 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs as inspectors: an agentic framework for category-level structural defect annotation
Oct 01, 2025



Automated structural defect annotation is essential for ensuring infrastructure safety while minimizing the high costs and inefficiencies of manual labeling. A novel agentic annotation framework, Agent-based Defect Pattern Tagger (ADPT), is introduced that integrates Large Vision-Language Models (LVLMs) with a semantic pattern matching module and an iterative self-questioning refinement mechanism. By leveraging optimized domain-specific prompting and a recursive verification process, ADPT transforms raw visual data into high-quality, semantically labeled defect datasets without any manual supervision. Experimental results demonstrate that ADPT achieves up to 98% accuracy in distinguishing defective from non-defective images, and 85%-98% annotation accuracy across four defect categories under class-balanced settings, with 80%-92% accuracy on class-imbalanced datasets. The framework offers a scalable and cost-effective solution for high-fidelity dataset construction, providing strong support for downstream tasks such as transfer learning and domain adaptation in structural damage assessment.
Cross-Layer Encrypted Semantic Communication Framework for Panoramic Video Transmission
Nov 19, 2024In this paper, we propose a cross-layer encrypted semantic communication (CLESC) framework for panoramic video transmission, incorporating feature extraction, encoding, encryption, cyclic redundancy check (CRC), and retransmission processes to achieve compatibility between semantic communication and traditional communication systems. Additionally, we propose an adaptive cross-layer transmission mechanism that dynamically adjusts CRC, channel coding, and retransmission schemes based on the importance of semantic information. This ensures that important information is prioritized under poor transmission conditions. To verify the aforementioned framework, we also design an end-to-end adaptive panoramic video semantic transmission (APVST) network that leverages a deep joint source-channel coding (Deep JSCC) structure and attention mechanism, integrated with a latitude adaptive module that facilitates adaptive semantic feature extraction and variable-length encoding of panoramic videos. The proposed CLESC is also applicable to the transmission of other modal data. Simulation results demonstrate that the proposed CLESC effectively achieves compatibility and adaptation between semantic communication and traditional communication systems, improving both transmission efficiency and channel adaptability. Compared to traditional cross-layer transmission schemes, the CLESC framework can reduce bandwidth consumption by 85% while showing significant advantages under low signal-to-noise ratio (SNR) conditions.
Integration of Large Vision Language Models for Efficient Post-disaster Damage Assessment and Reporting
Nov 03, 2024



Traditional natural disaster response involves significant coordinated teamwork where speed and efficiency are key. Nonetheless, human limitations can delay critical actions and inadvertently increase human and economic losses. Agentic Large Vision Language Models (LVLMs) offer a new avenue to address this challenge, with the potential for substantial socio-economic impact, particularly by improving resilience and resource access in underdeveloped regions. We introduce DisasTeller, the first multi-LVLM-powered framework designed to automate tasks in post-disaster management, including on-site assessment, emergency alerts, resource allocation, and recovery planning. By coordinating four specialised LVLM agents with GPT-4 as the core model, DisasTeller autonomously implements disaster response activities, reducing human execution time and optimising resource distribution. Our evaluations through both LVLMs and humans demonstrate DisasTeller's effectiveness in streamlining disaster response. This framework not only supports expert teams but also simplifies access to disaster management processes for non-experts, bridging the gap between traditional response methods and LVLM-driven efficiency.
Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces
Jun 24, 2024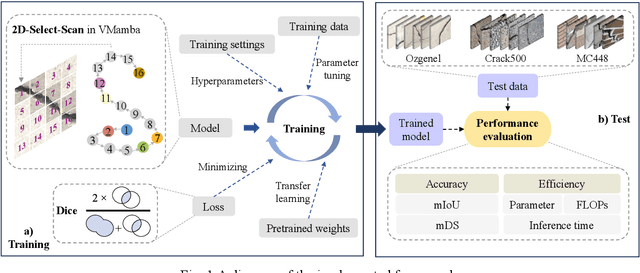
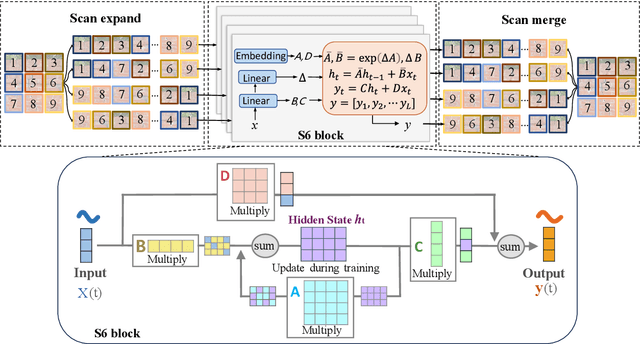
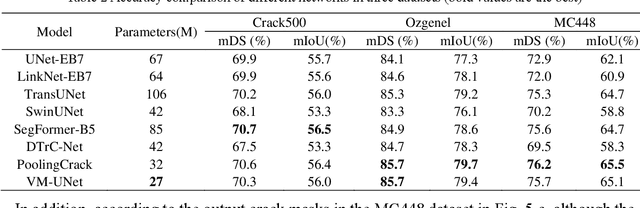
Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection under certain conditions. Yet, the fixed local attention can compromise the generalisation of CNNs, and the quadratic complexity of the global self-attention restricts the practical deployment of Transformers. Given the emergence of the new-generation architecture of Mamba, this paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, with high accuracy, generalisation, and less computational complexity. Having 15.6% - 74.5% fewer parameters, the encoder-decoder network integrated with VMamba could obtain up to 2.8% higher mDS than representative CNN-based models while showing about the same performance as Transformer-based models. Moreover, the VMamba-based encoder-decoder network could process high-resolution image input with up to 90.6% lower floating-point operations.
Robust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Apr 09, 2024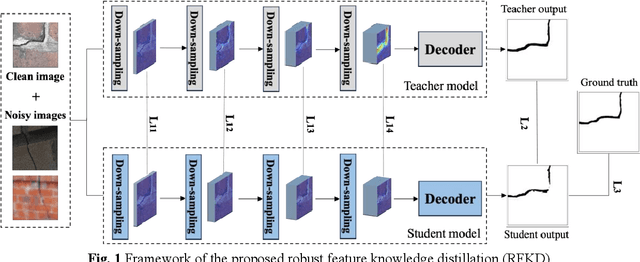
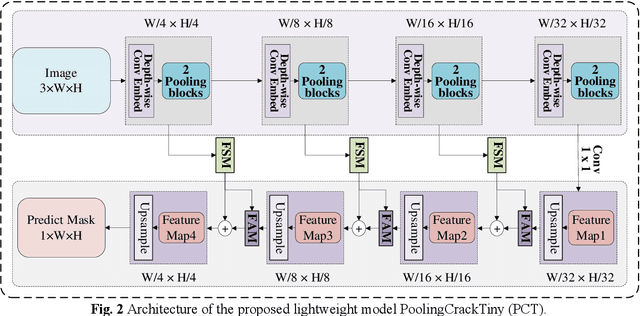
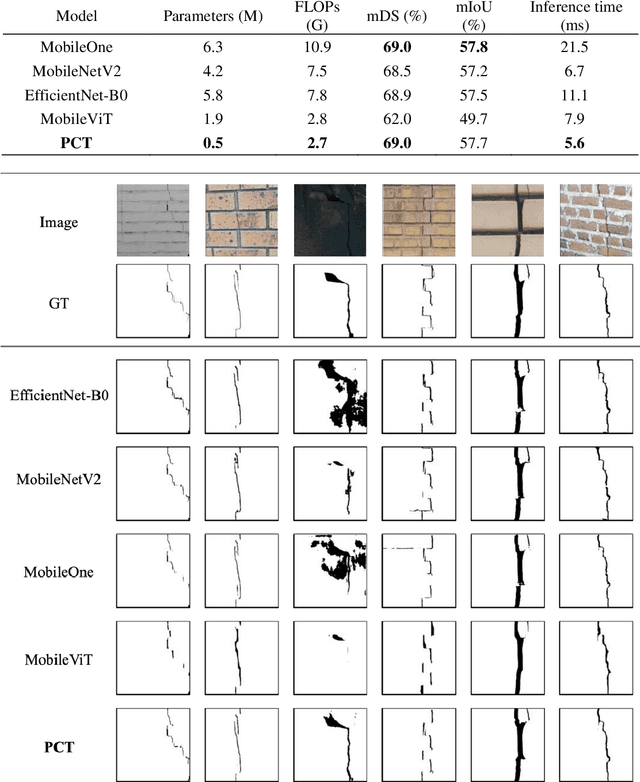
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.
