 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Topic Selection Model for Topic-Grounded Dialogue
Jun 04, 2024Recently, the topic-grounded dialogue (TGD) system has become increasingly popular as its powerful capability to actively guide users to accomplish specific tasks through topic-guided conversations. Most existing works utilize side information (\eg topics or personas) in isolation to enhance the topic selection ability. However, due to disregarding the noise within these auxiliary information sources and their mutual influence, current models tend to predict user-uninteresting and contextually irrelevant topics. To build user-engaging and coherent dialogue agent, we propose a \textbf{P}ersonalized topic s\textbf{E}lection model for \textbf{T}opic-grounded \textbf{D}ialogue, named \textbf{PETD}, which takes account of the interaction of side information to selectively aggregate such information for more accurately predicting subsequent topics. Specifically, we evaluate the correlation between global topics and personas and selectively incorporate the global topics aligned with user personas. Furthermore, we propose a contrastive learning based persona selector to filter out irrelevant personas under the constraint of lacking pertinent persona annotations. Throughout the selection and generation, diverse relevant side information is considered. Extensive experiments demonstrate that our proposed method can generate engaging and diverse responses, outperforming state-of-the-art baselines across various evaluation metrics.
Joint Multi-Facts Reasoning Network For Complex Temporal Question Answering Over Knowledge Graph
Jan 04, 2024Temporal Knowledge Graph (TKG) is an extension of regular knowledge graph by attaching the time scope. Existing temporal knowledge graph question answering (TKGQA) models solely approach simple questions, owing to the prior assumption that each question only contains a single temporal fact with explicit/implicit temporal constraints. Hence, they perform poorly on questions which own multiple temporal facts. In this paper, we propose \textbf{\underline{J}}oint \textbf{\underline{M}}ulti \textbf{\underline{F}}acts \textbf{\underline{R}}easoning \textbf{\underline{N}}etwork (JMFRN), to jointly reasoning multiple temporal facts for accurately answering \emph{complex} temporal questions. Specifically, JMFRN first retrieves question-related temporal facts from TKG for each entity of the given complex question. For joint reasoning, we design two different attention (\ie entity-aware and time-aware) modules, which are suitable for universal settings, to aggregate entities and timestamps information of retrieved facts. Moreover, to filter incorrect type answers, we introduce an additional answer type discrimination task. Extensive experiments demonstrate our proposed method significantly outperforms the state-of-art on the well-known complex temporal question benchmark TimeQuestions.
Improving Personality Consistency in Conversation by Persona Extending
Aug 23, 2022
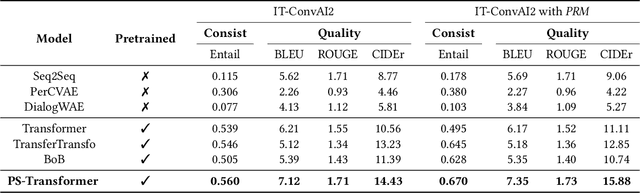
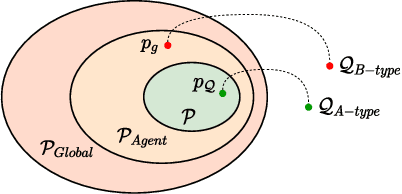
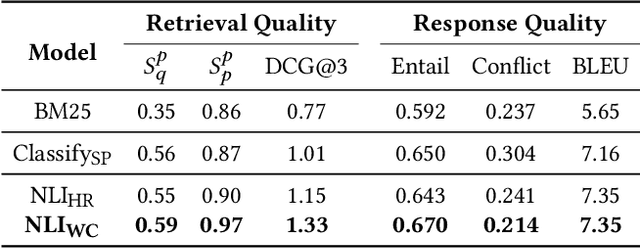
Endowing chatbots with a consistent personality plays a vital role for agents to deliver human-like interactions. However, existing personalized approaches commonly generate responses in light of static predefined personas depicted with textual description, which may severely restrict the interactivity of human and the chatbot, especially when the agent needs to answer the query excluded in the predefined personas, which is so-called out-of-predefined persona problem (named OOP for simplicity). To alleviate the problem, in this paper we propose a novel retrieval-to-prediction paradigm consisting of two subcomponents, namely, (1) Persona Retrieval Model (PRM), it retrieves a persona from a global collection based on a Natural Language Inference (NLI) model, the inferred persona is consistent with the predefined personas; and (2) Posterior-scored Transformer (PS-Transformer), it adopts a persona posterior distribution that further considers the actual personas used in the ground response, maximally mitigating the gap between training and inferring. Furthermore, we present a dataset called IT-ConvAI2 that first highlights the OOP problem in personalized dialogue. Extensive experiments on both IT-ConvAI2 and ConvAI2 demonstrate that our proposed model yields considerable improvements in both automatic metrics and human evaluations.
