 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeDocVL: A Visual Language Model for Medical Document Understanding and Parsing
Feb 06, 2026Medical document OCR is challenging due to complex layouts, domain-specific terminology, and noisy annotations, while requiring strict field-level exact matching. Existing OCR systems and general-purpose vision-language models often fail to reliably parse such documents. We propose MeDocVL, a post-trained vision-language model for query-driven medical document parsing. Our framework combines Training-driven Label Refinement to construct high-quality supervision from noisy annotations, with a Noise-aware Hybrid Post-training strategy that integrates reinforcement learning and supervised fine-tuning to achieve robust and precise extraction. Experiments on medical invoice benchmarks show that MeDocVL consistently outperforms conventional OCR systems and strong VLM baselines, achieving state-of-the-art performance under noisy supervision.
Position Debiasing Fine-Tuning for Causal Perception in Long-Term Dialogue
Jun 04, 2024



The core of the dialogue system is to generate relevant, informative, and human-like responses based on extensive dialogue history. Recently, dialogue generation domain has seen mainstream adoption of large language models (LLMs), due to its powerful capability in generating utterances. However, there is a natural deficiency for such models, that is, inherent position bias, which may lead them to pay more attention to the nearby utterances instead of causally relevant ones, resulting in generating irrelevant and generic responses in long-term dialogue. To alleviate such problem, in this paper, we propose a novel method, named Causal Perception long-term Dialogue framework (CPD), which employs perturbation-based causal variable discovery method to extract casually relevant utterances from the dialogue history and enhances model causal perception during fine-tuning. Specifically, a local-position awareness method is proposed in CPD for inter-sentence position correlation elimination, which helps models extract causally relevant utterances based on perturbations. Then, a casual-perception fine-tuning strategy is also proposed, to enhance the capability of discovering the causal invariant factors, by differently perturbing causally relevant and non-casually relevant ones for response generation. Experimental results on two datasets prove that our proposed method can effectively alleviate the position bias for multiple LLMs and achieve significant progress compared with existing baselines.
Reinforcement Learning with Token-level Feedback for Controllable Text Generation
Mar 18, 2024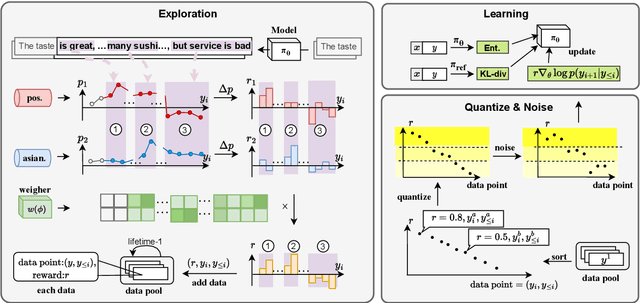
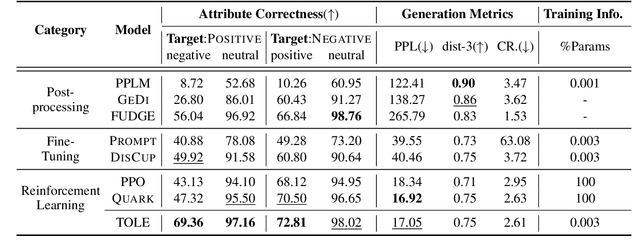
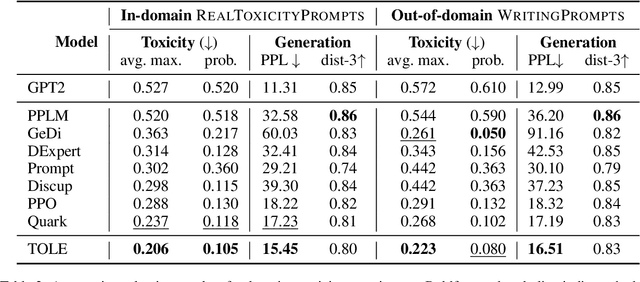
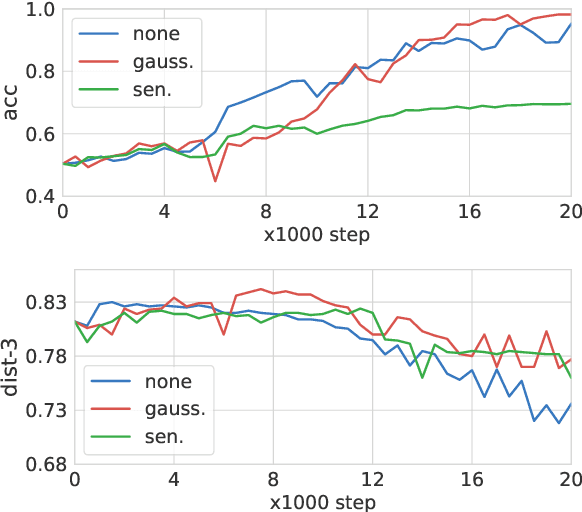