A BiRGAT Model for Multi-intent Spoken Language Understanding with Hierarchical Semantic Frames
Feb 28, 2024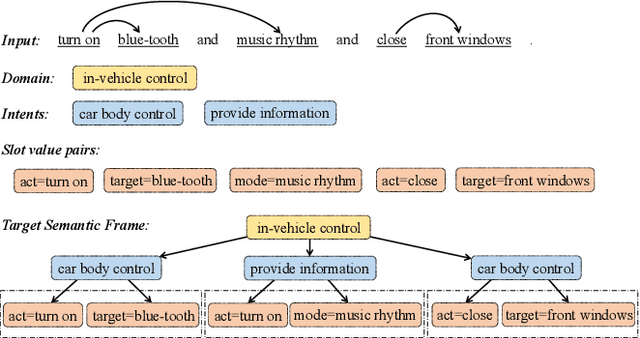
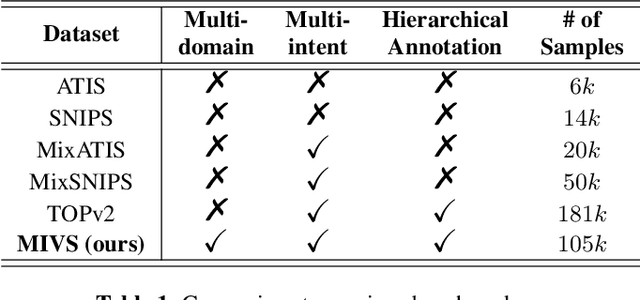
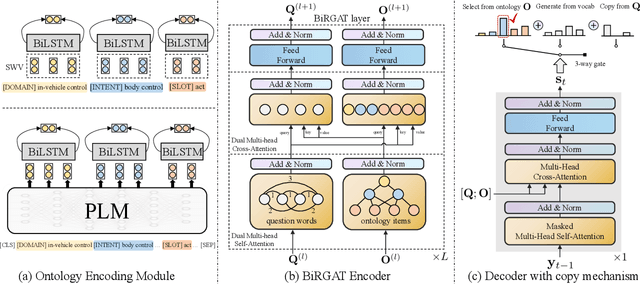
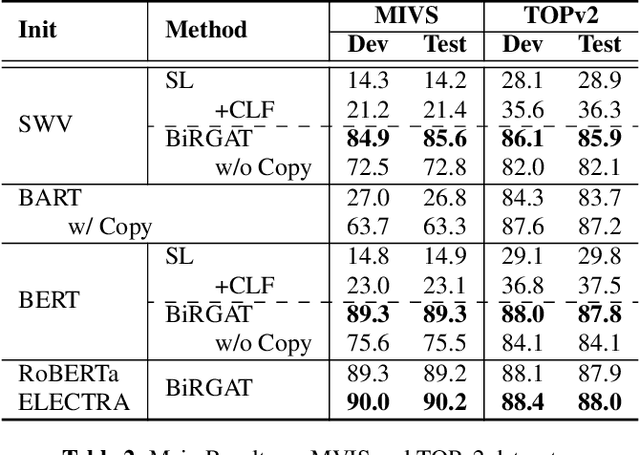
Previous work on spoken language understanding (SLU) mainly focuses on single-intent settings, where each input utterance merely contains one user intent. This configuration significantly limits the surface form of user utterances and the capacity of output semantics. In this work, we first propose a Multi-Intent dataset which is collected from a realistic in-Vehicle dialogue System, called MIVS. The target semantic frame is organized in a 3-layer hierarchical structure to tackle the alignment and assignment problems in multi-intent cases. Accordingly, we devise a BiRGAT model to encode the hierarchy of ontology items, the backbone of which is a dual relational graph attention network. Coupled with the 3-way pointer-generator decoder, our method outperforms traditional sequence labeling and classification-based schemes by a large margin.
