 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniQ: Unified Decoder with Task-specific Queries for Efficient Scene Graph Generation
Jan 10, 2025



Scene Graph Generation(SGG) is a scene understanding task that aims at identifying object entities and reasoning their relationships within a given image. In contrast to prevailing two-stage methods based on a large object detector (e.g., Faster R-CNN), one-stage methods integrate a fixed-size set of learnable queries to jointly reason relational triplets <subject, predicate, object>. This paradigm demonstrates robust performance with significantly reduced parameters and computational overhead. However, the challenge in one-stage methods stems from the issue of weak entanglement, wherein entities involved in relationships require both coupled features shared within triplets and decoupled visual features. Previous methods either adopt a single decoder for coupled triplet feature modeling or multiple decoders for separate visual feature extraction but fail to consider both. In this paper, we introduce UniQ, a Unified decoder with task-specific Queries architecture, where task-specific queries generate decoupled visual features for subjects, objects, and predicates respectively, and unified decoder enables coupled feature modeling within relational triplets. Experimental results on the Visual Genome dataset demonstrate that UniQ has superior performance to both one-stage and two-stage methods.
Detection-based Intermediate Supervision for Visual Question Answering
Dec 26, 2023



Recently, neural module networks (NMNs) have yielded ongoing success in answering compositional visual questions, especially those involving multi-hop visual and logical reasoning. NMNs decompose the complex question into several sub-tasks using instance-modules from the reasoning paths of that question and then exploit intermediate supervisions to guide answer prediction, thereby improving inference interpretability. However, their performance may be hindered due to sketchy modeling of intermediate supervisions. For instance, (1) a prior assumption that each instance-module refers to only one grounded object yet overlooks other potentially associated grounded objects, impeding full cross-modal alignment learning; (2) IoU-based intermediate supervisions may introduce noise signals as the bounding box overlap issue might guide the model's focus towards irrelevant objects. To address these issues, a novel method, \textbf{\underline{D}}etection-based \textbf{\underline{I}}ntermediate \textbf{\underline{S}}upervision (DIS), is proposed, which adopts a generative detection framework to facilitate multiple grounding supervisions via sequence generation. As such, DIS offers more comprehensive and accurate intermediate supervisions, thereby boosting answer prediction performance. Furthermore, by considering intermediate results, DIS enhances the consistency in answering compositional questions and their sub-questions.Extensive experiments demonstrate the superiority of our proposed DIS, showcasing both improved accuracy and state-of-the-art reasoning consistency compared to prior approaches.
An Empirical Study on the Language Modal in Visual Question Answering
May 17, 2023



Generalization beyond in-domain experience to out-of-distribution data is of paramount significance in the AI domain. Of late, state-of-the-art Visual Question Answering (VQA) models have shown impressive performance on in-domain data, partially due to the language priors bias which, however, hinders the generalization ability in practice. This paper attempts to provide new insights into the influence of language modality on VQA performance from an empirical study perspective. To achieve this, we conducted a series of experiments on six models. The results of these experiments revealed that, 1) apart from prior bias caused by question types, there is a notable influence of postfix-related bias in inducing biases, and 2) training VQA models with word-sequence-related variant questions demonstrated improved performance on the out-of-distribution benchmark, and the LXMERT even achieved a 10-point gain without adopting any debiasing methods. We delved into the underlying reasons behind these experimental results and put forward some simple proposals to reduce the models' dependency on language priors. The experimental results demonstrated the effectiveness of our proposed method in improving performance on the out-of-distribution benchmark, VQA-CPv2. We hope this study can inspire novel insights for future research on designing bias-reduction approaches.
STAGE: Span Tagging and Greedy Inference Scheme for Aspect Sentiment Triplet Extraction
Nov 29, 2022
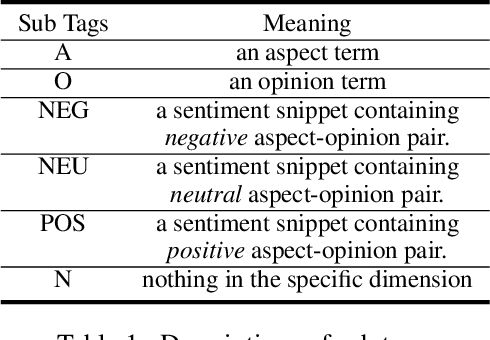


