 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVLMs as inspectors: an agentic framework for category-level structural defect annotation
Oct 01, 2025



Automated structural defect annotation is essential for ensuring infrastructure safety while minimizing the high costs and inefficiencies of manual labeling. A novel agentic annotation framework, Agent-based Defect Pattern Tagger (ADPT), is introduced that integrates Large Vision-Language Models (LVLMs) with a semantic pattern matching module and an iterative self-questioning refinement mechanism. By leveraging optimized domain-specific prompting and a recursive verification process, ADPT transforms raw visual data into high-quality, semantically labeled defect datasets without any manual supervision. Experimental results demonstrate that ADPT achieves up to 98% accuracy in distinguishing defective from non-defective images, and 85%-98% annotation accuracy across four defect categories under class-balanced settings, with 80%-92% accuracy on class-imbalanced datasets. The framework offers a scalable and cost-effective solution for high-fidelity dataset construction, providing strong support for downstream tasks such as transfer learning and domain adaptation in structural damage assessment.
Integration of Large Vision Language Models for Efficient Post-disaster Damage Assessment and Reporting
Nov 03, 2024



Traditional natural disaster response involves significant coordinated teamwork where speed and efficiency are key. Nonetheless, human limitations can delay critical actions and inadvertently increase human and economic losses. Agentic Large Vision Language Models (LVLMs) offer a new avenue to address this challenge, with the potential for substantial socio-economic impact, particularly by improving resilience and resource access in underdeveloped regions. We introduce DisasTeller, the first multi-LVLM-powered framework designed to automate tasks in post-disaster management, including on-site assessment, emergency alerts, resource allocation, and recovery planning. By coordinating four specialised LVLM agents with GPT-4 as the core model, DisasTeller autonomously implements disaster response activities, reducing human execution time and optimising resource distribution. Our evaluations through both LVLMs and humans demonstrate DisasTeller's effectiveness in streamlining disaster response. This framework not only supports expert teams but also simplifies access to disaster management processes for non-experts, bridging the gap between traditional response methods and LVLM-driven efficiency.
Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces
Jun 24, 2024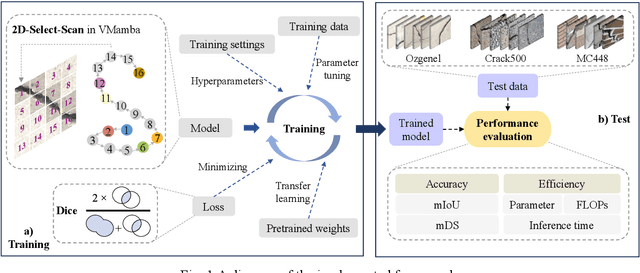
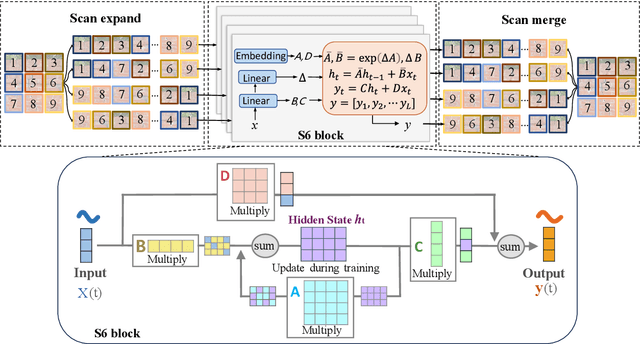
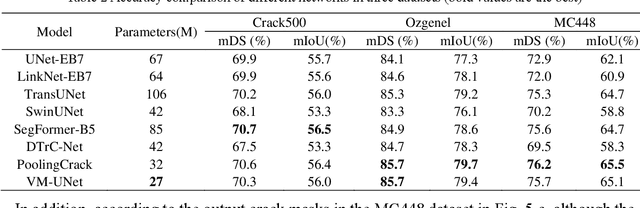
Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection under certain conditions. Yet, the fixed local attention can compromise the generalisation of CNNs, and the quadratic complexity of the global self-attention restricts the practical deployment of Transformers. Given the emergence of the new-generation architecture of Mamba, this paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, with high accuracy, generalisation, and less computational complexity. Having 15.6% - 74.5% fewer parameters, the encoder-decoder network integrated with VMamba could obtain up to 2.8% higher mDS than representative CNN-based models while showing about the same performance as Transformer-based models. Moreover, the VMamba-based encoder-decoder network could process high-resolution image input with up to 90.6% lower floating-point operations.
