 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniQ: Unified Decoder with Task-specific Queries for Efficient Scene Graph Generation
Jan 10, 2025



Scene Graph Generation(SGG) is a scene understanding task that aims at identifying object entities and reasoning their relationships within a given image. In contrast to prevailing two-stage methods based on a large object detector (e.g., Faster R-CNN), one-stage methods integrate a fixed-size set of learnable queries to jointly reason relational triplets <subject, predicate, object>. This paradigm demonstrates robust performance with significantly reduced parameters and computational overhead. However, the challenge in one-stage methods stems from the issue of weak entanglement, wherein entities involved in relationships require both coupled features shared within triplets and decoupled visual features. Previous methods either adopt a single decoder for coupled triplet feature modeling or multiple decoders for separate visual feature extraction but fail to consider both. In this paper, we introduce UniQ, a Unified decoder with task-specific Queries architecture, where task-specific queries generate decoupled visual features for subjects, objects, and predicates respectively, and unified decoder enables coupled feature modeling within relational triplets. Experimental results on the Visual Genome dataset demonstrate that UniQ has superior performance to both one-stage and two-stage methods.
On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion
Jun 17, 2024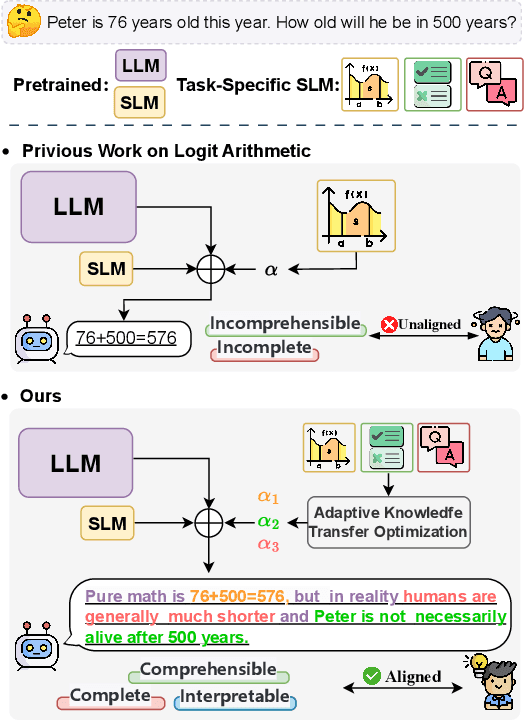
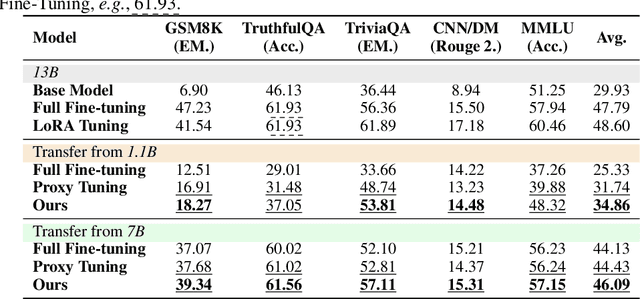
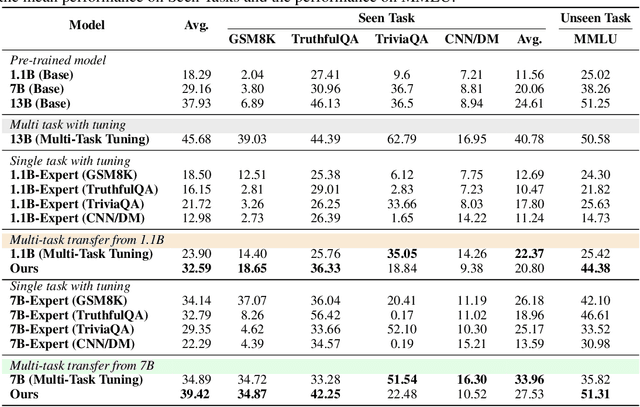
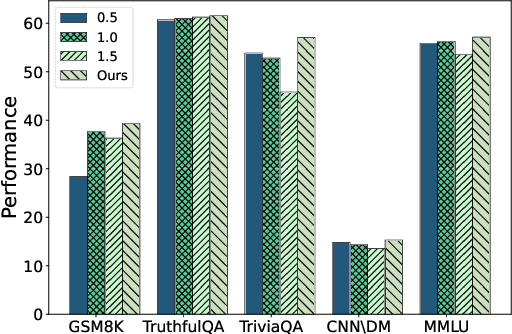
Efficient fine-tuning of large language models for task-specific applications is imperative, yet the vast number of parameters in these models makes their training increasingly challenging. Despite numerous proposals for effective methods, a substantial memory overhead remains for gradient computations during updates. \thm{Can we fine-tune a series of task-specific small models and transfer their knowledge directly to a much larger model without additional training?} In this paper, we explore weak-to-strong specialization using logit arithmetic, facilitating a direct answer to this question. Existing weak-to-strong methods often employ a static knowledge transfer ratio and a single small model for transferring complex knowledge, which leads to suboptimal performance. % To address this, To surmount these limitations, we propose a dynamic logit fusion approach that works with a series of task-specific small models, each specialized in a different task. This method adaptively allocates weights among these models at each decoding step, learning the weights through Kullback-Leibler divergence constrained