 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASH at TREC 2021 Deep Learning Track: Generative Enhanced Model for Multi-stage Ranking
May 24, 2022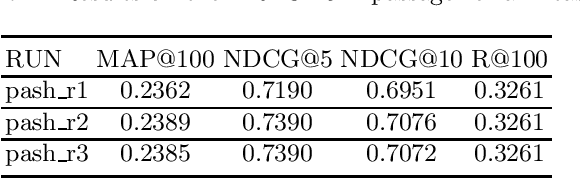
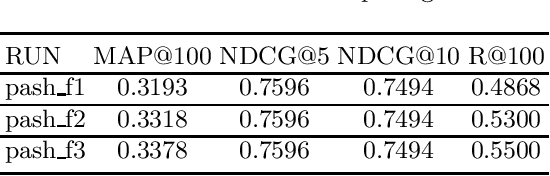
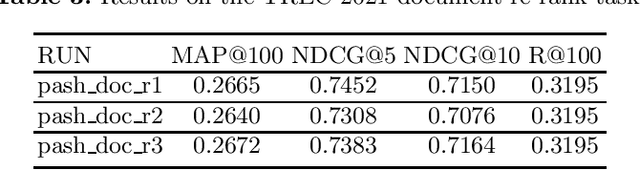
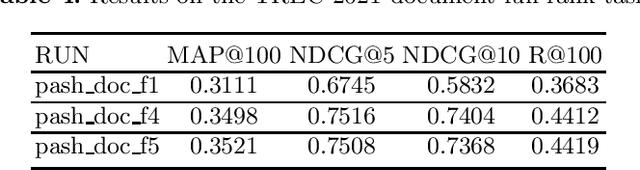
This paper describes the PASH participation in TREC 2021 Deep Learning Track. In the recall stage, we adopt a scheme combining sparse and dense retrieval method. In the multi-stage ranking phase, point-wise and pair-wise ranking strategies are used one after another based on model continual pre-trained on general knowledge and document-level data. Compared to TREC 2020 Deep Learning Track, we have additionally introduced the generative model T5 to further enhance the performance.
End-to-end speaker diarization with transformer
Dec 14, 2021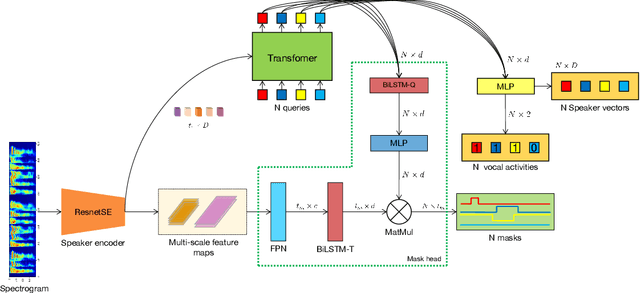

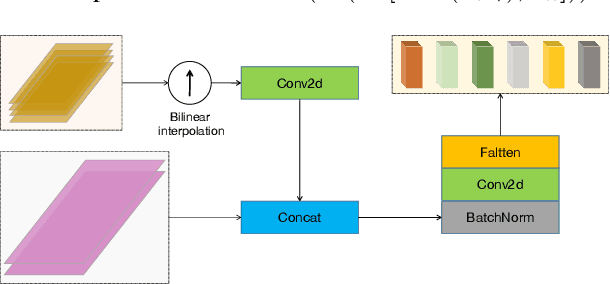
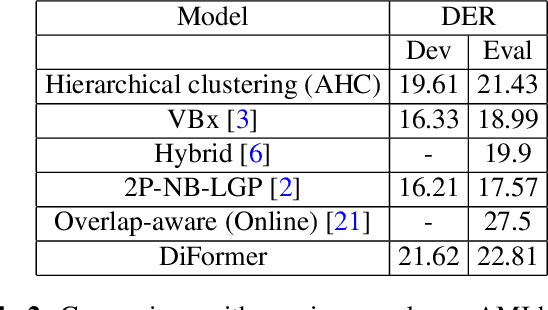
Speaker diarization is connected to semantic segmentation in computer vision. Inspired from MaskFormer \cite{cheng2021per} which treats semantic segmentation as a set-prediction problem, we propose an end-to-end approach to predict a set of targets consisting of binary masks, vocal activities and speaker vectors. Our model, which we coin \textit{DiFormer}, is mainly based on a speaker encoder and a feature pyramid network (FPN) module to extract multi-scale speaker features which are then fed into a transformer encoder-decoder to predict a set of diarization targets from learned query embedding. To account for temporal characteristics of speech signal, bidirectional LSTMs are inserted into the mask prediction module to improve temporal consistency. Our model handles unknown number of speakers, speech overlaps, as well as vocal activity detection in a unified way. Experiments on multimedia and meeting datasets demonstrate the effectiveness of our approach.