Exploiting Global Contextual Information for Document-level Named Entity Recognition
Jun 02, 2021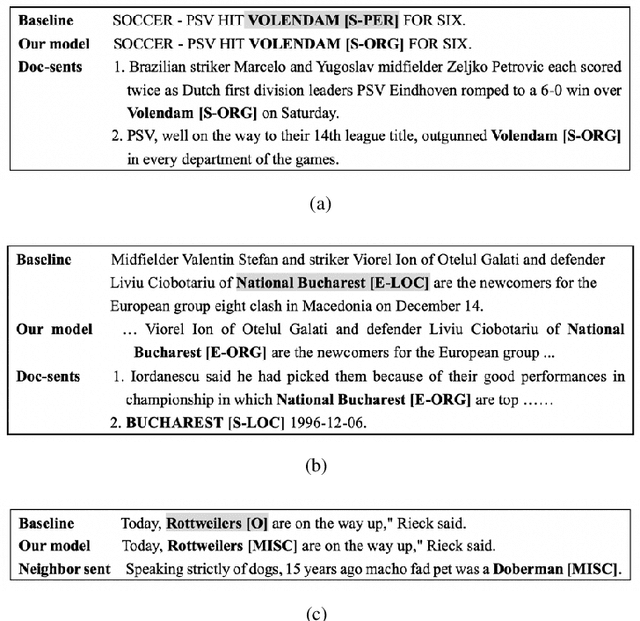
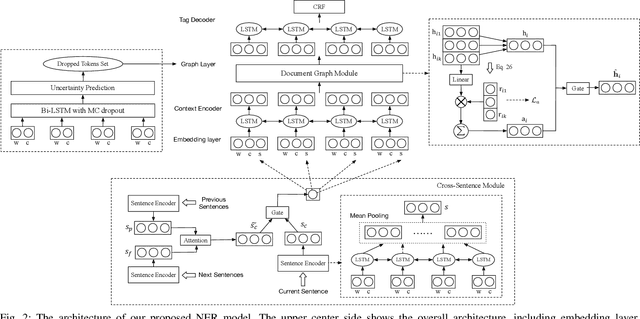

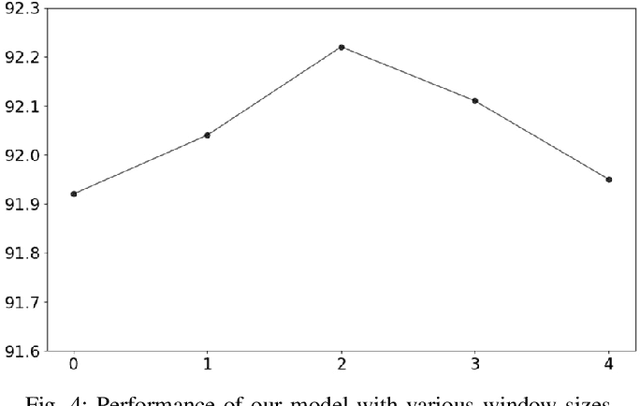
Most existing named entity recognition (NER) approaches are based on sequence labeling models, which focus on capturing the local context dependencies. However, the way of taking one sentence as input prevents the modeling of non-sequential global context, which is useful especially when local context information is limited or ambiguous. To this end, we propose a model called Global Context enhanced Document-level NER (GCDoc) to leverage global contextual information from two levels, i.e., both word and sentence. At word-level, a document graph is constructed to model a wider range of dependencies between words, then obtain an enriched contextual representation for each word via graph neural networks (GNN). To avoid the interference of noise information, we further propose two strategies. First we apply the epistemic uncertainty theory to find out tokens whose representations are less