of meaning between agents, has garnered significant attention from both academia and industry. To ensure the security of communication systems, encryption techniques are employed to safeguard confidentiality and integrity. However, traditional cryptography-based encryption algorithms encounter obstacles when applied to SemCom. Motivated by this, this paper explores the feasibility of applying homomorphic encryption to SemCom. Initially, we review the encryption algorithms utilized in mobile communication systems and analyze the challenges associated with their application to SemCom. Subsequently, we employ scale-invariant feature transform to demonstrate that semantic features can be preserved in homomorphic encrypted ciphertext. Based on this finding, we propose a task-oriented SemCom scheme secured through homomorphic encryption. We design the privacy preserved deep joint source-channel coding (JSCC) encoder and decoder, and the frequency of key updates can be adjusted according to service requirements without compromising transmission performance. Simulation results validate that, when compared to plaintext images, the proposed scheme can achieve almost the same classification accuracy performance when dealing with homomorphic ciphertext images. Furthermore, we provide potential future research directions for homomorphic encrypted SemCom.
A Survey of Secure Semantic Communications
Jan 01, 2025



Semantic communication (SemCom) is regarded as a promising and revolutionary technology in 6G, aiming to transcend the constraints of ``Shannon's trap" by filtering out redundant information and extracting the core of effective data. Compared to traditional communication paradigms, SemCom offers several notable advantages, such as reducing the burden on data transmission, enhancing network management efficiency, and optimizing resource allocation. Numerous researchers have extensively explored SemCom from various perspectives, including network architecture, theoretical analysis, potential technologies, and future applications. However, as SemCom continues to evolve, a multitude of security and privacy concerns have arisen, posing threats to the confidentiality, integrity, and availability of SemCom systems. This paper presents a comprehensive survey of the technologies that can be utilized to secure SemCom. Firstly, we elaborate on the entire life cycle of SemCom, which includes the model training, model transfer, and semantic information transmission phases. Then, we identify the security and privacy issues that emerge during these three stages. Furthermore, we summarize the techniques available to mitigate these security and privacy threats, including data cleaning, robust learning, defensive strategies against backdoor attacks, adversarial training, differential privacy, cryptography, blockchain technology, model compression, and physical-layer security. Lastly, this paper outlines future research directions to guide researchers in related fields.
Cross-Layer Encrypted Semantic Communication Framework for Panoramic Video Transmission
Nov 19, 2024In this paper, we propose a cross-layer encrypted semantic communication (CLESC) framework for panoramic video transmission, incorporating feature extraction, encoding, encryption, cyclic redundancy check (CRC), and retransmission processes to achieve compatibility between semantic communication and traditional communication systems. Additionally, we propose an adaptive cross-layer transmission mechanism that dynamically adjusts CRC, channel coding, and retransmission schemes based on the importance of semantic information. This ensures that important information is prioritized under poor transmission conditions. To verify the aforementioned framework, we also design an end-to-end adaptive panoramic video semantic transmission (APVST) network that leverages a deep joint source-channel coding (Deep JSCC) structure and attention mechanism, integrated with a latitude adaptive module that facilitates adaptive semantic feature extraction and variable-length encoding of panoramic videos. The proposed CLESC is also applicable to the transmission of other modal data. Simulation results demonstrate that the proposed CLESC effectively achieves compatibility and adaptation between semantic communication and traditional communication systems, improving both transmission efficiency and channel adaptability. Compared to traditional cross-layer transmission schemes, the CLESC framework can reduce bandwidth consumption by 85% while showing significant advantages under low signal-to-noise ratio (SNR) conditions.
