 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSurvey-Bench: Evaluating Academic Value of Automatically Generated Scientific Survey
Jan 13, 2026The rapid development of automated scientific survey generation technology has made it increasingly important to establish a comprehensive benchmark to evaluate the quality of generated surveys.Nearly all existing evaluation benchmarks rely on flawed selection criteria such as citation counts and structural coherence to select human-written surveys as the ground truth survey datasets, and then use surface-level metrics such as structural quality and reference relevance to evaluate generated surveys.However, these benchmarks have two key issues: (1) the ground truth survey datasets are unreliable because of a lack academic dimension annotations; (2) the evaluation metrics only focus on the surface quality of the survey such as logical coherence. Both issues lead to existing benchmarks cannot assess to evaluate their deep "academic value", such as the core research objectives and the critical analysis of different studies. To address the above problems, we propose DeepSurvey-Bench, a novel benchmark designed to comprehensively evaluate the academic value of generated surveys. Specifically, our benchmark propose a comprehensive academic value evaluation criteria covering three dimensions: informational value, scholarly communication value, and research guidance value. Based on this criteria, we construct a reliable dataset with academic value annotations, and evaluate the deep academic value of the generated surveys. Extensive experimental results demonstrate that our benchmark is highly consistent with human performance in assessing the academic value of generated surveys.
Efficient and Robust Video Defense Framework against 3D-field Personalized Talking Face
Dec 24, 2025State-of-the-art 3D-field video-referenced Talking Face Generation (TFG) methods synthesize high-fidelity personalized talking-face videos in real time by modeling 3D geometry and appearance from reference portrait video. This capability raises significant privacy concerns regarding malicious misuse of personal portraits. However, no efficient defense framework exists to protect such videos against 3D-field TFG methods. While image-based defenses could apply per-frame 2D perturbations, they incur prohibitive computational costs, severe video quality degradation, failing to disrupt 3D information for video protection. To address this, we propose a novel and efficient video defense framework against 3D-field TFG methods, which protects portrait video by perturbing the 3D information acquisition process while maintain high-fidelity video quality. Specifically, our method introduces: (1) a similarity-guided parameter sharing mechanism for computational efficiency, and (2) a multi-scale dual-domain attention module to jointly optimize spatial-frequency perturbations. Extensive experiments demonstrate that our proposed framework exhibits strong defense capability and achieves a 47x acceleration over the fastest baseline while maintaining high fidelity. Moreover, it remains robust against scaling operations and state-of-the-art purification attacks, and the effectiveness of our design choices is further validated through ablation studies. Our project is available at https://github.com/Richen7418/VDF.
MMWOZ: Building Multimodal Agent for Task-oriented Dialogue
Nov 16, 2025Task-oriented dialogue systems have garnered significant attention due to their conversational ability to accomplish goals, such as booking airline tickets for users. Traditionally, task-oriented dialogue systems are conceptualized as intelligent agents that interact with users using natural language and have access to customized back-end APIs. However, in real-world scenarios, the widespread presence of front-end Graphical User Interfaces (GUIs) and the absence of customized back-end APIs create a significant gap for traditional task-oriented dialogue systems in practical applications. In this paper, to bridge the gap, we collect MMWOZ, a new multimodal dialogue dataset that is extended from MultiWOZ 2.3 dataset. Specifically, we begin by developing a web-style GUI to serve as the front-end. Next, we devise an automated script to convert the dialogue states and system actions from the original dataset into operation instructions for the GUI. Lastly, we collect snapshots of the web pages along with their corresponding operation instructions. In addition, we propose a novel multimodal model called MATE (Multimodal Agent for Task-oriEnted dialogue) as the baseline model for the MMWOZ dataset. Furthermore, we conduct comprehensive experimental analysis using MATE to investigate the construction of a practical multimodal agent for task-oriented dialogue.
Is It Truly Necessary to Process and Fit Minutes-Long Reference Videos for Personalized Talking Face Generation?
