 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Language Priors for Visual Question Answering Based on Knowledge Distillation
Jan 10, 2025



Previous studies have pointed out that visual question answering (VQA) models are prone to relying on language priors for answer predictions. In this context, predictions often depend on linguistic shortcuts rather than a comprehensive grasp of multimodal knowledge, which diminishes their generalization ability. In this paper, we propose a novel method, namely, KDAR, leveraging knowledge distillation to address the prior-dependency dilemmas within the VQA task. Specifically, the regularization effect facilitated by soft labels from a well-trained teacher is employed to penalize overfitting to the most common answers. The soft labels, which serve a regularization role, also provide semantic guidance that narrows the range of candidate answers. Additionally, we design an adaptive sample-wise reweighting learning strategy to further mitigate bias by dynamically adjusting the importance of each sample. Experimental results demonstrate that our method enhances performance in both OOD and IID settings. Our method achieves state-of-the-art performance on the VQA-CPv2 out-of-distribution (OOD) benchmark, significantly outperforming previous state-of-the-art approaches.
Detection-based Intermediate Supervision for Visual Question Answering
Dec 26, 2023



Recently, neural module networks (NMNs) have yielded ongoing success in answering compositional visual questions, especially those involving multi-hop visual and logical reasoning. NMNs decompose the complex question into several sub-tasks using instance-modules from the reasoning paths of that question and then exploit intermediate supervisions to guide answer prediction, thereby improving inference interpretability. However, their performance may be hindered due to sketchy modeling of intermediate supervisions. For instance, (1) a prior assumption that each instance-module refers to only one grounded object yet overlooks other potentially associated grounded objects, impeding full cross-modal alignment learning; (2) IoU-based intermediate supervisions may introduce noise signals as the bounding box overlap issue might guide the model's focus towards irrelevant objects. To address these issues, a novel method, \textbf{\underline{D}}etection-based \textbf{\underline{I}}ntermediate \textbf{\underline{S}}upervision (DIS), is proposed, which adopts a generative detection framework to facilitate multiple grounding supervisions via sequence generation. As such, DIS offers more comprehensive and accurate intermediate supervisions, thereby boosting answer prediction performance. Furthermore, by considering intermediate results, DIS enhances the consistency in answering compositional questions and their sub-questions.Extensive experiments demonstrate the superiority of our proposed DIS, showcasing both improved accuracy and state-of-the-art reasoning consistency compared to prior approaches.
An Empirical Study on the Language Modal in Visual Question Answering
May 17, 2023