optimization problems. We conduct extensive experiments across various benchmarks in both single-task and multi-task settings, achieving leading results. By transferring expertise from the 7B model to the 13B model, our method closes the performance gap by 96.4\% in single-task scenarios and by 86.3\% in multi-task scenarios compared to full fine-tuning of the 13B model. Notably, we achieve surpassing performance on unseen tasks. Moreover, we further demonstrate that our method can effortlessly integrate in-context learning for single tasks and task arithmetic for multi-task scenarios. (Our implementation is available in https://github.com/Facico/Dynamic-Logit-Fusion.)
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Jun 17, 2024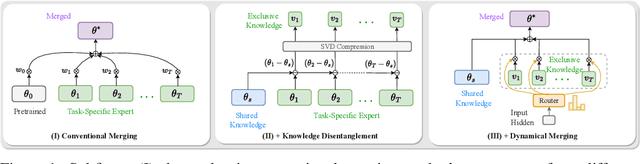
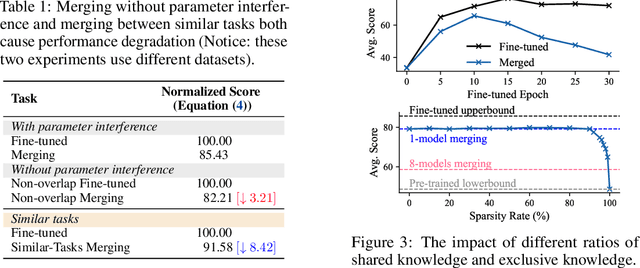
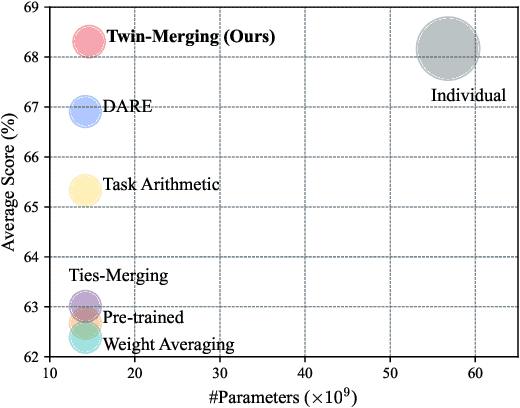
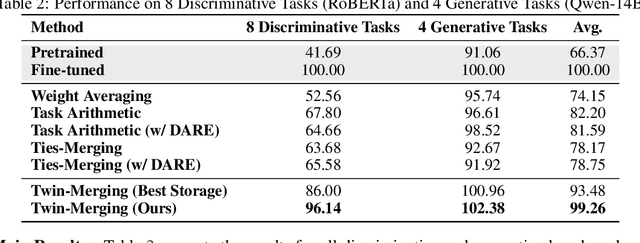
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34\%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
Mitigating Boundary Ambiguity and Inherent Bias for Text Classification in the Era of Large Language Models
Jun 11, 2024



Text classification is a crucial task encountered frequently in practical scenarios, yet it is still under-explored in the era of large language models (LLMs). This study shows that LLMs are vulnerable to changes in the number and arrangement of options in text classification. Our extensive empirical analyses reveal that the key bottleneck arises from ambiguous decision boundaries and inherent biases towards specific tokens and positions. To mitigate these issues, we make the first attempt and propose a novel two-stage classification framework for LLMs. Our approach is grounded in the empirical observation that pairwise comparisons can effectively alleviate boundary ambiguity and inherent bias. Specifically, we begin with a self-reduction technique to efficiently narrow down numerous options, which contributes to reduced decision space and a faster comparison process. Subsequently, pairwise contrastive comparisons are employed in a chain-of-thought manner to draw out nuances and distinguish confusable options, thus refining the ambiguous decision boundary. Extensive experiments on four datasets (Banking77, HWU64, LIU54, and Clinic150) verify the effectiveness of our framework. Furthermore, benefitting from our framework, various LLMs can achieve consistent improvements. Our code and data are available in \url{https://github.com/Chuge0335/PC-CoT}.
Position Debiasing Fine-Tuning for Causal Perception in Long-Term Dialogue
Jun 04, 2024