Aspect Sentiment Triplet Extraction (ASTE) has become an emerging task in sentiment analysis research, aiming to extract triplets of the aspect term, its corresponding opinion term, and its associated sentiment polarity from a given sentence. Recently, many neural networks based models with different tagging schemes have been proposed, but almost all of them have their limitations: heavily relying on 1) prior assumption that each word is only associated with a single role (e.g., aspect term, or opinion term, etc. ) and 2) word-level interactions and treating each opinion/aspect as a set of independent words. Hence, they perform poorly on the complex ASTE task, such as a word associated with multiple roles or an aspect/opinion term with multiple words. Hence, we propose a novel approach, Span TAgging and Greedy infErence (STAGE), to extract sentiment triplets in span-level, where each span may consist of multiple words and play different roles simultaneously. To this end, this paper formulates the ASTE task as a multi-class span classification problem. Specifically, STAGE generates more accurate aspect sentiment triplet extractions via exploring span-level information and constraints, which consists of two components, namely, span tagging scheme and greedy inference strategy. The former tag all possible candidate spans based on a newly-defined tagging set. The latter retrieves the aspect/opinion term with the maximum length from the candidate sentiment snippet to output sentiment triplets. Furthermore, we propose a simple but effective model based on the STAGE, which outperforms the state-of-the-arts by a large margin on four widely-used datasets. Moreover, our STAGE can be easily generalized to other pair/triplet extraction tasks, which also demonstrates the superiority of the proposed scheme STAGE.
End-to-end speaker diarization with transformer
Dec 14, 2021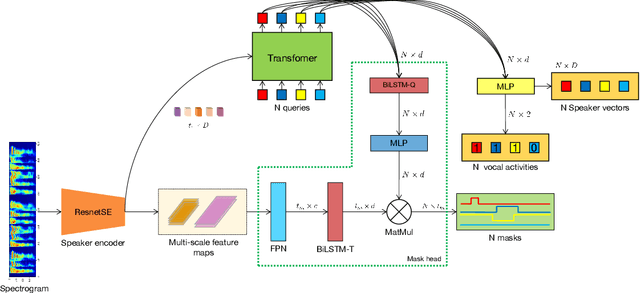

