 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-aware Chat Machine: Automatic Emotional Response Generation for Human-like Emotional Interaction
Jun 06, 2021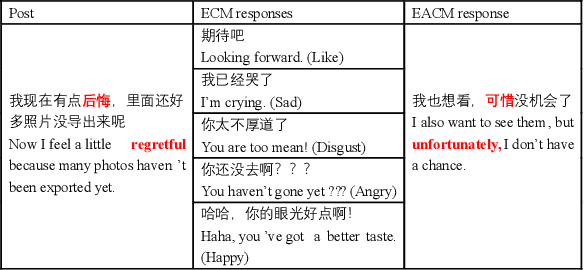
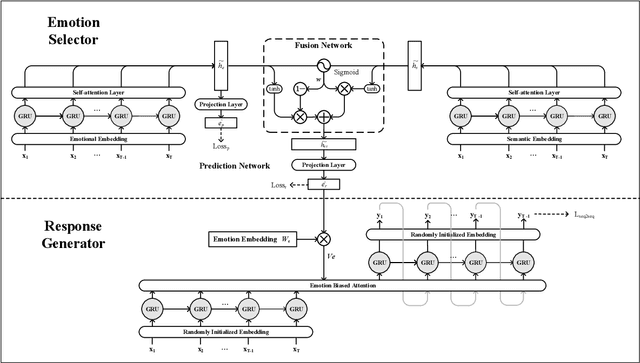
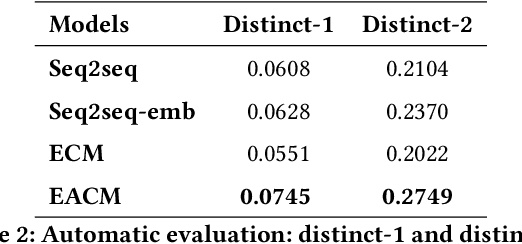
The consistency of a response to a given post at semantic-level and emotional-level is essential for a dialogue system to deliver human-like interactions. However, this challenge is not well addressed in the literature, since most of the approaches neglect the emotional information conveyed by a post while generating responses. This article addresses this problem by proposing a unifed end-to-end neural architecture, which is capable of simultaneously encoding the semantics and the emotions in a post for generating more intelligent responses with appropriately expressed emotions. Extensive experiments on real-world data demonstrate that the proposed method outperforms the state-of-the-art methods in terms of both content coherence and emotion appropriateness.
V3H: Incomplete Multi-view Clustering via View Variation and View Heredity
Nov 23, 2020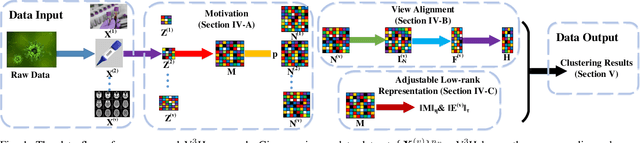
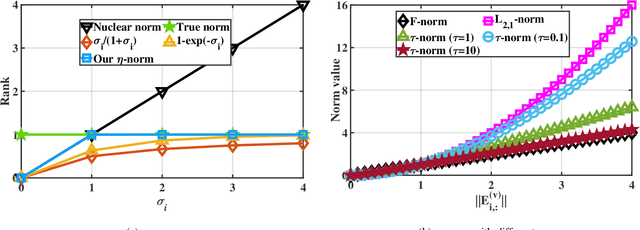
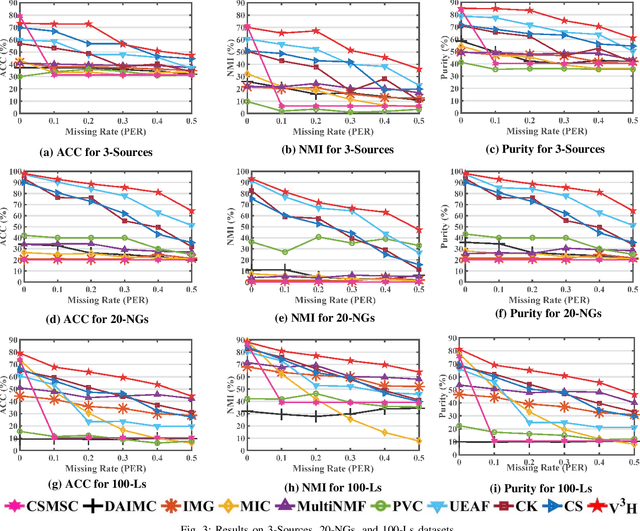
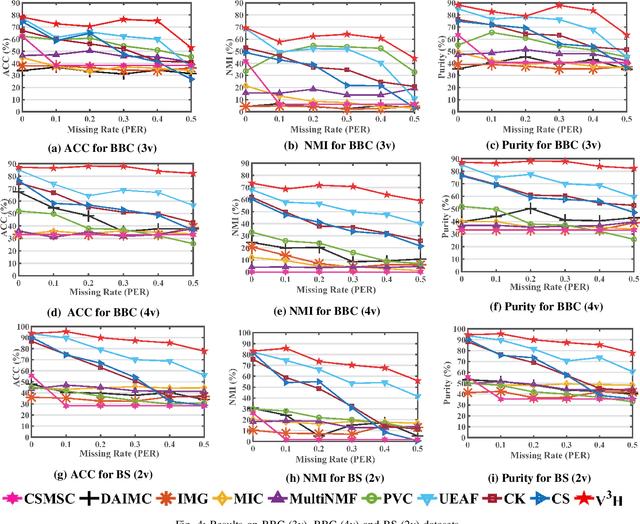
Real data often appear in the form of multiple incomplete views, and incomplete multi-view clustering is an effective method to integrate these incomplete views. Previous methods only learn the consistent information between different views and ignore the unique information of each view, which limits their clustering performance and generalizations. To overcome this limitation, we propose a novel View Variation and View Heredity approach (V 3 H). Inspired by the variation and the heredity in genetics, V 3 H first decomposes each subspace into a variation matrix for the corresponding view and a heredity matrix for all the views to represent the unique information and the consistent