reliable, thereby helping prune the document graph. Then a selective auxiliary classifier is proposed to effectively learn the weight of edges in document graph and reduce the importance of noisy neighbour nodes. At sentence-level, for appropriately modeling wider context beyond single sentence, we employ a cross-sentence module which encodes adjacent sentences and fuses it with the current sentence representation via attention and gating mechanisms. Extensive experiments on two benchmark NER datasets (CoNLL 2003 and Ontonotes 5.0 English dataset) demonstrate the effectiveness of our proposed model. Our model reaches F1 score of 92.22 (93.40 with BERT) on CoNLL 2003 dataset and 88.32 (90.49 with BERT) on Ontonotes 5.0 dataset, achieving new state-of-the-art performance.
A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
Nov 13, 2020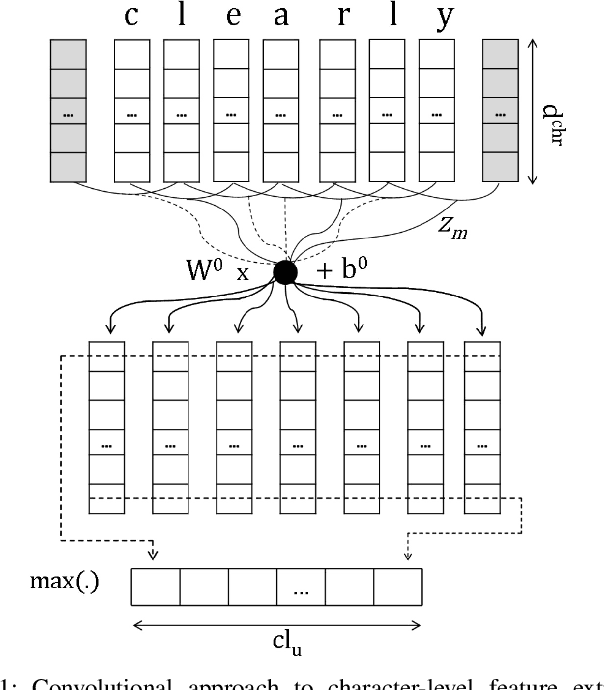
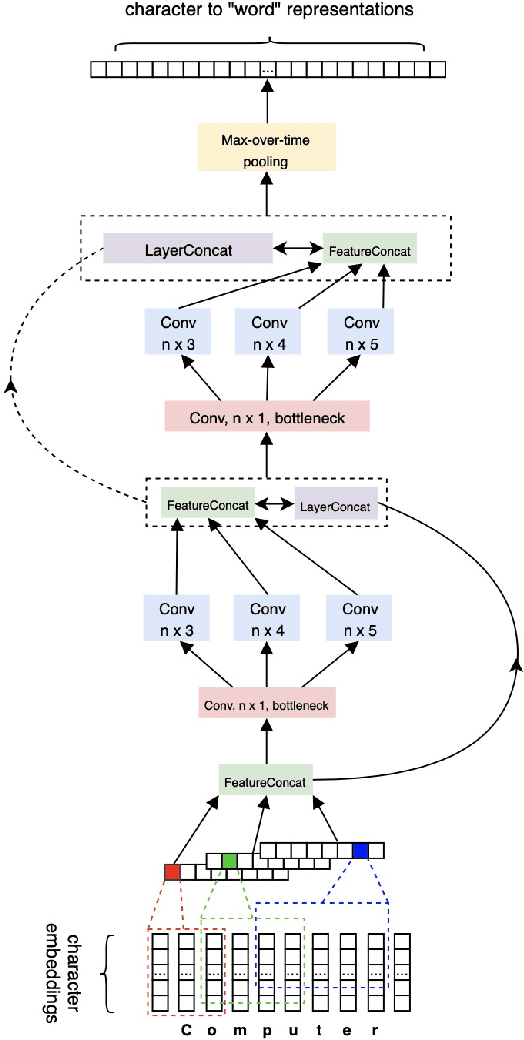
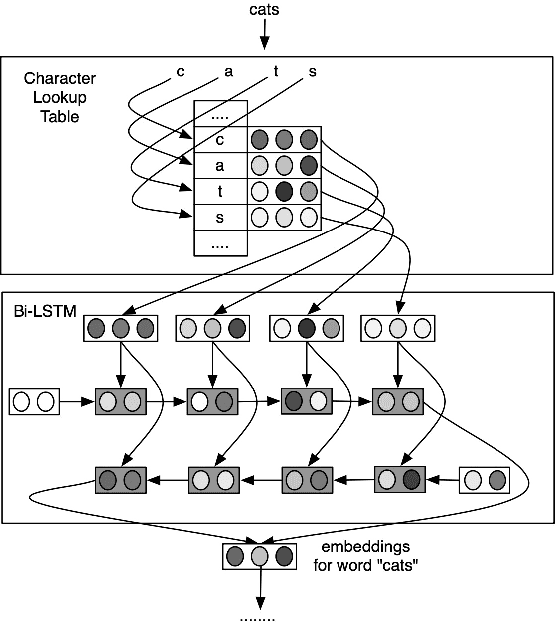
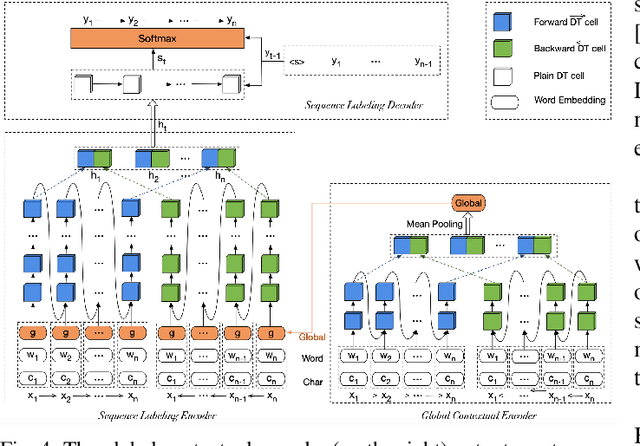
Sequence labeling (SL) is a fundamental research problem encompassing a variety of tasks, e.g., part-of-speech (POS) tagging, named entity recognition (NER), text chunking, etc. Though prevalent and effective in many downstream applications (e.g., information retrieval, question answering, and knowledge graph embedding), conventional sequence labeling approaches heavily rely on hand-crafted or language-specific features. Recently, deep learning has been employed for sequence labeling tasks due to its powerful capability in automatically learning complex features of instances and effectively yielding the stat-of-the-art performances. In this paper, we aim to present a comprehensive review of existing deep learning-based sequence labeling models, which consists of three related tasks, e.g., part-of-speech tagging, named entity recognition, and text chunking. Then, we systematically present the existing approaches base on a scientific taxonomy, as well as the widely-used experimental datasets and popularly-adopted evaluation metrics in the SL domain. Furthermore, we also present an in-depth analysis of different SL models on the factors that may affect the performance and future directions in the SL domain.
