 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces
Paper and Code
Jun 24, 2024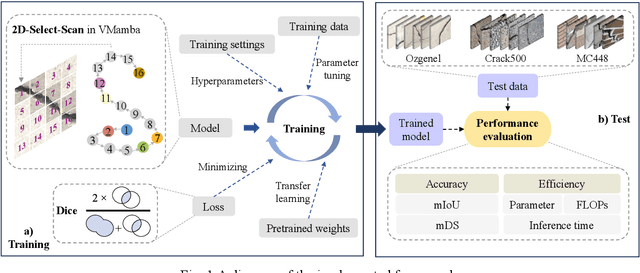
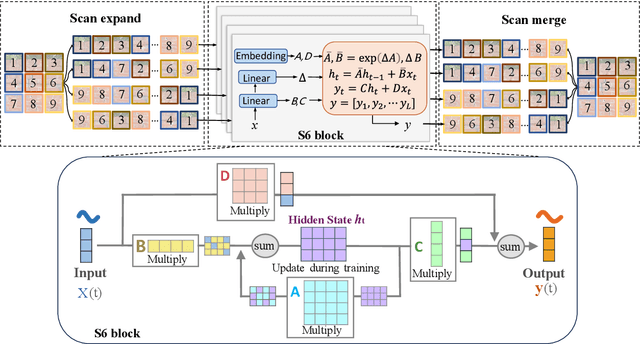
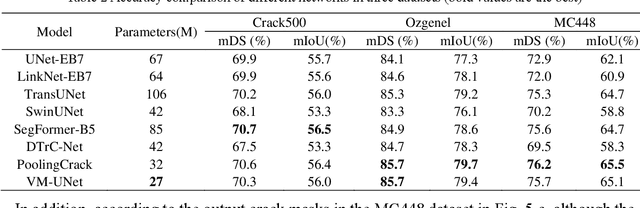
Convolutional neural networks (CNNs) and Transformers have shown advanced accuracy in crack detection under certain conditions. Yet, the fixed local attention can compromise the generalisation of CNNs, and the quadratic complexity of the global self-attention restricts the practical deployment of Transformers. Given the emergence of the new-generation architecture of Mamba, this paper proposes a Vision Mamba (VMamba)-based framework for crack segmentation on concrete, asphalt, and masonry surfaces, with high accuracy, generalisation, and less computational complexity. Having 15.6% - 74.5% fewer parameters, the encoder-decoder network integrated with VMamba could obtain up to 2.8% higher mDS than representative CNN-based models while showing about the same performance as Transformer-based models. Moreover, the VMamba-based encoder-decoder network could process high-resolution image input with up to 90.6% lower floating-point operations.