information respectively. Then, by aligning different views based on their cluster indicator matrices, V3H integrates the unique information from different views to improve the clustering performance. Finally, with the help of the adjustable low-rank representation based on the heredity matrix, V3H recovers the underlying true data structure to reduce the influence of the large incompleteness. More importantly, V3H presents possibly the first work to introduce genetics to clustering algorithms for learning simultaneously the consistent information and the unique information from incomplete multi-view data. Extensive experimental results on fifteen benchmark datasets validate its superiority over other state-of-the-arts.
Double Self-weighted Multi-view Clustering via Adaptive View Fusion
Nov 20, 2020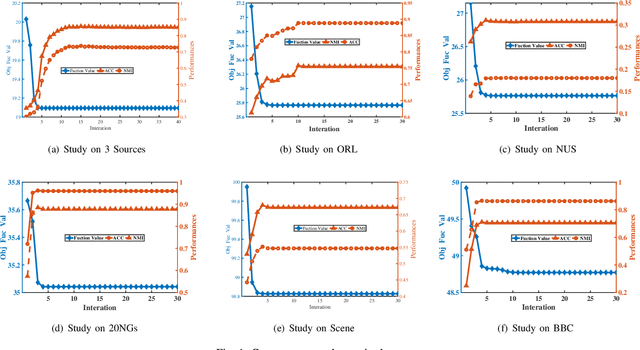
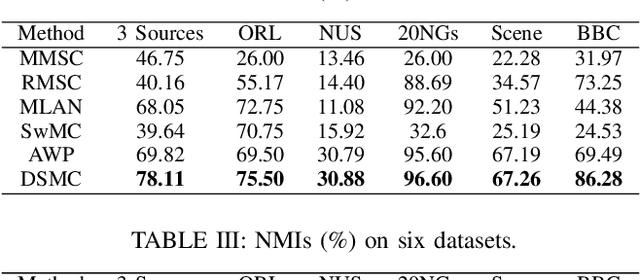
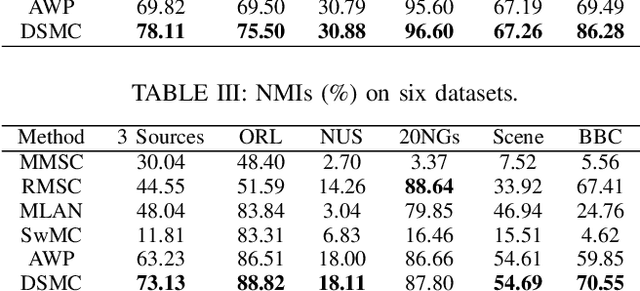
Multi-view clustering has been applied in many real-world applications where original data often contain noises. Some graph-based multi-view clustering methods have been proposed to try to reduce the negative influence of noises. However, previous graph-based multi-view clustering methods treat all features equally even if there are redundant features or noises, which is obviously unreasonable. In this paper, we propose a novel multi-view clustering framework Double Self-weighted Multi-view Clustering (DSMC) to overcome the aforementioned deficiency. DSMC performs double self-weighted operations to remove redundant features and noises from each graph, thereby obtaining robust graphs. For the first self-weighted operation, it assigns different weights to different features by introducing an adaptive weight matrix, which can reinforce the role of the important features in the joint representation and make each graph robust. For the second self-weighting operation, it weights different graphs by imposing an adaptive weight factor, which can assign larger weights