The core of the dialogue system is to generate relevant, informative, and human-like responses based on extensive dialogue history. Recently, dialogue generation domain has seen mainstream adoption of large language models (LLMs), due to its powerful capability in generating utterances. However, there is a natural deficiency for such models, that is, inherent position bias, which may lead them to pay more attention to the nearby utterances instead of causally relevant ones, resulting in generating irrelevant and generic responses in long-term dialogue. To alleviate such problem, in this paper, we propose a novel method, named Causal Perception long-term Dialogue framework (CPD), which employs perturbation-based causal variable discovery method to extract casually relevant utterances from the dialogue history and enhances model causal perception during fine-tuning. Specifically, a local-position awareness method is proposed in CPD for inter-sentence position correlation elimination, which helps models extract causally relevant utterances based on perturbations. Then, a casual-perception fine-tuning strategy is also proposed, to enhance the capability of discovering the causal invariant factors, by differently perturbing causally relevant and non-casually relevant ones for response generation. Experimental results on two datasets prove that our proposed method can effectively alleviate the position bias for multiple LLMs and achieve significant progress compared with existing baselines.
Personalized Topic Selection Model for Topic-Grounded Dialogue
Jun 04, 2024Recently, the topic-grounded dialogue (TGD) system has become increasingly popular as its powerful capability to actively guide users to accomplish specific tasks through topic-guided conversations. Most existing works utilize side information (\eg topics or personas) in isolation to enhance the topic selection ability. However, due to disregarding the noise within these auxiliary information sources and their mutual influence, current models tend to predict user-uninteresting and contextually irrelevant topics. To build user-engaging and coherent dialogue agent, we propose a \textbf{P}ersonalized topic s\textbf{E}lection model for \textbf{T}opic-grounded \textbf{D}ialogue, named \textbf{PETD}, which takes account of the interaction of side information to selectively aggregate such information for more accurately predicting subsequent topics. Specifically, we evaluate the correlation between global topics and personas and selectively incorporate the global topics aligned with user personas. Furthermore, we propose a contrastive learning based persona selector to filter out irrelevant personas under the constraint of lacking pertinent persona annotations. Throughout the selection and generation, diverse relevant side information is considered. Extensive experiments demonstrate that our proposed method can generate engaging and diverse responses, outperforming state-of-the-art baselines across various evaluation metrics.