Multi-view Intent Disentangle Graph Networks for Bundle Recommendation
Feb 23, 2022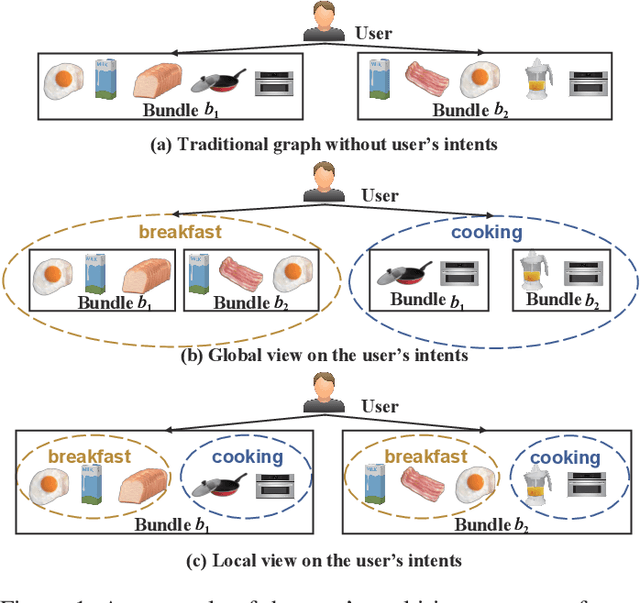
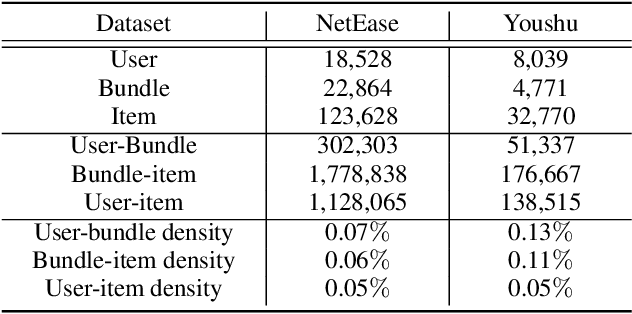
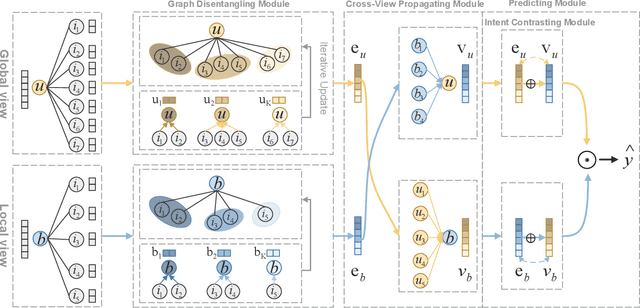
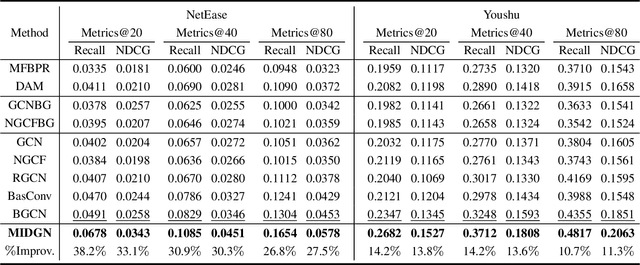
Bundle recommendation aims to recommend the user a bundle of items as a whole. Nevertheless, they usually neglect the diversity of the user's intents on adopting items and fail to disentangle the user's intents in representations. In the real scenario of bundle recommendation, a user's intent may be naturally distributed in the different bundles of that user (Global view), while a bundle may contain multiple intents of a user (Local view). Each view has its advantages for intent disentangling: 1) From the global view, more items are involved to present each intent, which can demonstrate the user's preference under each intent more clearly. 2) From the local view, it can reveal the association among items under each intent since items within the same bundle are highly correlated to each other. To this end, we propose a novel model named Multi-view Intent Disentangle Graph Networks (MIDGN), which is capable of precisely and comprehensively capturing the diversity of the user's intent and items' associations at the finer granularity. Specifically, MIDGN disentangles the user's intents from two different perspectives, respectively: 1) In the global level, MIDGN disentangles the user's intent coupled with inter-bundle items; 2) In the Local level, MIDGN disentangles the user's intent coupled with items within each bundle. Meanwhile, we compare the user's intents disentangled from different views under the contrast learning framework to improve the learned intents. Extensive experiments conducted on two benchmark datasets demonstrate that MIDGN outperforms the state-of-the-art methods by over 10.7% and 26.8%, respectively.