to more robust graphs. Furthermore, by designing an adaptive multiple graphs fusion, we can fuse the features in the different graphs to integrate these graphs for clustering. Experiments on six real-world datasets demonstrate its advantages over other state-of-the-art multi-view clustering methods.
ANIMC: A Soft Framework for Auto-weighted Noisy and Incomplete Multi-view Clustering
Nov 20, 2020
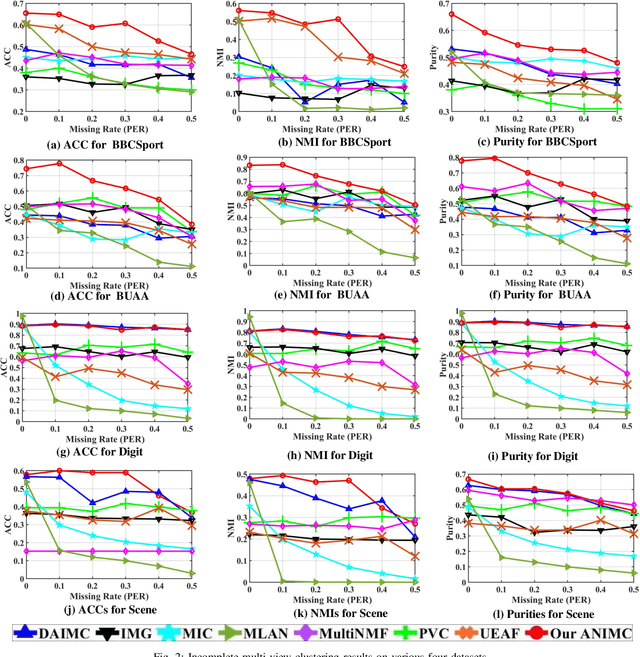
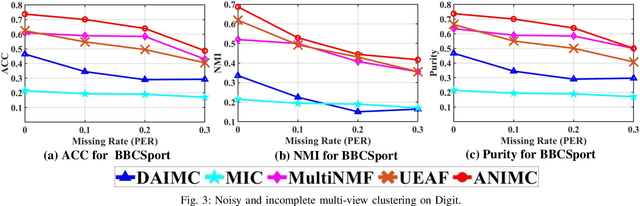
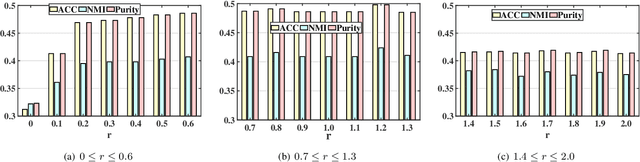
Multi-view clustering has wide applications in many image processing scenarios. In these scenarios, original image data often contain missing instances and noises, which is ignored by most multi-view clustering methods. However, missing instances may make these methods difficult to use directly and noises will lead to unreliable clustering results. In this paper, we propose a novel Auto-weighted Noisy and Incomplete Multi-view Clustering framework (ANIMC) via a soft auto-weighted strategy and a doubly soft regular regression model. Firstly, by designing adaptive semi-regularized nonnegative matrix factorization (adaptive semi-RNMF), the soft auto-weighted strategy assigns a proper weight to each view and adds a soft boundary to balance the influence of noises and incompleteness. Secondly, by proposing{\theta}-norm, the doubly soft regularized regression model adjusts the sparsity of our model by choosing different{\theta}. Compared with existing methods, ANIMC has three unique advantages: 1) it is a soft algorithm to adjust our framework in different scenarios, thereby improving its generalization ability; 2) it automatically learns a proper weight for each view, thereby reducing the influence of noises; 3) it performs doubly soft regularized regression that aligns the same instances in different views, thereby decreasing the impact of missing instances. Extensive experimental results demonstrate its superior advantages over other state-of-the-art methods.