Improving Pseudo Labels with Global-Local Denoising Framework for Cross-lingual Named Entity Recognition
Jun 03, 2024



Cross-lingual named entity recognition (NER) aims to train an NER model for the target language leveraging only labeled source language data and unlabeled target language data. Prior approaches either perform label projection on translated source language data or employ a source model to assign pseudo labels for target language data and train a target model on these pseudo-labeled data to generalize to the target language. However, these automatic labeling procedures inevitably introduce noisy labels, thus leading to a performance drop. In this paper, we propose a Global-Local Denoising framework (GLoDe) for cross-lingual NER. Specifically, GLoDe introduces a progressive denoising strategy to rectify incorrect pseudo labels by leveraging both global and local distribution information in the semantic space. The refined pseudo-labeled target language data significantly improves the model's generalization ability. Moreover, previous methods only consider improving the model with language-agnostic features, however, we argue that target language-specific features are also important and should never be ignored. To this end, we employ a simple auxiliary task to achieve this goal. Experimental results on two benchmark datasets with six target languages demonstrate that our proposed GLoDe significantly outperforms current state-of-the-art methods.
Reinforcement Learning with Token-level Feedback for Controllable Text Generation
Mar 18, 2024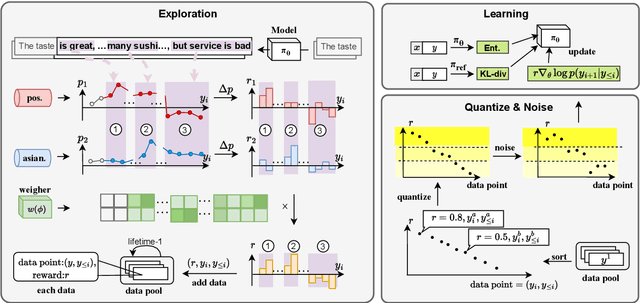
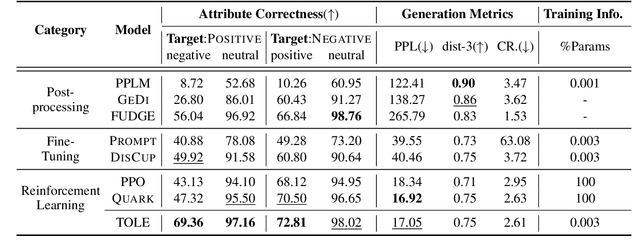
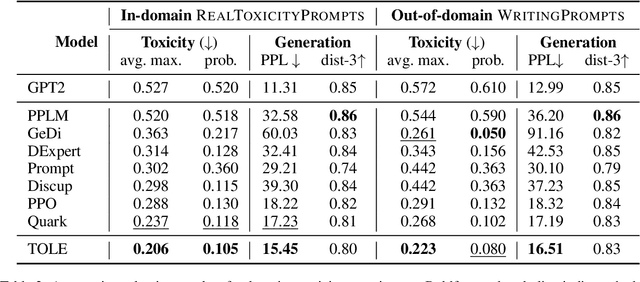
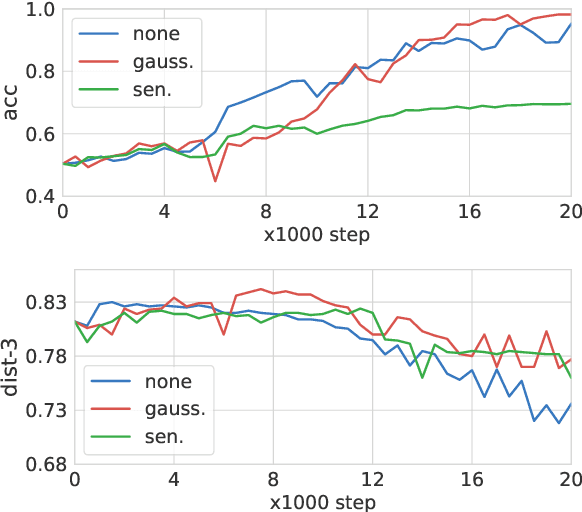
To meet the requirements of real-world applications, it is essential to control generations of large language models (LLMs). Prior research has tried to introduce reinforcement learning (RL) into controllable text generation while most existing methods suffer from overfitting issues (finetuning-based methods) or semantic collapse (post-processing methods). However, current RL methods are generally guided by coarse-grained (sentence/paragraph-level) feedback, which may lead to suboptimal performance owing to semantic twists or progressions within sentences. To tackle that, we propose