Robust feature knowledge distillation for enhanced performance of lightweight crack segmentation models
Apr 09, 2024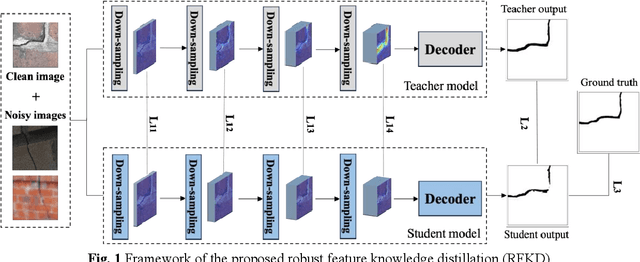
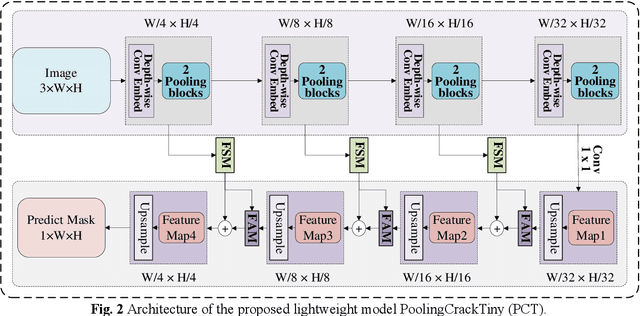
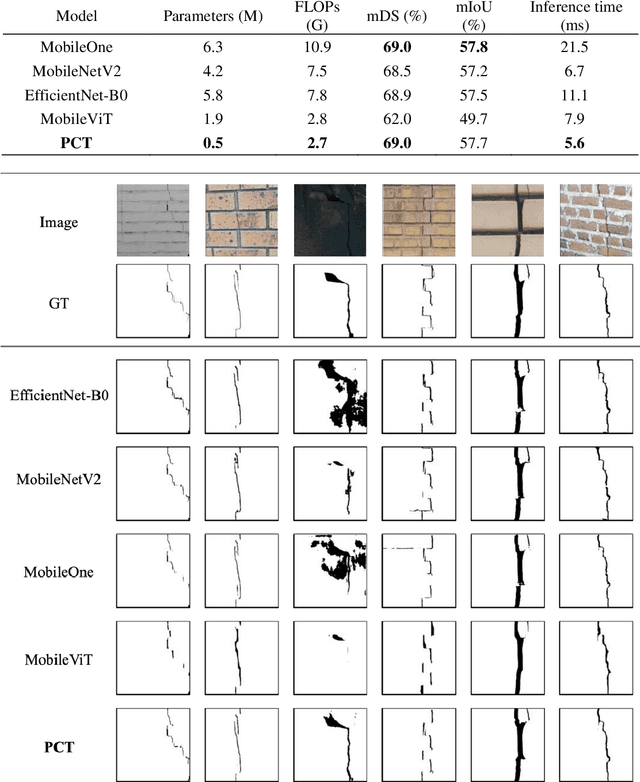
Vision-based crack detection faces deployment challenges due to the size of robust models and edge device limitations. These can be addressed with lightweight models trained with knowledge distillation (KD). However, state-of-the-art (SOTA) KD methods compromise anti-noise robustness. This paper develops Robust Feature Knowledge Distillation (RFKD), a framework to improve robustness while retaining the precision of light models for crack segmentation. RFKD distils knowledge from a teacher model's logit layers and intermediate feature maps while leveraging mixed clean and noisy images to transfer robust patterns to the student model, improving its precision, generalisation, and anti-noise performance. To validate the proposed RFKD, a lightweight crack segmentation model, PoolingCrack Tiny (PCT), with only 0.5 M parameters, is also designed and used as the student to run the framework. The results show a significant enhancement in noisy images, with RFKD reaching a 62% enhanced mean Dice score (mDS) compared to SOTA KD methods.