Semantic Communication-Enabled Wireless Adaptive Panoramic Video Transmission
Feb 26, 2024



In this paper, we propose an adaptive panoramic video semantic transmission (APVST) network built on the deep joint source-channel coding (Deep JSCC) structure for the efficient end-to-end transmission of panoramic videos. The proposed APVST network can adaptively extract semantic features of panoramic frames and achieve semantic feature encoding. To achieve high spectral efficiency and save bandwidth, we propose a transmission rate control mechanism for the APVST via the entropy model and the latitude adaptive model. Besides, we take weighted-to-spherically-uniform peak signal-to-noise ratio (WS-PSNR) and weighted-to-spherically-uniform structural similarity (WS-SSIM) as distortion evaluation metrics, and propose the weight attention module to fuse the weights with the semantic features to achieve better quality of immersive experiences. Finally, we evaluate our proposed scheme on a panoramic video dataset containing 208 panoramic videos. The simulation results show that the APVST can save up to 20% and 50% on channel bandwidth cost compared with other semantic communication-based and traditional video transmission schemes.
AutoML for Large Capacity Modeling of Meta's Ranking Systems
Nov 16, 2023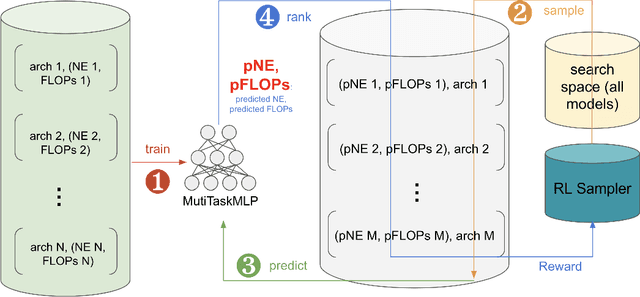
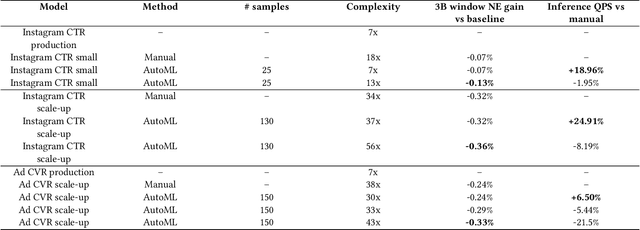
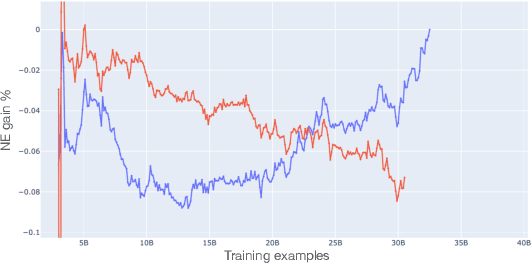

Web-scale ranking systems at Meta serving billions of users is complex. Improving ranking models is essential but engineering heavy. Automated Machine Learning (AutoML) can release engineers from labor intensive work of tuning ranking models; however, it is unknown if AutoML is efficient enough to meet tight production timeline in real-world and, at the same time, bring additional improvements to the strong baselines. Moreover, to achieve higher ranking performance, there is an ever-increasing demand to scale up ranking models to even larger capacity, which imposes more challenges on the efficiency. The large scale of models and tight production schedule requires AutoML to outperform human baselines by only using a small number of model evaluation trials (around 100). We presents a sampling-based AutoML method, focusing