a novel reinforcement learning algorithm named TOLE which formulates TOken-LEvel rewards for controllable text generation, and employs a "first-quantize-then-noise" paradigm to enhance the robustness of the RL algorithm.Furthermore, TOLE can be flexibly extended to multiple constraints with little computational expense. Experimental results show that our algorithm can achieve superior performance on both single-attribute and multi-attribute control tasks. We have released our codes at https://github.com/WindyLee0822/CTG
Improving Low-resource Prompt-based Relation Representation with Multi-view Decoupling Learning
Jan 15, 2024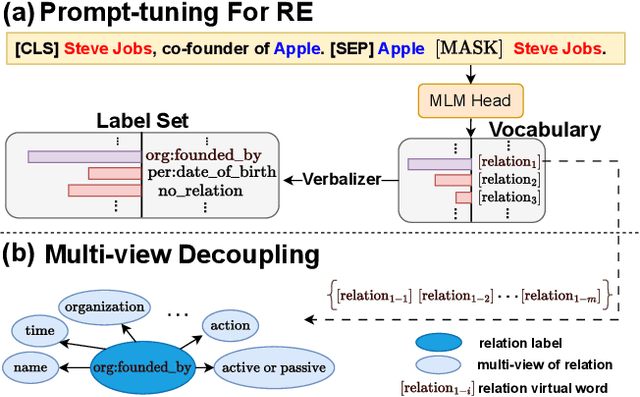
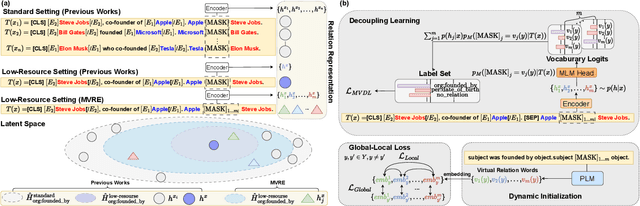
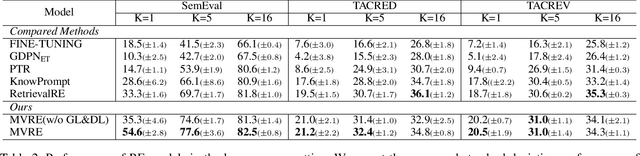
Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (\underline{M}ulti-\underline{V}iew \underline{R}elation \underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
Joint Multi-Facts Reasoning Network For Complex Temporal Question Answering Over Knowledge Graph
Jan 04, 2024Temporal Knowledge Graph (TKG) is an extension of regular knowledge graph by attaching the time scope. Existing temporal knowledge graph question answering (TKGQA) models solely approach simple questions, owing to the prior assumption that each question only contains a single temporal fact with explicit/implicit temporal constraints. Hence, they perform poorly on questions which own multiple temporal facts. In this paper, we propose \textbf{\underline{J}}oint \textbf{\underline{M}}ulti \textbf{\underline{F}}acts \textbf{\underline{R}}easoning \textbf{\underline{N}}etwork (JMFRN), to jointly reasoning multiple temporal facts for accurately answering \emph{complex} temporal questions. Specifically, JMFRN first retrieves question-related temporal facts from TKG for each entity of the given complex question. For joint reasoning, we design two different attention (\ie entity-aware and time-aware) modules, which are suitable for universal settings, to aggregate entities and timestamps information of retrieved facts. Moreover, to filter incorrect type answers, we introduce an additional answer type discrimination task. Extensive experiments demonstrate our proposed method significantly outperforms the state-of-art on the well-known complex temporal question benchmark TimeQuestions.