Emotion-aware Chat Machine: Automatic Emotional Response Generation for Human-like Emotional Interaction
Jun 06, 2021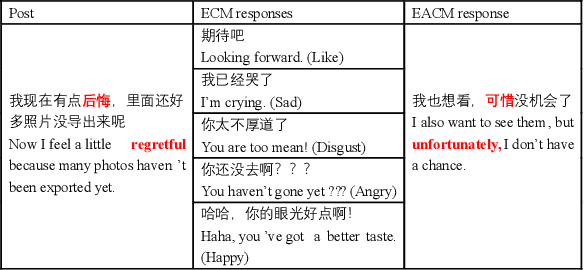
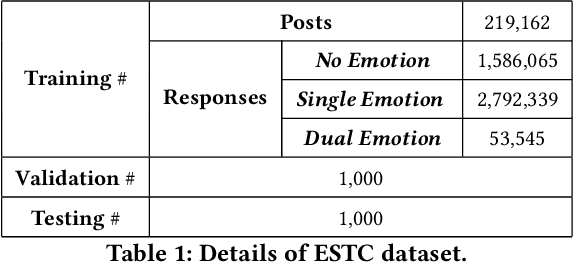
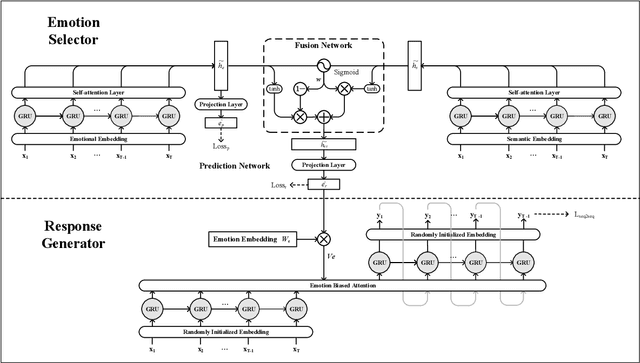
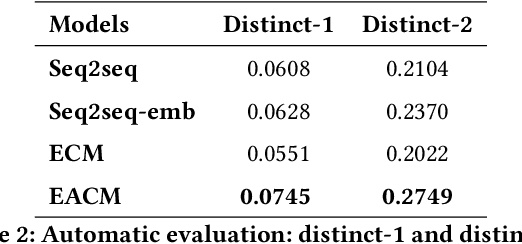
The consistency of a response to a given post at semantic-level and emotional-level is essential for a dialogue system to deliver human-like interactions. However, this challenge is not well addressed in the literature, since most of the approaches neglect the emotional information conveyed by a post while generating responses. This article addresses this problem by proposing a unifed end-to-end neural architecture, which is capable of simultaneously encoding the semantics and the emotions in a post for generating more intelligent responses with appropriately expressed emotions. Extensive experiments on real-world data demonstrate that the proposed method outperforms the state-of-the-art methods in terms of both content coherence and emotion appropriateness.