Nov 11, 2025Talking Face Generation (TFG) aims to produce realistic and dynamic talking portraits, with broad applications in fields such as digital education, film and television production, e-commerce live streaming, and other related areas. Currently, TFG methods based on Neural Radiated Field (NeRF) or 3D Gaussian sputtering (3DGS) are received widespread attention. They learn and store personalized features from reference videos of each target individual to generate realistic speaking videos. To ensure models can capture sufficient 3D information and successfully learns the lip-audio mapping, previous studies usually require meticulous processing and fitting several minutes of reference video, which always takes hours. The computational burden of processing and fitting long reference videos severely limits the practical application value of these methods.However, is it really necessary to fit such minutes of reference video? Our exploratory case studies show that using some informative reference video segments of just a few seconds can achieve performance comparable to or even better than the full reference video. This indicates that video informative quality is much more important than its length. Inspired by this observation, we propose the ISExplore (short for Informative Segment Explore), a simple-yet-effective segment selection strategy that automatically identifies the informative 5-second reference video segment based on three key data quality dimensions: audio feature diversity, lip movement amplitude, and number of camera views. Extensive experiments demonstrate that our approach increases data processing and training speed by more than 5x for NeRF and 3DGS methods, while maintaining high-fidelity output. Project resources are available at xx.
A Survey of Automatic Evaluation Methods on Text, Visual and Speech Generations
Jun 06, 2025Recent advances in deep learning have significantly enhanced generative AI capabilities across text, images, and audio. However, automatically evaluating the quality of these generated outputs presents ongoing challenges. Although numerous automatic evaluation methods exist, current research lacks a systematic framework that comprehensively organizes these methods across text, visual, and audio modalities. To address this issue, we present a comprehensive review and a unified taxonomy of automatic evaluation methods for generated content across all three modalities; We identify five fundamental paradigms that characterize existing evaluation approaches across these domains. Our analysis begins by examining evaluation methods for text generation, where techniques are most mature. We then extend this framework to image and audio generation, demonstrating its broad applicability. Finally, we discuss promising directions for future research in cross-modal evaluation methodologies.
T2I-Eval-R1: Reinforcement Learning-Driven Reasoning for Interpretable Text-to-Image Evaluation
May 23, 2025The rapid progress in diffusion-based text-to-image (T2I) generation has created an urgent need for interpretable automatic evaluation methods that can assess the quality of generated images, therefore reducing the human annotation burden. To reduce the prohibitive cost of relying on commercial models for large-scale evaluation, and to improve the reasoning capabilities of open-source models, recent research has explored supervised fine-tuning (SFT) of multimodal large language models (MLLMs) as dedicated T2I evaluators. However, SFT approaches typically rely on high-quality critique datasets, which are either generated by proprietary LLMs-with potential issues of bias and inconsistency-or annotated by humans at high cost, limiting their scalability and generalization. To address these limitations, we propose T2I-Eval-R1, a novel reinforcement learning framework that trains open-source MLLMs using only coarse-grained quality scores, thereby avoiding the need for annotating high-quality interpretable evaluation rationale. Our approach integrates Group Relative Policy Optimization (GRPO) into the instruction-tuning process, enabling models to generate both scalar scores and interpretable reasoning chains with only easy accessible annotated judgment scores or preferences. Furthermore, we introduce a continuous reward formulation that encourages score diversity and provides stable optimization signals, leading to more robust and discriminative evaluation behavior. Experimental results on three established T2I meta-evaluation benchmarks demonstrate that T2I-Eval-R1 achieves significantly higher alignment with human assessments and offers more accurate interpretable score rationales compared to strong baseline methods.
SEOE: A Scalable and Reliable Semantic Evaluation Framework for Open Domain Event Detection
Mar 05, 2025Automatic evaluation for Open Domain Event Detection (ODED) is a highly challenging task, because ODED is characterized by a vast diversity of un-constrained output labels from various domains. Nearly all existing evaluation methods for ODED usually first construct evaluation benchmarks with limited labels and domain coverage, and then evaluate ODED methods using metrics based on token-level label matching rules. However, this kind of evaluation framework faces two issues: (1) The limited evaluation benchmarks lack representatives of the real world, making it difficult to accurately reflect the performance of various ODED methods in real-world scenarios; (2) Evaluation metrics based on token-level matching rules fail to capture semantic similarity between predictions and golden labels. To address these two problems above, we propose a scalable and reliable Semantic-level Evaluation framework for Open domain Event detection (SEOE) by constructing a more representative evaluation benchmark and introducing a semantic evaluation metric. Specifically, our proposed framework first constructs a scalable evaluation benchmark that currently includes 564 event types covering 7 major domains, with a cost-effective supplementary annotation strategy to ensure the benchmark's representativeness. The strategy also allows for the supplement of new event types and domains in the future. Then, the proposed SEOE leverages large language models (LLMs) as automatic evaluation agents to compute a semantic F1-score, incorporating fine-grained definitions of semantically similar labels to enhance the reliability of the evaluation. Extensive experiments validate the representatives of the benchmark and the reliability of the semantic evaluation metric. Existing ODED methods are thoroughly evaluated, and the error patterns of predictions are analyzed, revealing several insightful findings.