Unbalanced Incomplete Multi-view Clustering via the Scheme of View Evolution: Weak Views are Meat; Strong Views do Eat
Nov 20, 2020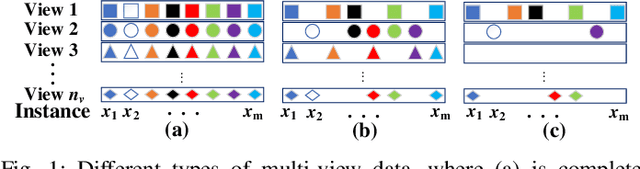
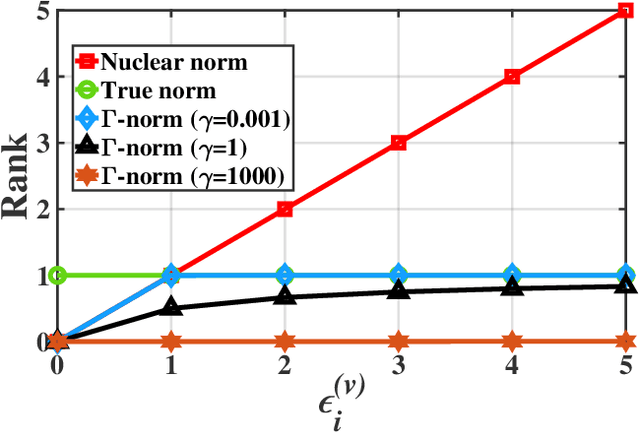
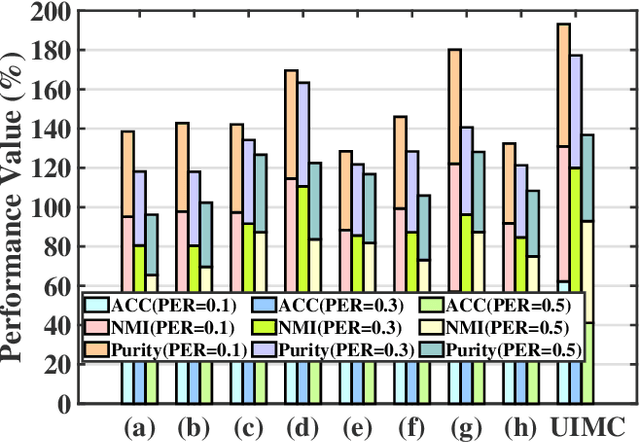
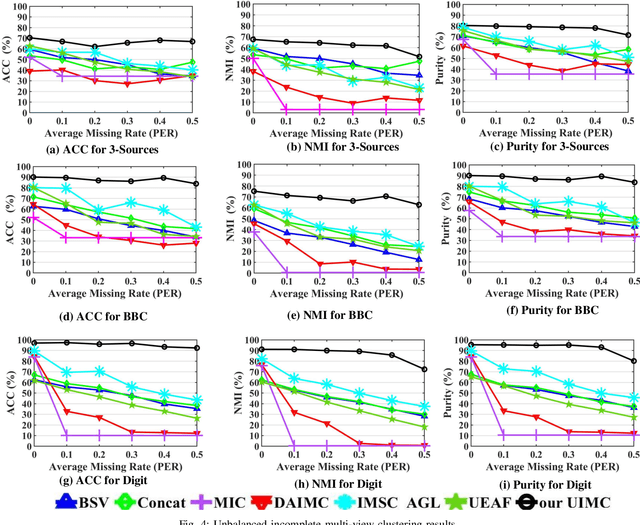
Incomplete multi-view clustering is an important technique to deal with real-world incomplete multi-view data. Previous works assume that all views have the same incompleteness, i.e., balanced incompleteness. However, different views often have distinct incompleteness, i.e., unbalanced incompleteness, which results in strong views (low-incompleteness views) and weak views (high-incompleteness views). The unbalanced incompleteness prevents us from directly using the previous methods for clustering. In this paper, inspired by the effective biological evolution theory, we design the novel scheme of view evolution to cluster strong and weak views. Moreover, we propose an Unbalanced Incomplete Multi-view Clustering method (UIMC), which is the first effective method based on view evolution for unbalanced incomplete multi-view clustering. Compared with previous methods, UIMC has two unique advantages: 1) it proposes weighted multi-view subspace clustering to integrate these unbalanced incomplete views, which