 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Semantic Transformer for Scene Text Recognition
Paper and Code
Dec 02, 2021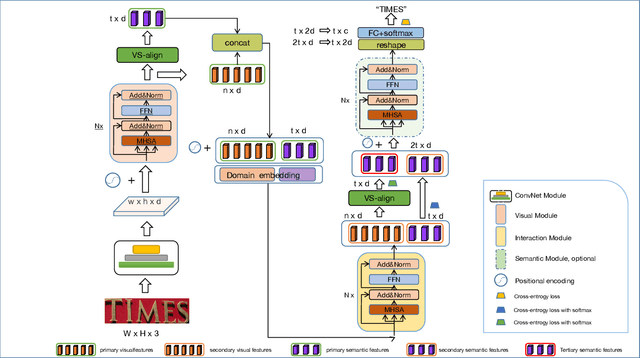
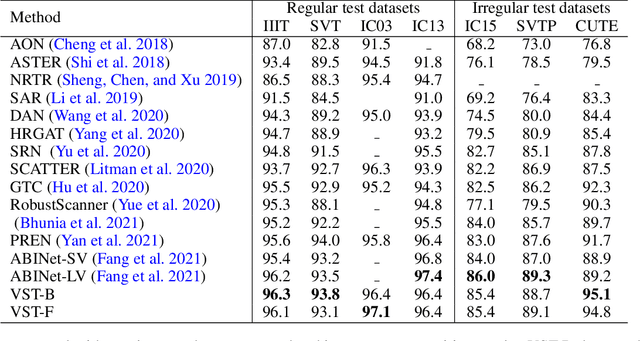
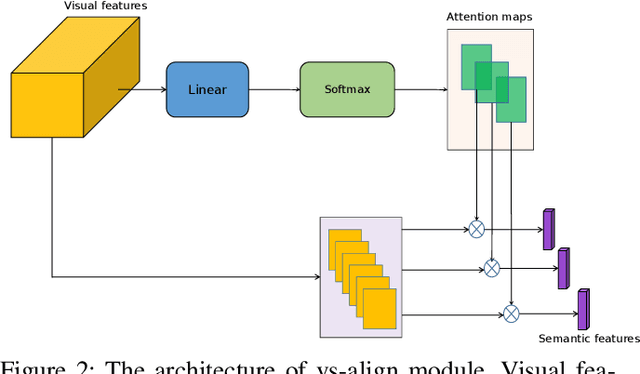
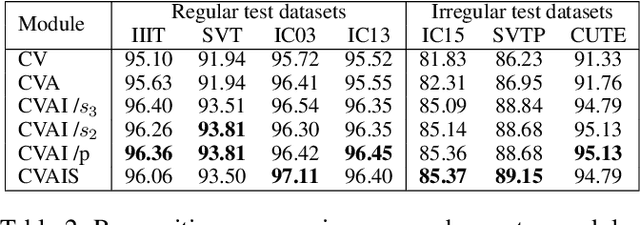
Modeling semantic information is helpful for scene text recognition. In this work, we propose to model semantic and visual information jointly with a Visual-Semantic Transformer (VST). The VST first explicitly extracts primary semantic information from visual feature maps with a transformer module and a primary visual-semantic alignment module. The semantic information is then joined with the visual feature maps (viewed as a sequence) to form a pseudo multi-domain sequence combining visual and semantic information, which is subsequently fed into an transformer-based interaction module to enable learning of interactions between visual and semantic features. In this way, the visual features can be enhanced by the semantic information and vice versus. The enhanced version of visual features are further decoded by a secondary visual-semantic alignment module which shares weights with the primary one. Finally, the decoded visual features and the enhanced semantic features are jointly processed by the third transformer module obtaining the final text prediction. Experiments on seven public benchmarks including regular/ irregular text recognition datasets verifies the effectiveness our proposed model, reaching state of the art on four of the seven benchmarks.