To meet the requirements of real-world applications, it is essential to control generations of large language models (LLMs). Prior research has tried to introduce reinforcement learning (RL) into controllable text generation while most existing methods suffer from overfitting issues (finetuning-based methods) or semantic collapse (post-processing methods). However, current RL methods are generally guided by coarse-grained (sentence/paragraph-level) feedback, which may lead to suboptimal performance owing to semantic twists or progressions within sentences. To tackle that, we propose a novel reinforcement learning algorithm named TOLE which formulates TOken-LEvel rewards for controllable text generation, and employs a "first-quantize-then-noise" paradigm to enhance the robustness of the RL algorithm.Furthermore, TOLE can be flexibly extended to multiple constraints with little computational expense. Experimental results show that our algorithm can achieve superior performance on both single-attribute and multi-attribute control tasks. We have released our codes at https://github.com/WindyLee0822/CTG
Improving Low-resource Prompt-based Relation Representation with Multi-view Decoupling Learning
Jan 15, 2024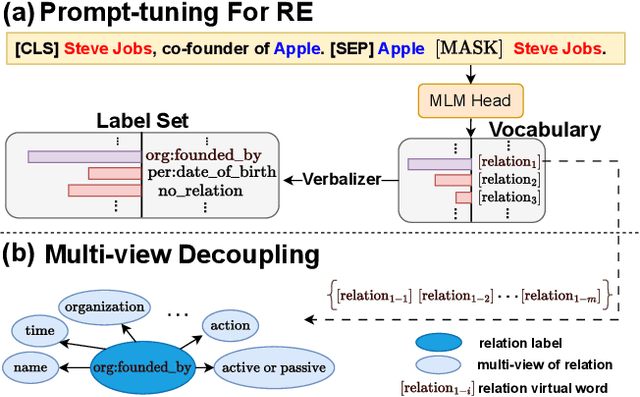
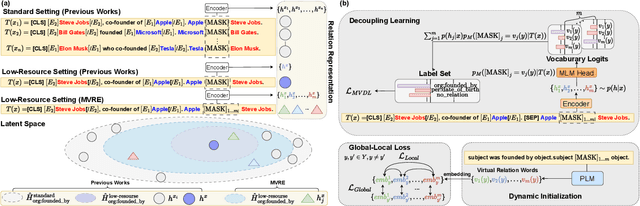
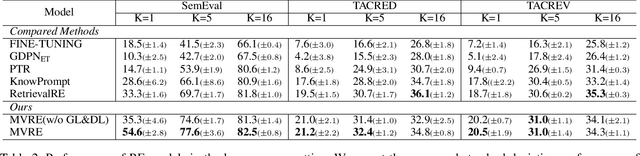
Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (\underline{M}ulti-\underline{V}iew \underline{R}elation \underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
Joint Multi-Facts Reasoning Network For Complex Temporal Question Answering Over Knowledge Graph
Jan 04, 2024Temporal Knowledge Graph (TKG) is an extension of regular knowledge graph by attaching the time scope. Existing temporal knowledge graph question answering (TKGQA) models solely approach simple questions, owing to the prior assumption that each question only contains a single temporal fact with explicit/implicit temporal constraints. Hence, they perform poorly on questions which own multiple temporal facts. In this paper, we propose \textbf{\underline{J}}oint \textbf{\underline{M}}ulti \textbf{\underline{F}}acts \textbf{\underline{R}}easoning \textbf{\underline{N}}etwork (JMFRN), to jointly reasoning multiple temporal facts for accurately answering \emph{complex} temporal questions. Specifically, JMFRN first retrieves question-related temporal facts from TKG for each entity of the given complex question. For joint reasoning, we design two different attention (\ie entity-aware and time-aware) modules, which are suitable for universal settings, to aggregate entities and timestamps information of retrieved facts. Moreover, to filter incorrect type answers, we introduce an additional answer type discrimination task. Extensive experiments demonstrate our proposed method significantly outperforms the state-of-art on the well-known complex temporal question benchmark TimeQuestions.