effectively solves the unbalanced incomplete multi-view problem; 2) it designs the low-rank and robust representation to recover the data, which diminishes the impact of the incompleteness and noises. Extensive experimental results demonstrate that UIMC improves the clustering performance by up to 40% on three evaluation metrics over other state-of-the-art methods.
Target Guided Emotion Aware Chat Machine
Nov 15, 2020

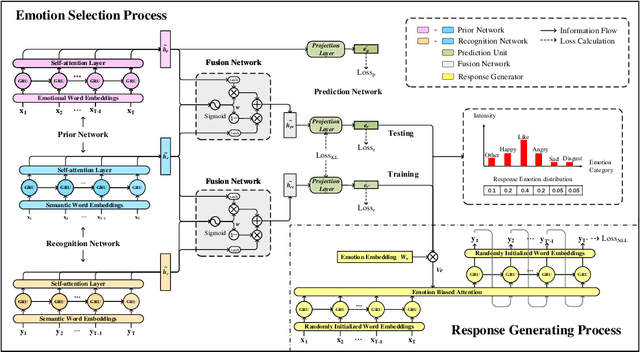
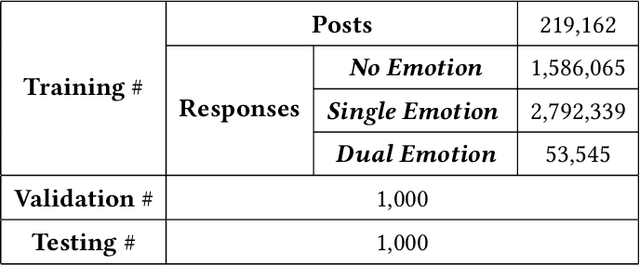
The consistency of a response to a given post at semantic-level and emotional-level is essential for a dialogue system to deliver human-like interactions. However, this challenge is not well addressed in the literature, since most of the approaches neglect the emotional information conveyed by a post while generating responses. This article addresses this problem by proposing a unifed end-to-end neural architecture, which is capable of simultaneously encoding the semantics and the emotions in a post and leverage target information for generating more intelligent responses with appropriately expressed emotions. Extensive experiments on real-world data demonstrate that the proposed method outperforms the state-of-the-art methods in terms of both content coherence and emotion appropriateness.