on neural architecture search and hyperparameter optimization, addressing these challenges in Meta-scale production when building large capacity models. Our approach efficiently handles large-scale data demands. It leverages a lightweight predictor-based searcher and reinforcement learning to explore vast search spaces, significantly reducing the number of model evaluations. Through experiments in large capacity modeling for CTR and CVR applications, we show that our method achieves outstanding Return on Investment (ROI) versus human tuned baselines, with up to 0.09% Normalized Entropy (NE) loss reduction or $25\%$ Query per Second (QPS) increase by only sampling one hundred models on average from a curated search space. The proposed AutoML method has already made real-world impact where a discovered Instagram CTR model with up to -0.36% NE gain (over existing production baseline) was selected for large-scale online A/B test and show statistically significant gain. These production results proved AutoML efficacy and accelerated its adoption in ranking systems at Meta.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023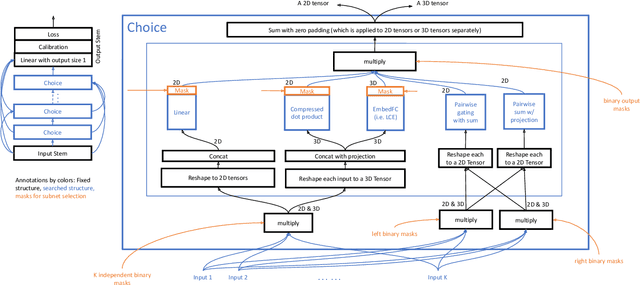
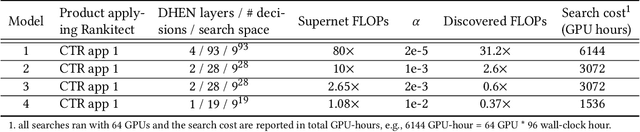
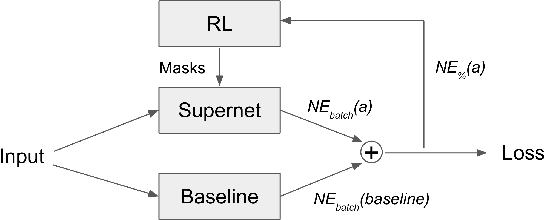
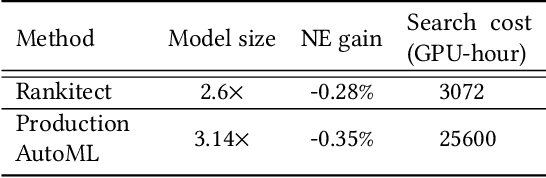
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
MoCL: Contrastive Learning on Molecular Graphs with Multi-level Domain Knowledge
Jun 05, 2021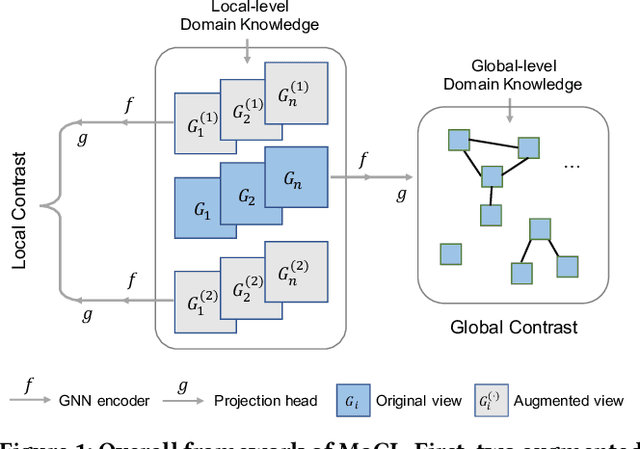
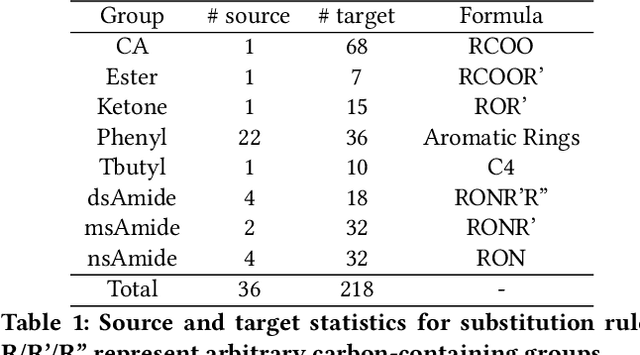
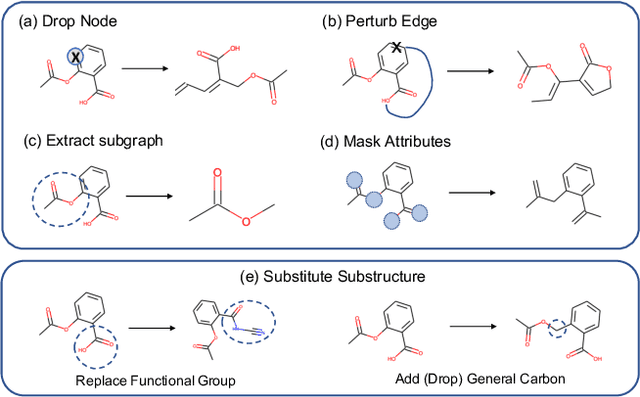

Recent years have seen a rapid growth of utilizing graph neural networks (GNNs) in the biomedical domain for tackling drug-related problems. However, like any other deep architectures, GNNs are data hungry. While requiring labels in real world is often expensive, pretraining GNNs in an unsupervised manner has been actively explored. Among them, graph contrastive learning, by maximizing the mutual information between paired graph augmentations, has been shown to be effective on various downstream tasks. However, the current graph contrastive learning framework has two limitations. First, the augmentations are designed for general graphs and thus may not be suitable or