A Distributed Collaborative Retrieval Framework Excelling in All Queries and Corpora based on Zero-shot Rank-Oriented Automatic Evaluation
Dec 16, 2024



Numerous retrieval models, including sparse, dense and llm-based methods, have demonstrated remarkable performance in predicting the relevance between queries and corpora. However, the preliminary effectiveness analysis experiments indicate that these models fail to achieve satisfactory performance on the majority of queries and corpora, revealing their effectiveness restricted to specific scenarios. Thus, to tackle this problem, we propose a novel Distributed Collaborative Retrieval Framework (DCRF), outperforming each single model across all queries and corpora. Specifically, the framework integrates various retrieval models into a unified system and dynamically selects the optimal results for each user's query. It can easily aggregate any retrieval model and expand to any application scenarios, illustrating its flexibility and scalability.Moreover, to reduce maintenance and training costs, we design four effective prompting strategies with large language models (LLMs) to evaluate the quality of ranks without reliance of labeled data. Extensive experiments demonstrate that proposed framework, combined with 8 efficient retrieval models, can achieve performance comparable to effective listwise methods like RankGPT and ListT5, while offering superior efficiency. Besides, DCRF surpasses all selected retrieval models on the most datasets, indicating the effectiveness of our prompting strategies on rank-oriented automatic evaluation.
Distribution-Consistency-Guided Multi-modal Hashing
Dec 15, 2024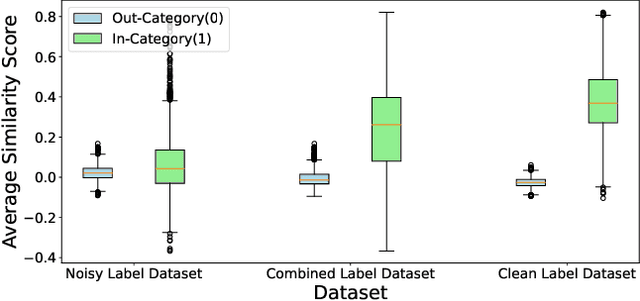
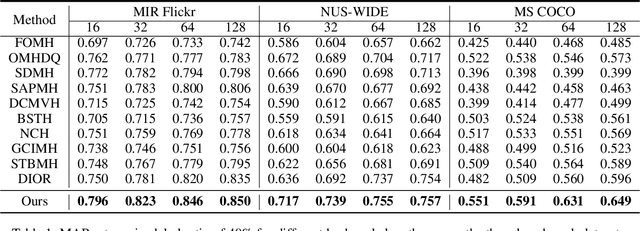
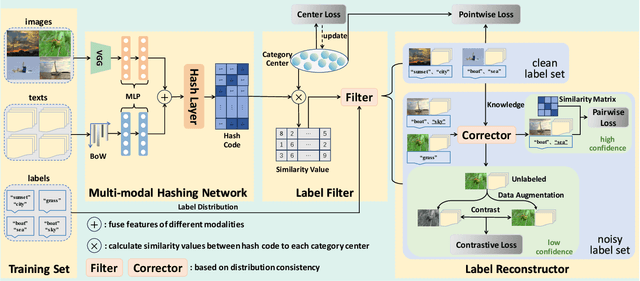
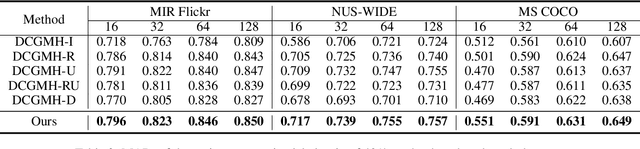
Multi-modal hashing methods have gained popularity due to their fast speed and low storage requirements. Among them, the supervised methods demonstrate better performance by utilizing labels as supervisory signals compared with unsupervised methods. Currently, for almost all supervised multi-modal hashing methods, there is a hidden assumption that training sets have no noisy labels. However, labels are often annotated incorrectly due to manual labeling in real-world scenarios, which will greatly harm the retrieval performance. To address this issue, we first discover a significant distribution consistency pattern through experiments, i.e., the 1-0 distribution of the presence or absence of each category in the label is consistent with the high-low distribution of similarity scores of the hash codes relative to category centers. Then, inspired by this pattern, we propose a novel Distribution-Consistency-Guided Multi-modal Hashing (DCGMH), which aims to filter and reconstruct noisy labels to enhance retrieval performance. Specifically, the proposed method first randomly initializes several category centers, which are used to compute the high-low distribution of similarity scores; Noisy and clean labels are then separately filtered out via the discovered distribution consistency pattern to mitigate the impact of noisy labels; Subsequently, a correction strategy, which is indirectly designed via the distribution consistency pattern, is applied to the filtered noisy labels, correcting high-confidence ones while treating low-confidence ones as unlabeled for unsupervised learning, thereby further enhancing the model's performance. Extensive experiments on three widely used datasets demonstrate the superiority of the proposed method compared to state-of-the-art baselines in multi-modal retrieval tasks. The code is available at https://github.com/LiuJinyu1229/DCGMH.