Context-Aware Online Learning for Course Recommendation of MOOC Big Data
Oct 16, 2016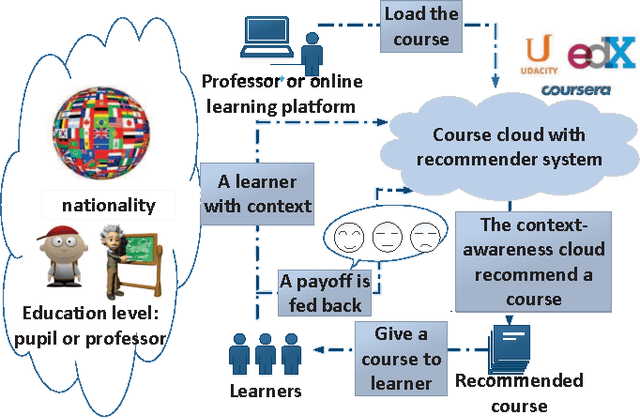
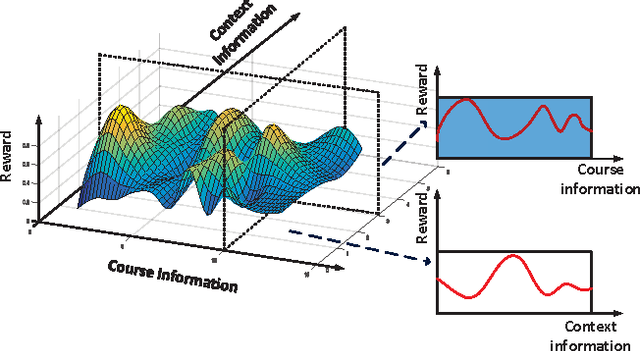
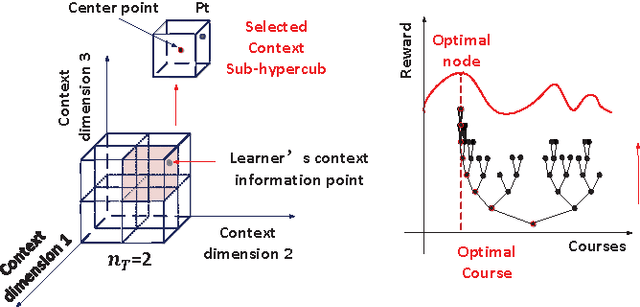
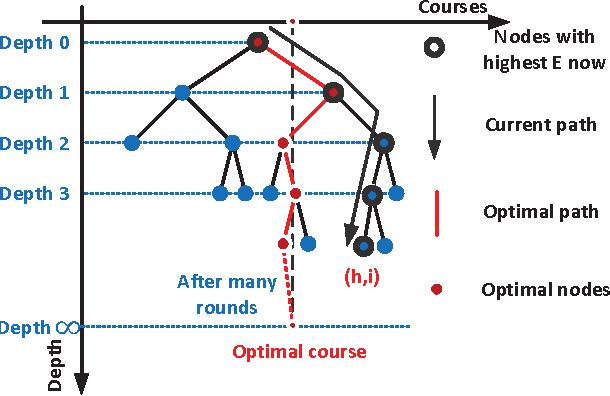
The Massive Open Online Course (MOOC) has expanded significantly in recent years. With the widespread of MOOC, the opportunity to study the fascinating courses for free has attracted numerous people of diverse educational backgrounds all over the world. In the big data era, a key research topic for MOOC is how to mine the needed courses in the massive course databases in cloud for each individual student accurately and rapidly as the number of courses is increasing fleetly. In this respect, the key challenge is how to realize personalized course recommendation as well as to reduce the computing and storage costs for the tremendous course data. In this paper, we propose a big data-supported, context-aware online learning-based course recommender system that could handle the dynamic and infinitely massive datasets, which recommends courses by using personalized context information and historical statistics. The context-awareness takes the personal preferences into consideration, making the recommendation suitable for people with different backgrounds. Besides, the algorithm achieves the sublinear regret performance, which means it can gradually recommend the mostly preferred and matched courses to students. In addition, our storage module is expanded to the distributed-connected storage nodes, where the devised algorithm can handle massive course storage problems from heterogeneous sources of course datasets. Comparing to existing algorithms, our proposed algorithms achieve the linear time complexity and space complexity. Experiment results verify the superiority of our algorithms when comparing with existing ones in the MOOC big data setting.