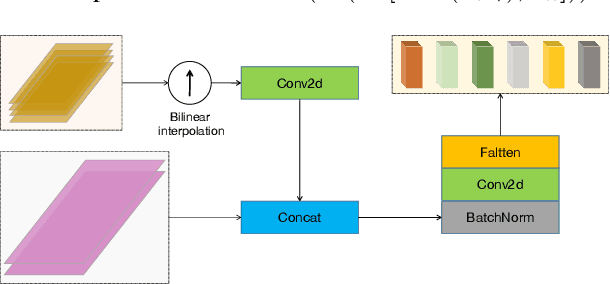
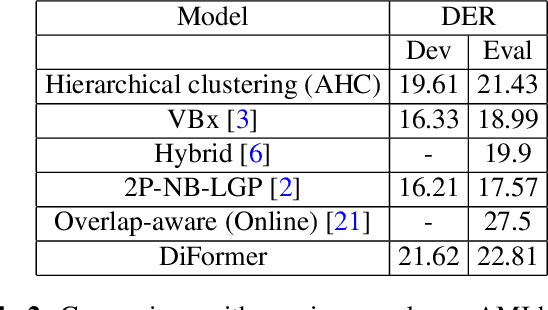
Speaker diarization is connected to semantic segmentation in computer vision. Inspired from MaskFormer \cite{cheng2021per} which treats semantic segmentation as a set-prediction problem, we propose an end-to-end approach to predict a set of targets consisting of binary masks, vocal activities and speaker vectors. Our model, which we coin \textit{DiFormer}, is mainly based on a speaker encoder and a feature pyramid network (FPN) module to extract multi-scale speaker features which are then fed into a transformer encoder-decoder to predict a set of diarization targets from learned query embedding. To account for temporal characteristics of speech signal, bidirectional LSTMs are inserted into the mask prediction module to improve temporal consistency. Our model handles unknown number of speakers, speech overlaps, as well as vocal activity detection in a unified way. Experiments on multimedia and meeting datasets demonstrate the effectiveness of our approach.
Visual-Semantic Transformer for Scene Text Recognition
Dec 02, 2021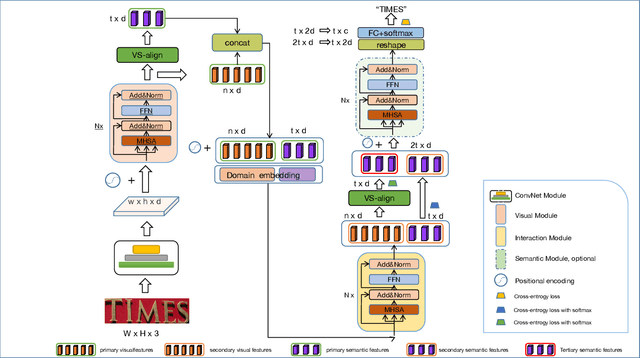
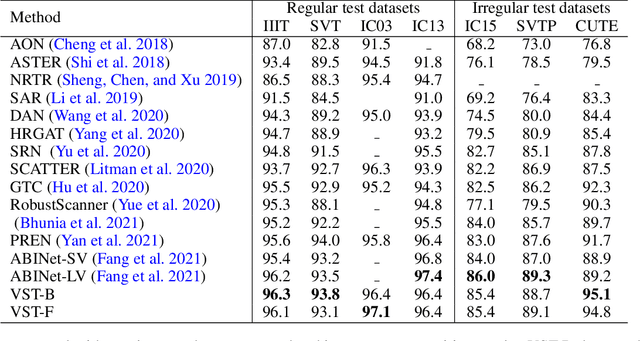
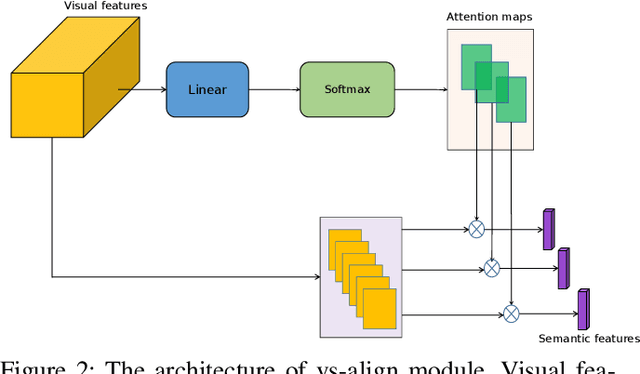
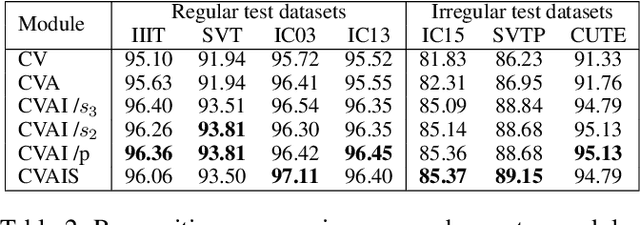
Modeling semantic information is helpful for scene text recognition. In this work, we propose to model semantic and visual information jointly with a Visual-Semantic Transformer (VST). The VST first explicitly extracts primary semantic information from visual feature maps with a transformer module and a primary visual-semantic alignment module. The semantic information is then joined with the visual feature maps (viewed as a sequence) to form a pseudo multi-domain sequence combining visual and semantic information, which is subsequently fed into an transformer-based interaction module to enable learning of interactions between visual and semantic features. In this way, the visual features can be enhanced by the semantic information and vice versus. The enhanced version of visual features are further decoded by a secondary visual-semantic alignment module which shares weights with the primary one. Finally, the decoded visual features and the enhanced semantic features are jointly processed by the third transformer module obtaining the final text prediction. Experiments on seven public benchmarks including regular/ irregular text recognition datasets verifies the effectiveness our proposed model, reaching state of the art on four of the seven benchmarks.