Generalization beyond in-domain experience to out-of-distribution data is of paramount significance in the AI domain. Of late, state-of-the-art Visual Question Answering (VQA) models have shown impressive performance on in-domain data, partially due to the language priors bias which, however, hinders the generalization ability in practice. This paper attempts to provide new insights into the influence of language modality on VQA performance from an empirical study perspective. To achieve this, we conducted a series of experiments on six models. The results of these experiments revealed that, 1) apart from prior bias caused by question types, there is a notable influence of postfix-related bias in inducing biases, and 2) training VQA models with word-sequence-related variant questions demonstrated improved performance on the out-of-distribution benchmark, and the LXMERT even achieved a 10-point gain without adopting any debiasing methods. We delved into the underlying reasons behind these experimental results and put forward some simple proposals to reduce the models' dependency on language priors. The experimental results demonstrated the effectiveness of our proposed method in improving performance on the out-of-distribution benchmark, VQA-CPv2. We hope this study can inspire novel insights for future research on designing bias-reduction approaches.
Declaration-based Prompt Tuning for Visual Question Answering
May 05, 2022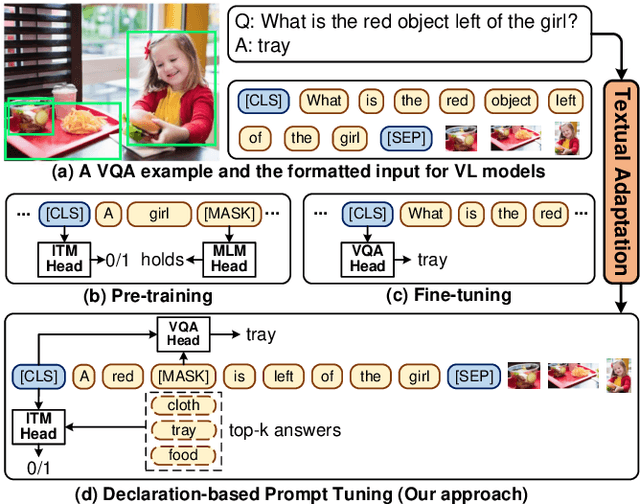
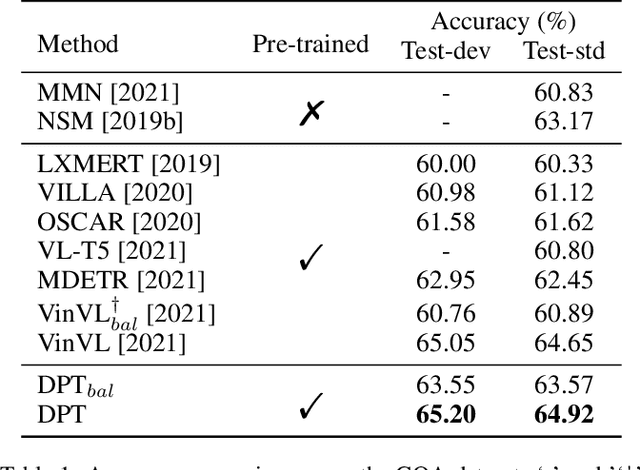
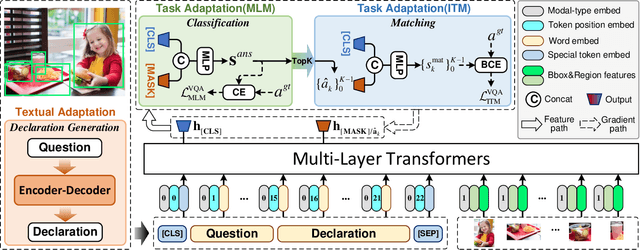
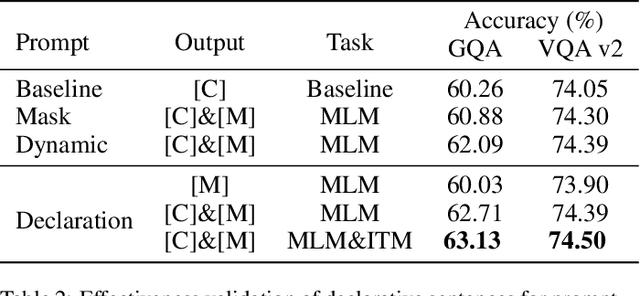
In recent years, the pre-training-then-fine-tuning paradigm has yielded immense success on a wide spectrum of cross-modal tasks, such as visual question answering (VQA), in which a visual-language (VL) model is first optimized via self-supervised task objectives, e.g., masked language modeling (MLM) and image-text matching (ITM), and then fine-tuned to adapt to downstream task (e.g., VQA) via a brand-new objective function, e.g., answer prediction. The inconsistency of the objective forms not only severely limits the generalization of pre-trained VL models to downstream tasks, but also requires a large amount of labeled data for fine-tuning. To alleviate the problem, we propose an innovative VL fine-tuning paradigm (named Declaration-based Prompt Tuning, abbreviated as DPT), which jointly optimizes the objectives of pre-training and fine-tuning of VQA model, boosting the effective adaptation of pre-trained VL models to the downstream task. Specifically, DPT reformulates the objective form of VQA task via (1) textual adaptation, which converts the given questions into declarative sentence-form for prompt-tuning, and (2) task adaptation, which optimizes the objective function of VQA problem in the manner of pre-training phase. Experimental results on GQA dataset show that DPT outperforms the fine-tuned counterpart by a large margin regarding accuracy in both fully-supervised (2.68%) and zero-shot/few-shot (over 31%) settings. All the data and codes will be available to facilitate future research.
Ball k-means
May 02, 2020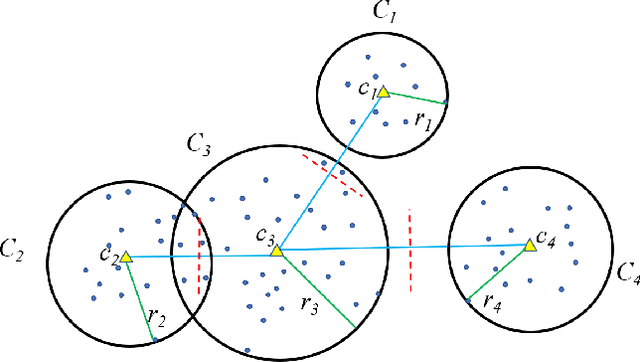
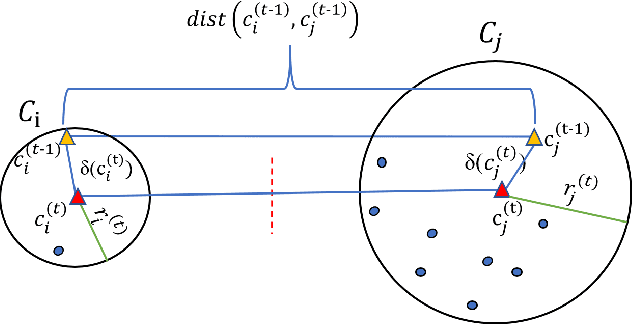
This paper presents a novel accelerated exact k-means algorithm called the Ball k-means algorithm, which uses a ball to describe a cluster, focusing on reducing the point-centroid distance computation. The Ball k-means can accurately find the neighbor clusters for each cluster resulting distance computations only between a point and its neighbor clusters' centroids instead of all centroids. Moreover, each cluster can be divided into a stable area and an active area, and the later one can be further divided into annulus areas. The assigned cluster of the points in the stable area is not changed in the current iteration while the points in the annulus area will be adjusted within a few neighbor clusters in the current iteration. Also, there are no upper or lower bounds in the proposed Ball k-means. Furthermore, reducing centroid-centroid distance computation between iterations makes it efficient for large k clustering. The fast speed, no extra parameters and simple design of the Ball k-means make it an all-around replacement of the naive k-means algorithm.