 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Paper and Code
Apr 09, 2024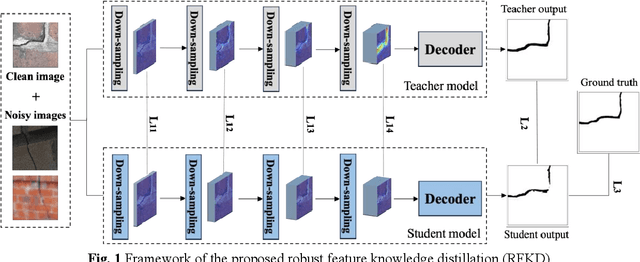
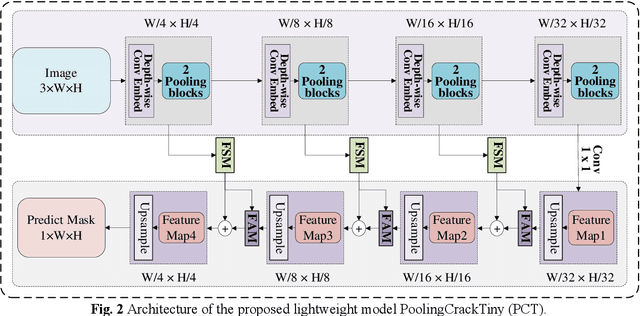
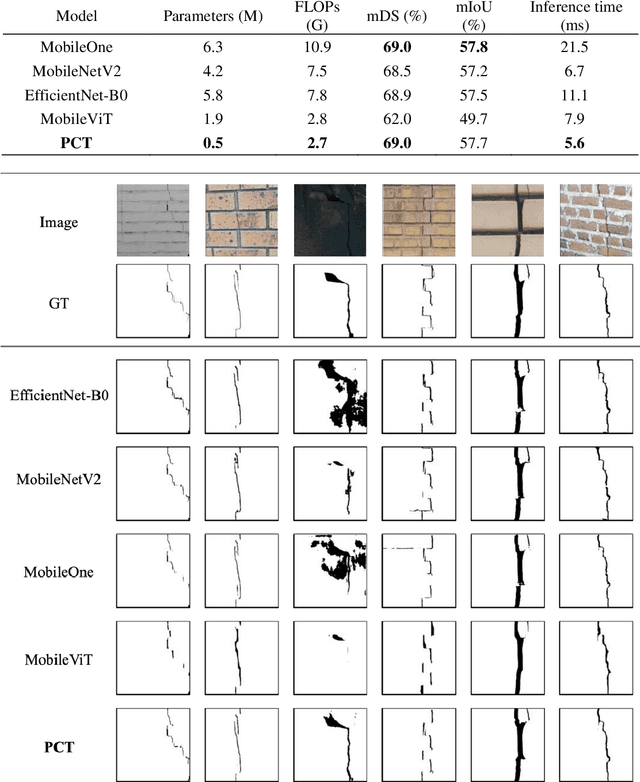
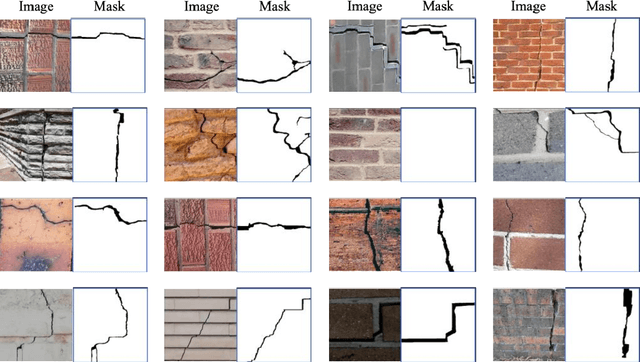
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.