Exploiting Global Contextual Information for Document-level Named Entity Recognition
Jun 02, 2021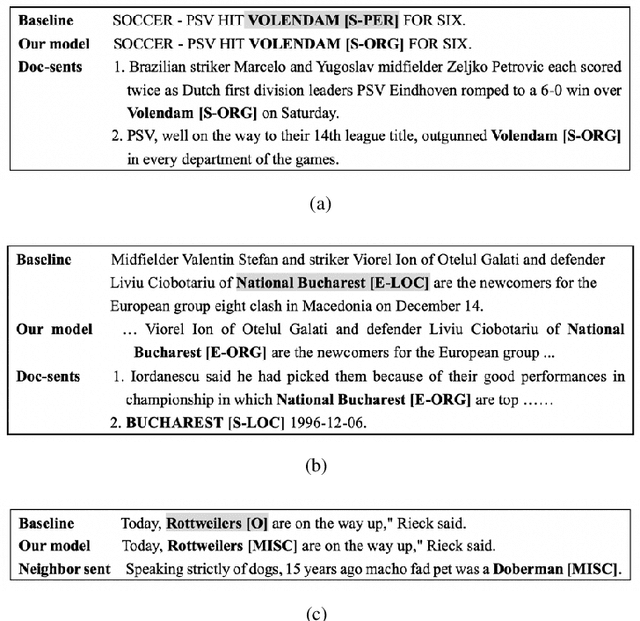
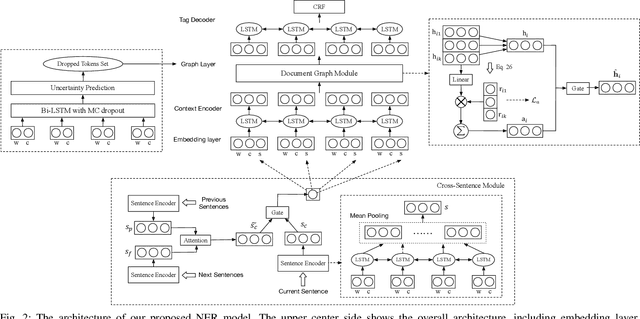

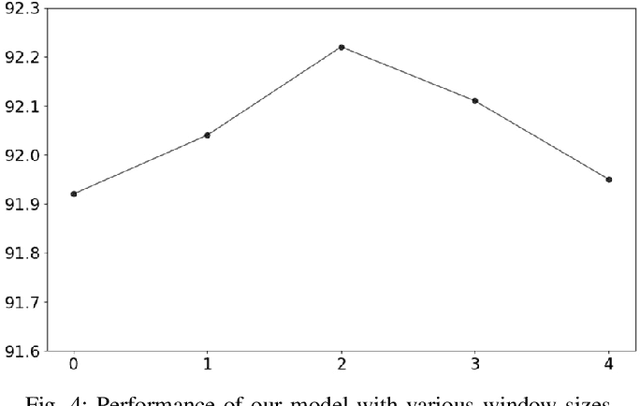
Most existing named entity recognition (NER) approaches are based on sequence labeling models, which focus on capturing the local context dependencies. However, the way of taking one sentence as input prevents the modeling of non-sequential global context, which is useful especially when local context information is limited or ambiguous. To this end, we propose a model called Global Context enhanced Document-level NER (GCDoc) to leverage global contextual information from two levels, i.e., both word and sentence. At word-level, a document graph is constructed to model a wider range of dependencies between words, then obtain an enriched contextual representation for each word via graph neural networks (GNN). To avoid the interference of noise information, we further propose two strategies. First we apply the epistemic uncertainty theory to find out tokens whose representations are less reliable, thereby helping prune the document graph. Then a selective auxiliary classifier is proposed to effectively learn the weight of edges in document graph and reduce the importance of noisy neighbour nodes. At sentence-level, for appropriately modeling wider context beyond single sentence, we employ a cross-sentence module which encodes adjacent sentences and fuses it with the current sentence representation via attention and gating mechanisms. Extensive experiments on two benchmark NER datasets (CoNLL 2003 and Ontonotes 5.0 English dataset) demonstrate the effectiveness of our proposed model. Our model reaches F1 score of 92.22 (93.40 with BERT) on CoNLL 2003 dataset and 88.32 (90.49 with BERT) on Ontonotes 5.0 dataset, achieving new state-of-the-art performance.