powerful enough for certain domains. Second, the contrastive scheme only learns representations that are invariant to local perturbations and thus does not consider the global structure of the dataset, which may also be useful for downstream tasks. Therefore, in this paper, we study graph contrastive learning in the context of biomedical domain, where molecular graphs are present. We propose a novel framework called MoCL, which utilizes domain knowledge at both local- and global-level to assist representation learning. The local-level domain knowledge guides the augmentation process such that variation is introduced without changing graph semantics. The global-level knowledge encodes the similarity information between graphs in the entire dataset and helps to learn representations with richer semantics. The entire model is learned through a double contrast objective. We evaluate MoCL on various molecular datasets under both linear and semi-supervised settings and results show that MoCL achieves state-of-the-art performance.
Learning Deep Neural Networks under Agnostic Corrupted Supervision
Feb 12, 2021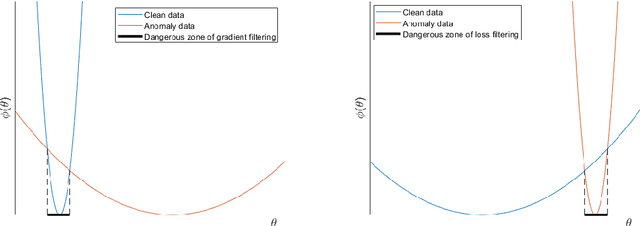
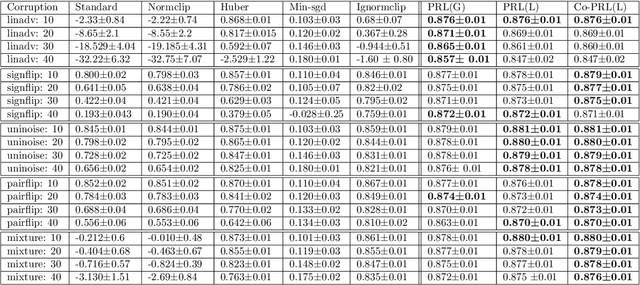

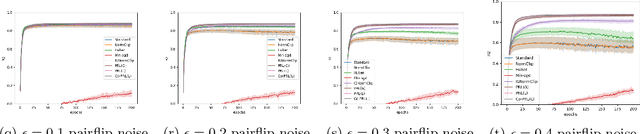
Training deep neural models in the presence of corrupted supervision is challenging as the corrupted data points may significantly impact the generalization performance. To alleviate this problem, we present an efficient robust algorithm that achieves strong guarantees without any assumption on the type of corruption and provides a unified framework for both classification and regression problems. Unlike many existing approaches that quantify the quality of the data points (e.g., based on their individual loss values), and filter them accordingly, the proposed algorithm focuses on controlling the collective impact of data points on the average gradient. Even when a corrupted data point failed to be excluded by our algorithm, the data point will have a very limited impact on the overall loss, as compared with state-of-the-art filtering methods based on loss values. Extensive experiments on multiple benchmark datasets have demonstrated the robustness of our algorithm under different types of corruption.