Visual-Semantic Transformer for Scene Text Recognition
Dec 02, 2021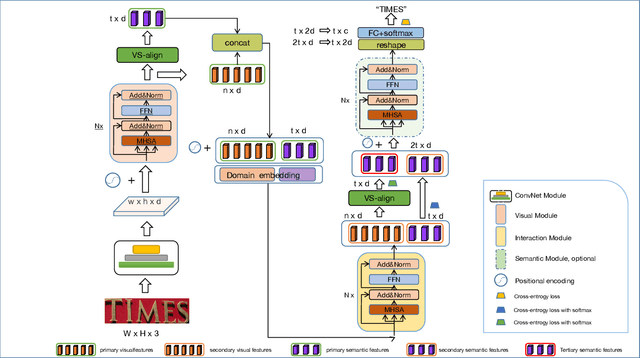
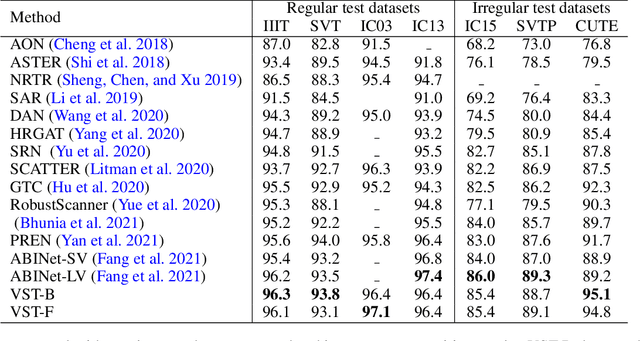
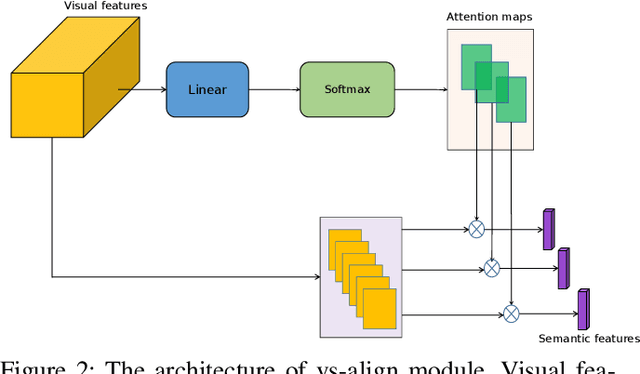
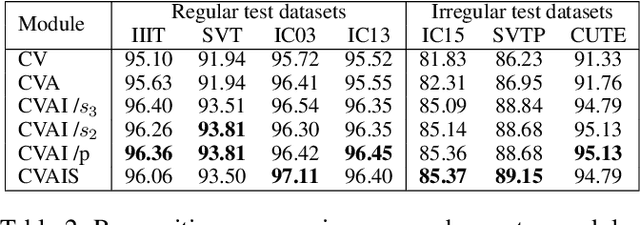
Modeling semantic information is helpful for scene text recognition. In this work, we propose to model semantic and visual information jointly with a Visual-Semantic Transformer (VST). The VST first explicitly extracts primary semantic information from visual feature maps with a transformer module and a primary visual-semantic alignment module. The semantic information is then joined with the visual feature maps (viewed as a sequence) to form a pseudo multi-domain sequence combining visual and semantic information, which is subsequently fed into an transformer-based interaction module to enable learning of interactions between visual and semantic features. In this way, the visual features can be enhanced by the semantic information and vice versus. The enhanced version of visual features are further decoded by a secondary visual-semantic alignment module which shares weights with the primary one. Finally, the decoded visual features and the enhanced semantic features are jointly processed by the third transformer module obtaining the final text prediction. Experiments on seven public benchmarks including regular/ irregular text recognition datasets verifies the effectiveness our proposed model, reaching state of the art on four of the seven benchmarks.