 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Neural Sequence Labeling with Position-Aware Self-Attention
Paper and Code
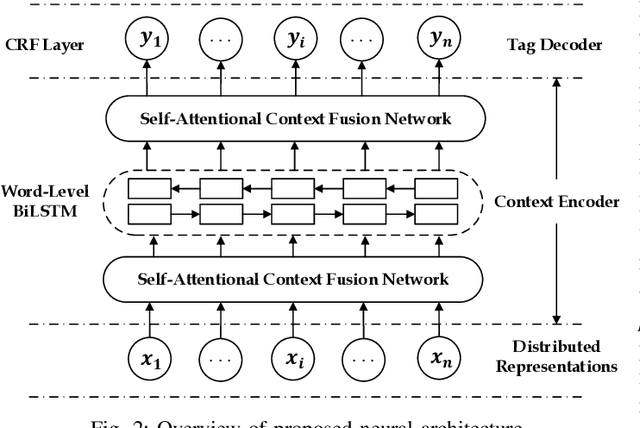
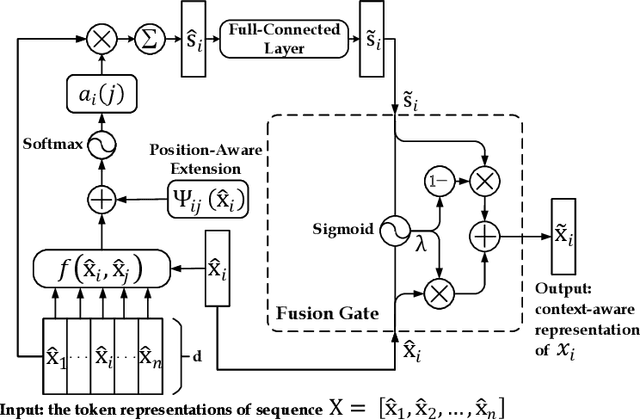
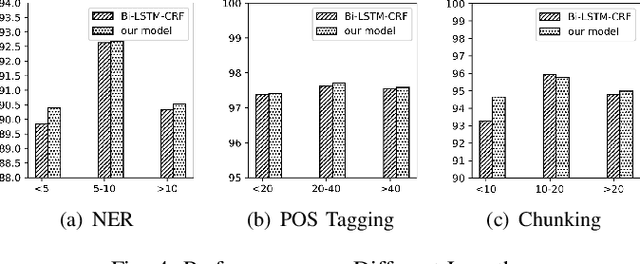
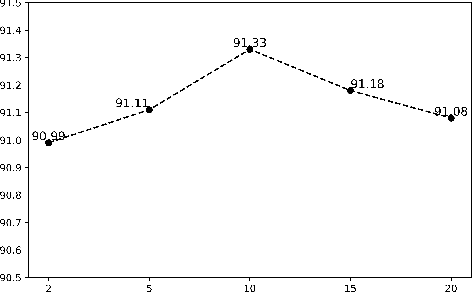
Sequence labeling is a fundamental task in natural language processing and has been widely studied. Recently, RNN-based sequence labeling models have increasingly gained attentions. Despite superior performance achieved by learning the long short-term (i.e., successive) dependencies, the way of sequentially processing inputs might limit the ability to capture the non-continuous relations over tokens within a sentence. To tackle the problem, we focus on how to effectively model successive and discrete dependencies of each token for enhancing the sequence labeling performance. Specifically, we propose an innovative and well-designed attention-based model (called position-aware self-attention, i.e., PSA) within a neural network architecture, to explore the positional information of an input sequence for capturing the latent relations among tokens. Extensive experiments on three classical tasks in sequence labeling domain, i.e., part-of-speech (POS) tagging, named entity recognition (NER) and phrase chunking, demonstrate our proposed model outperforms the state-of-the-arts without any external knowledge, in terms of various metrics.