Target Guided Emotion Aware Chat Machine
Nov 15, 2020

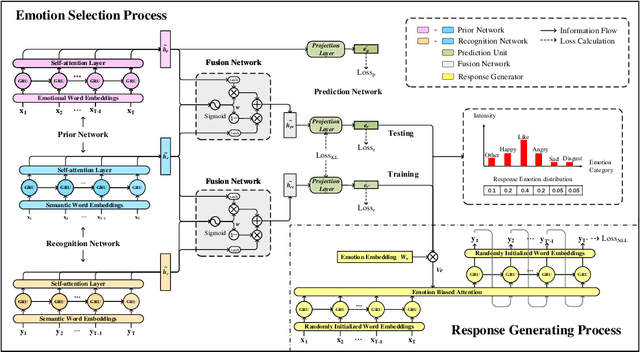
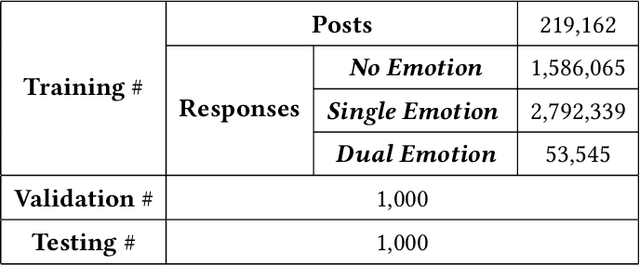
The consistency of a response to a given post at semantic-level and emotional-level is essential for a dialogue system to deliver human-like interactions. However, this challenge is not well addressed in the literature, since most of the approaches neglect the emotional information conveyed by a post while generating responses. This article addresses this problem by proposing a unifed end-to-end neural architecture, which is capable of simultaneously encoding the semantics and the emotions in a post and leverage target information for generating more intelligent responses with appropriately expressed emotions. Extensive experiments on real-world data demonstrate that the proposed method outperforms the state-of-the-art methods in terms of both content coherence and emotion appropriateness.
A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
Nov 13, 2020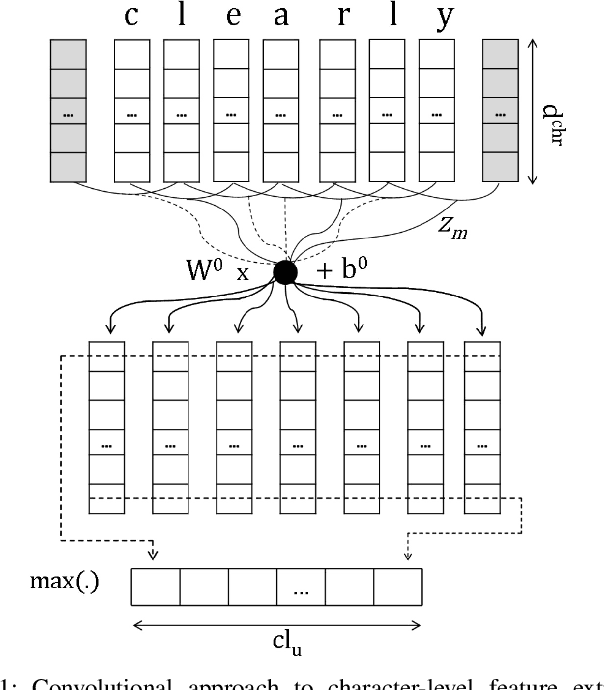
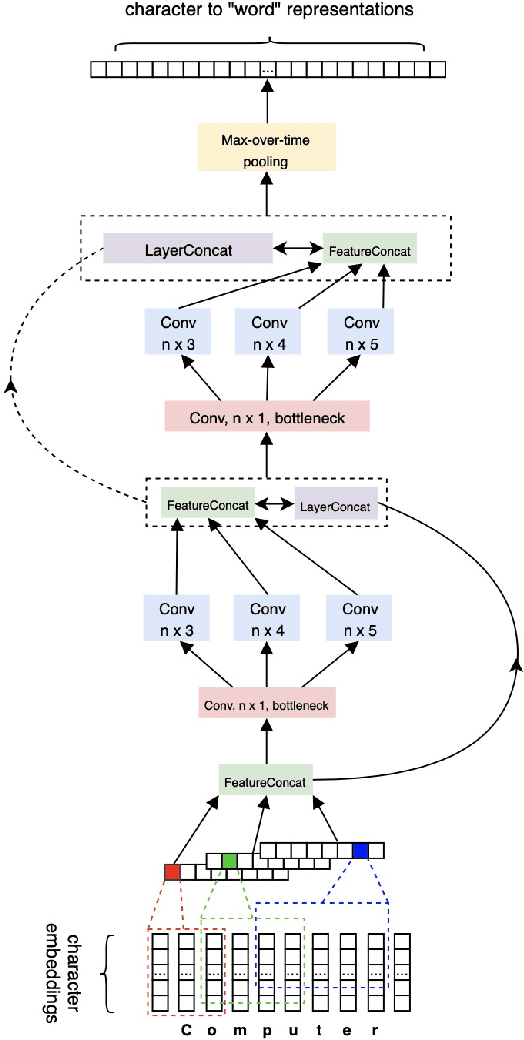
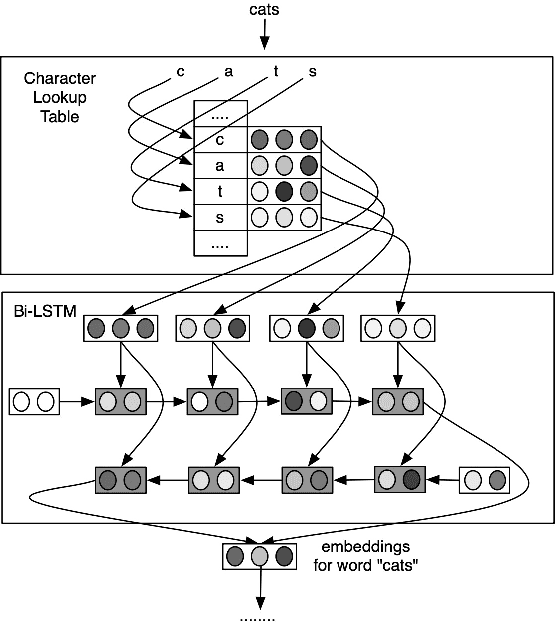
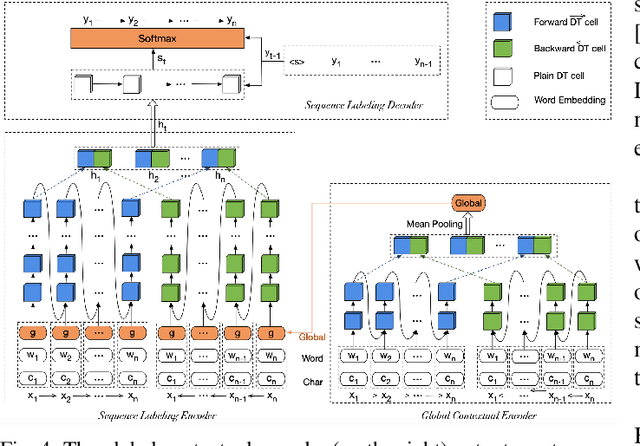
Sequence labeling (SL) is a fundamental research problem encompassing a variety of tasks, e.g., part-of-speech (POS) tagging, named entity recognition (NER), text chunking, etc. Though prevalent and effective in many downstream applications (e.g., information retrieval, question answering, and knowledge graph embedding), conventional sequence labeling approaches heavily rely on hand-crafted or language-specific features. Recently, deep learning has been employed for sequence labeling tasks due to its powerful capability in automatically learning complex features of instances and effectively yielding the stat-of-the-art performances. In this paper, we aim to present a comprehensive review of existing deep learning-based sequence labeling models, which consists of three related tasks, e.g., part-of-speech tagging, named entity recognition, and text chunking. Then, we systematically present the existing approaches base on a scientific taxonomy, as well as the widely-used experimental datasets and popularly-adopted evaluation metrics in the SL domain. Furthermore, we also present an in-depth analysis of different SL models on the factors that may affect the performance and future directions in the SL domain.