Enhancing Neural Sequence Labeling with Position-Aware Self-Attention
Aug 24, 2019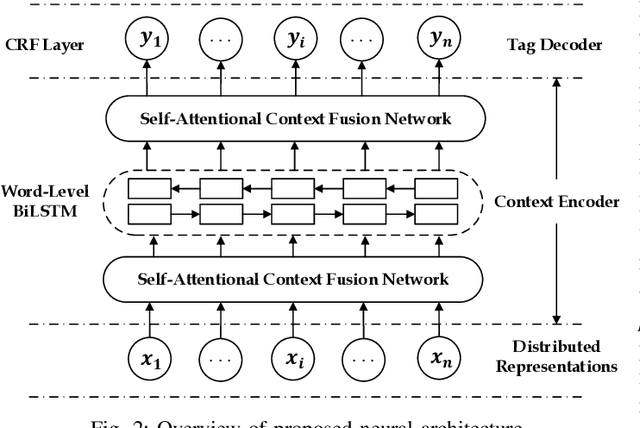
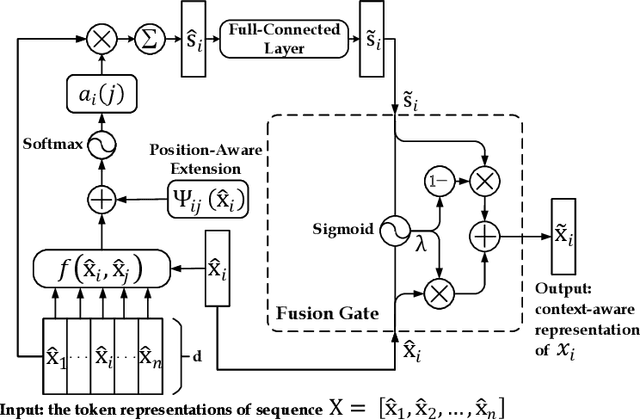
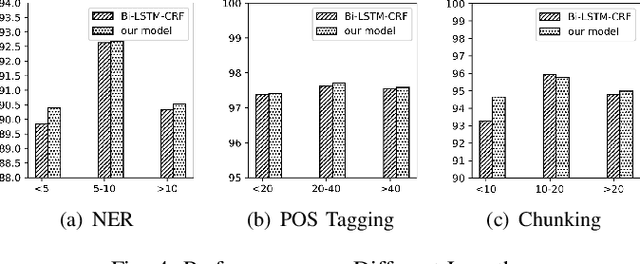
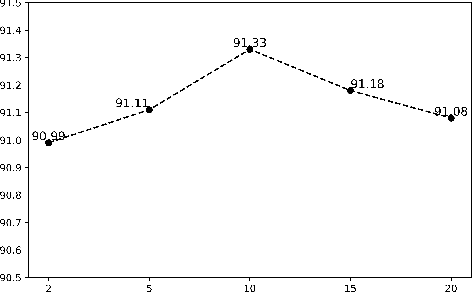
Sequence labeling is a fundamental task in natural language processing and has been widely studied. Recently, RNN-based sequence labeling models have increasingly gained attentions. Despite superior performance achieved by learning the long short-term (i.e., successive) dependencies, the way of sequentially processing inputs might limit the ability to capture the non-continuous relations over tokens within a sentence. To tackle the problem, we focus on how to effectively model successive and discrete dependencies of each token for enhancing the sequence labeling performance. Specifically, we propose an innovative and well-designed attention-based model (called position-aware self-attention, i.e., PSA) within a neural network architecture, to explore the positional information of an input sequence for capturing the latent relations among tokens. Extensive experiments on three classical tasks in sequence labeling domain, i.e., part-of-speech (POS) tagging, named entity recognition (NER) and phrase chunking, demonstrate our proposed model outperforms the state-of-the-arts without any external knowledge, in terms of various metrics.