Multi-modal Retrieval Augmented Multi-modal Generation: A Benchmark, Evaluate Metrics and Strong Baselines
Nov 25, 2024
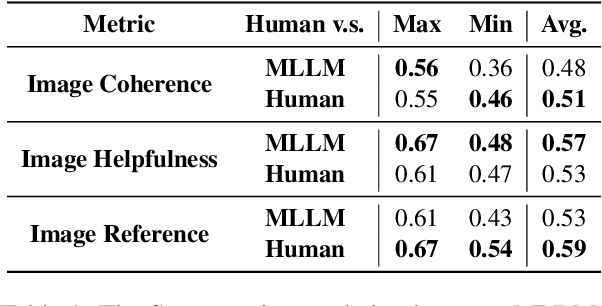
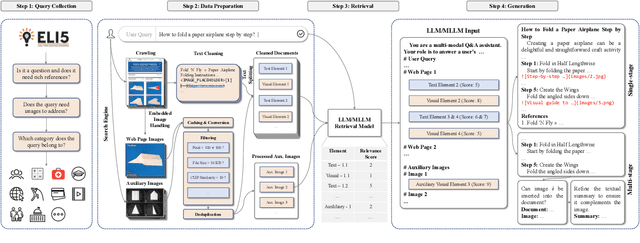
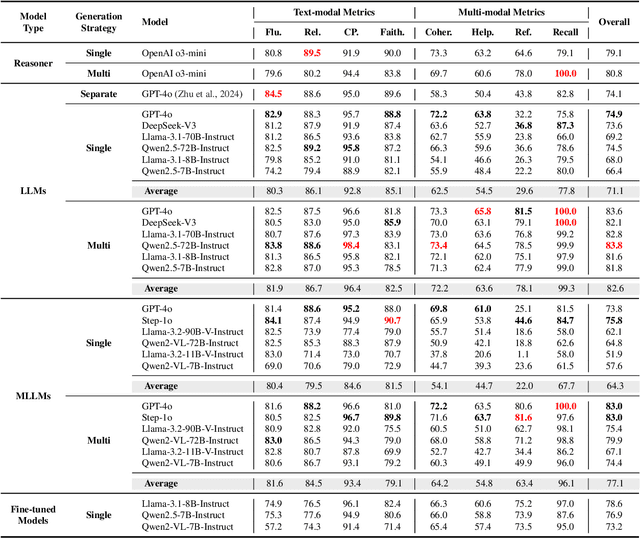
This paper investigates an intriguing task of Multi-modal Retrieval Augmented Multi-modal Generation (M$^2$RAG). This task requires foundation models to browse multi-modal web pages, with mixed text and images, and generate multi-modal responses for solving user queries, which exhibits better information density and readability. Given the early researching stage of M$^2$RAG task, there is a lack of systematic studies and analysis. To fill this gap, we construct a benchmark for M$^2$RAG task, equipped with a suite of text-modal metrics and multi-modal metrics to analyze the capabilities of existing foundation models. Besides, we also propose several effective methods for foundation models to accomplish this task, based on the comprehensive evaluation results on our benchmark. Extensive experimental results reveal several intriguing phenomena worth further research.