STN4DST: A Scalable Dialogue State Tracking based on Slot Tagging Navigation
Oct 21, 2020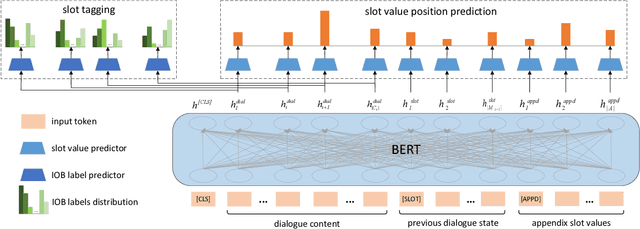


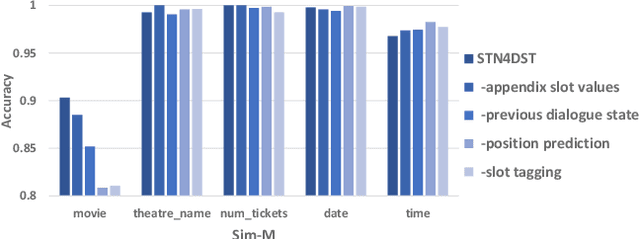
Scalability for handling unknown slot values is a important problem in dialogue state tracking (DST). As far as we know, previous scalable DST approaches generally rely on either the candidate generation from slot tagging output or the span extraction in dialogue context. However, the candidate generation based DST often suffers from error propagation due to its pipelined two-stage process; meanwhile span extraction based DST has the risk of generating invalid spans in the lack of semantic constraints between start and end position pointers. To tackle the above drawbacks, in this paper, we propose a novel scalable dialogue state tracking method based on slot tagging navigation, which implements an end-to-end single-step pointer to locate and extract slot value quickly and accurately by the joint learning of slot tagging and slot value position prediction in the dialogue context, especially for unknown slot values. Extensive experiments over several benchmark datasets show that the proposed model performs better than state-of-the-art baselines greatly.
Learning Relation Ties with a Force-Directed Graph in Distant Supervised Relation Extraction
Apr 21, 2020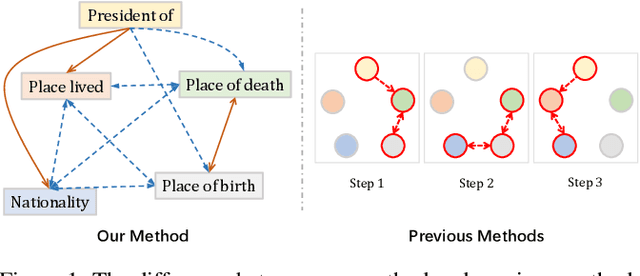

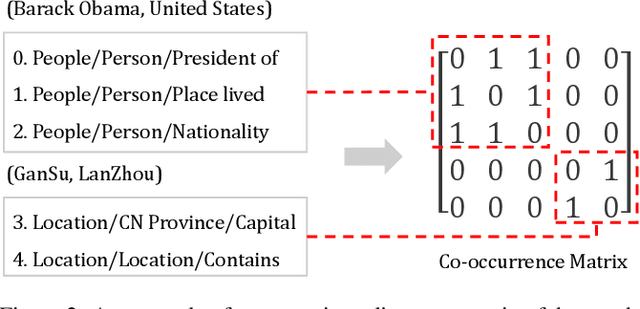
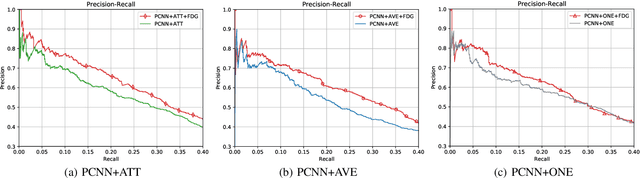
Relation ties, defined as the correlation and mutual exclusion between different relations, are critical for distant supervised relation extraction. Existing approaches model this property by greedily learning local dependencies. However, they are essentially limited by failing to capture the global topology structure of relation ties. As a result, they may easily fall into a locally optimal solution. To solve this problem, in this paper, we propose a novel force-directed graph based relation extraction model to comprehensively learn relation ties. Specifically, we first build a graph according to the global co-occurrence of relations. Then, we borrow the idea of Coulomb's Law from physics and introduce the concept of attractive force and repulsive force to this graph to learn correlation and mutual exclusion between relations. Finally, the obtained relation representations are applied as an inter-dependent relation classifier. Experimental results on a large scale benchmark dataset demonstrate that our model is capable of modeling global relation ties and significantly outperforms other baselines. Furthermore, the proposed force-directed graph can be used as a module to augment existing relation extraction systems and improve their performance.