 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Automatic Evaluation Methods on Text, Visual and Speech Generations
Jun 06, 2025Recent advances in deep learning have significantly enhanced generative AI capabilities across text, images, and audio. However, automatically evaluating the quality of these generated outputs presents ongoing challenges. Although numerous automatic evaluation methods exist, current research lacks a systematic framework that comprehensively organizes these methods across text, visual, and audio modalities. To address this issue, we present a comprehensive review and a unified taxonomy of automatic evaluation methods for generated content across all three modalities; We identify five fundamental paradigms that characterize existing evaluation approaches across these domains. Our analysis begins by examining evaluation methods for text generation, where techniques are most mature. We then extend this framework to image and audio generation, demonstrating its broad applicability. Finally, we discuss promising directions for future research in cross-modal evaluation methodologies.
T2I-Eval-R1: Reinforcement Learning-Driven Reasoning for Interpretable Text-to-Image Evaluation
May 23, 2025The rapid progress in diffusion-based text-to-image (T2I) generation has created an urgent need for interpretable automatic evaluation methods that can assess the quality of generated images, therefore reducing the human annotation burden. To reduce the prohibitive cost of relying on commercial models for large-scale evaluation, and to improve the reasoning capabilities of open-source models, recent research has explored supervised fine-tuning (SFT) of multimodal large language models (MLLMs) as dedicated T2I evaluators. However, SFT approaches typically rely on high-quality critique datasets, which are either generated by proprietary LLMs-with potential issues of bias and inconsistency-or annotated by humans at high cost, limiting their scalability and generalization. To address these limitations, we propose T2I-Eval-R1, a novel reinforcement learning framework that trains open-source MLLMs using only coarse-grained quality scores, thereby avoiding the need for annotating high-quality interpretable evaluation rationale. Our approach integrates Group Relative Policy Optimization (GRPO) into the instruction-tuning process, enabling models to generate both scalar scores and interpretable reasoning chains with only easy accessible annotated judgment scores or preferences. Furthermore, we introduce a continuous reward formulation that encourages score diversity and provides stable optimization signals, leading to more robust and discriminative evaluation behavior. Experimental results on three established T2I meta-evaluation benchmarks demonstrate that T2I-Eval-R1 achieves significantly higher alignment with human assessments and offers more accurate interpretable score rationales compared to strong baseline methods.
Multi-modal Retrieval Augmented Multi-modal Generation: A Benchmark, Evaluate Metrics and Strong Baselines
Nov 25, 2024
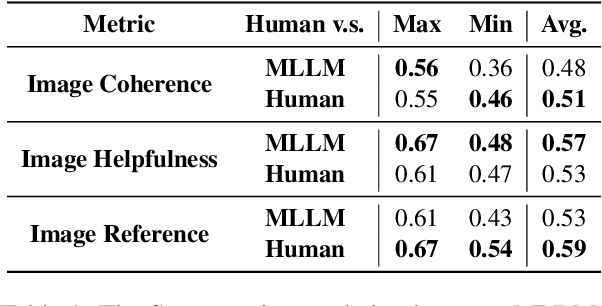
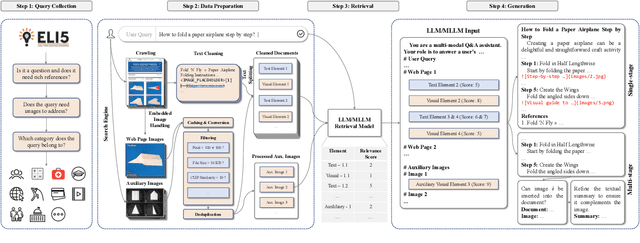
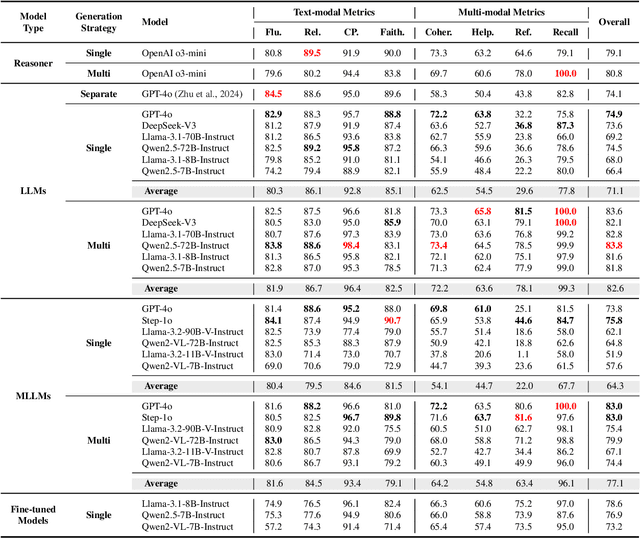
This paper investigates an intriguing task of Multi-modal Retrieval Augmented Multi-modal Generation (M$^2$RAG). This task requires foundation models to browse multi-modal web pages, with mixed text and images, and generate multi-modal responses for solving user queries, which exhibits better information density and readability. Given the early researching stage of M$^2$RAG task, there is a lack of systematic studies and analysis. To fill this gap, we construct a benchmark for M$^2$RAG task, equipped with a suite of text-modal metrics and multi-modal metrics to analyze the capabilities of existing foundation models. Besides, we also propose several effective methods for foundation models to accomplish this task, based on the comprehensive evaluation results on our benchmark. Extensive experimental results reveal several intriguing phenomena worth further research.
Automatic Evaluation for Text-to-image Generation: Task-decomposed Framework, Distilled Training, and Meta-evaluation Benchmark
Nov 23, 2024



Driven by the remarkable progress in diffusion models, text-to-image generation has made significant strides, creating a pressing demand for automatic quality evaluation of generated images. Current state-of-the-art automatic evaluation methods heavily rely on Multi-modal Large Language Models (MLLMs), particularly powerful commercial models like GPT-4o. While these models are highly effective, their substantial costs limit scalability in large-scale evaluations. Adopting open-source MLLMs is an alternative; however, their performance falls short due to significant limitations in processing multi-modal data compared to commercial MLLMs. To tackle these problems, we first propose a task decomposition evaluation framework based on GPT-4o to automatically construct a new training dataset, where the complex evaluation task is decoupled into simpler sub-tasks, effectively reducing the learning complexity. Based on this dataset, we design innovative training strategies to effectively distill GPT-4o's evaluation capabilities into a 7B open-source MLLM, MiniCPM-V-2.6. Furthermore, to reliably and comprehensively assess prior works and our proposed model, we manually annotate a meta-evaluation benchmark that includes chain-of-thought explanations alongside quality scores for generated images. Experimental results demonstrate that our distilled open-source MLLM significantly outperforms the current state-of-the-art GPT-4o-base baseline, VIEScore, with over 4.6\% improvement in Spearman and Kendall correlations with human judgments.