Detection-based Intermediate Supervision for Visual Question Answering
Dec 26, 2023



Recently, neural module networks (NMNs) have yielded ongoing success in answering compositional visual questions, especially those involving multi-hop visual and logical reasoning. NMNs decompose the complex question into several sub-tasks using instance-modules from the reasoning paths of that question and then exploit intermediate supervisions to guide answer prediction, thereby improving inference interpretability. However, their performance may be hindered due to sketchy modeling of intermediate supervisions. For instance, (1) a prior assumption that each instance-module refers to only one grounded object yet overlooks other potentially associated grounded objects, impeding full cross-modal alignment learning; (2) IoU-based intermediate supervisions may introduce noise signals as the bounding box overlap issue might guide the model's focus towards irrelevant objects. To address these issues, a novel method, \textbf{\underline{D}}etection-based \textbf{\underline{I}}ntermediate \textbf{\underline{S}}upervision (DIS), is proposed, which adopts a generative detection framework to facilitate multiple grounding supervisions via sequence generation. As such, DIS offers more comprehensive and accurate intermediate supervisions, thereby boosting answer prediction performance. Furthermore, by considering intermediate results, DIS enhances the consistency in answering compositional questions and their sub-questions.Extensive experiments demonstrate the superiority of our proposed DIS, showcasing both improved accuracy and state-of-the-art reasoning consistency compared to prior approaches.
TREA: Tree-Structure Reasoning Schema for Conversational Recommendation
Jul 20, 2023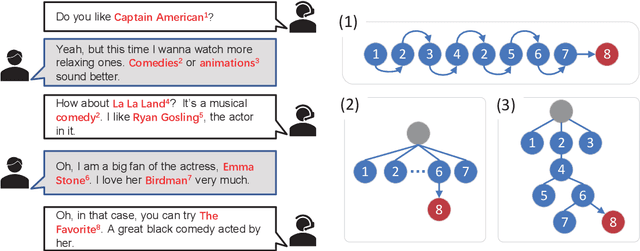



Conversational recommender systems (CRS) aim to timely trace the dynamic interests of users through dialogues and generate relevant responses for item recommendations. Recently, various external knowledge bases (especially knowledge graphs) are incorporated into CRS to enhance the understanding of conversation contexts. However, recent reasoning-based models heavily rely on simplified structures such as linear structures or fixed-hierarchical structures for causality reasoning, hence they cannot fully figure out sophisticated relationships among utterances with external knowledge. To address this, we propose a novel Tree structure Reasoning schEmA named TREA. TREA constructs a multi-hierarchical scalable tree as the reasoning structure to clarify the causal relationships between mentioned entities, and fully utilizes historical conversations to generate more reasonable and suitable responses for recommended results. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach.
PASH at TREC 2021 Deep Learning Track: Generative Enhanced Model for Multi-stage Ranking
May 24, 2022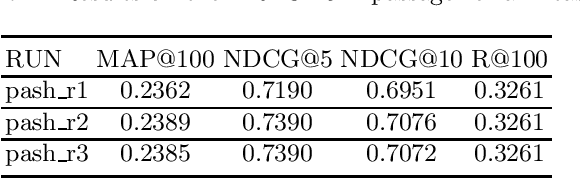
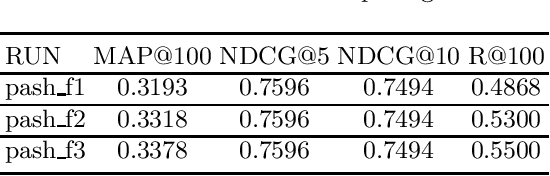
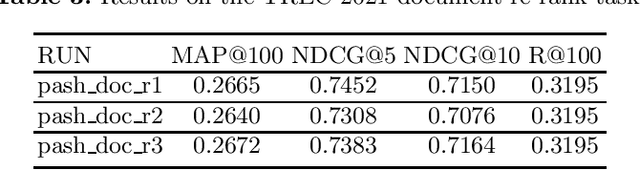
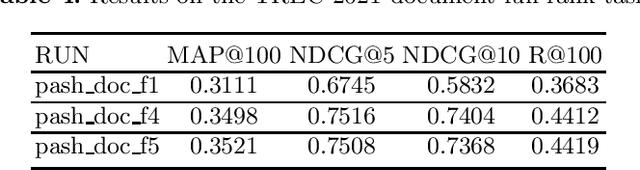
This paper describes the PASH participation in TREC 2021 Deep Learning Track. In the recall stage, we adopt a scheme combining sparse and dense retrieval method. In the multi-stage ranking phase, point-wise and pair-wise ranking strategies are used one after another based on model continual pre-trained on general knowledge and document-level data. Compared to TREC 2020 Deep Learning Track, we have additionally introduced the generative model T5 to further enhance the performance.