 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Frames Are Equal: Complexity-Aware Masked Motion Generation via Motion Spectral Descriptors
Mar 31, 2026Masked generative models have become a strong paradigm for text-to-motion synthesis, but they still treat motion frames too uniformly during masking, attention, and decoding. This is a poor match for motion, where local dynamic complexity varies sharply over time. We show that current masked motion generators degrade disproportionately on dynamically complex motions, and that frame-wise generation error is strongly correlated with motion dynamics. Motivated by this mismatch, we introduce the Motion Spectral Descriptor (MSD), a simple and parameter-free measure of local dynamic complexity computed from the short-time spectrum of motion velocity. Unlike learned difficulty predictors, MSD is deterministic, interpretable, and derived directly from the motion signal itself. We use MSD to make masked motion generation complexity-aware. In particular, MSD guides content-focused masking during training, provides a spectral similarity prior for self-attention, and can additionally modulate token-level sampling during iterative decoding. Built on top of masked motion generators, our method, DynMask, improves motion generation most clearly on dynamically complex motions while also yielding stronger overall FID on HumanML3D and KIT-ML. These results suggest that respecting local motion complexity is a useful design principle for masked motion generation. Project page: https://xiangyue-zhang.github.io/DynMask
Clinical-Prior Guided Multi-Modal Learning with Latent Attention Pooling for Gait-Based Scoliosis Screening
Feb 06, 2026Adolescent Idiopathic Scoliosis (AIS) is a prevalent spinal deformity whose progression can be mitigated through early detection. Conventional screening methods are often subjective, difficult to scale, and reliant on specialized clinical expertise. Video-based gait analysis offers a promising alternative, but current datasets and methods frequently suffer from data leakage, where performance is inflated by repeated clips from the same individual, or employ oversimplified models that lack clinical interpretability. To address these limitations, we introduce ScoliGait, a new benchmark dataset comprising 1,572 gait video clips for training and 300 fully independent clips for testing. Each clip is annotated with radiographic Cobb angles and descriptive text based on clinical kinematic priors. We propose a multi-modal framework that integrates a clinical-prior-guided kinematic knowledge map for interpretable feature representation, alongside a latent attention pooling mechanism to fuse video, text, and knowledge map modalities. Our method establishes a new state-of-the-art, demonstrating a significant performance gap on a realistic, non-repeating subject benchmark. Our approach establishes a new state of the art, showing a significant performance gain on a realistic, subject-independent benchmark. This work provides a robust, interpretable, and clinically grounded foundation for scalable, non-invasive AIS assessment.
CANDY: Benchmarking LLMs' Limitations and Assistive Potential in Chinese Misinformation Fact-Checking
Sep 04, 2025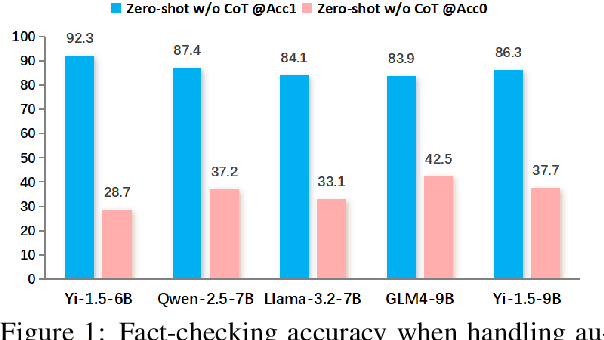
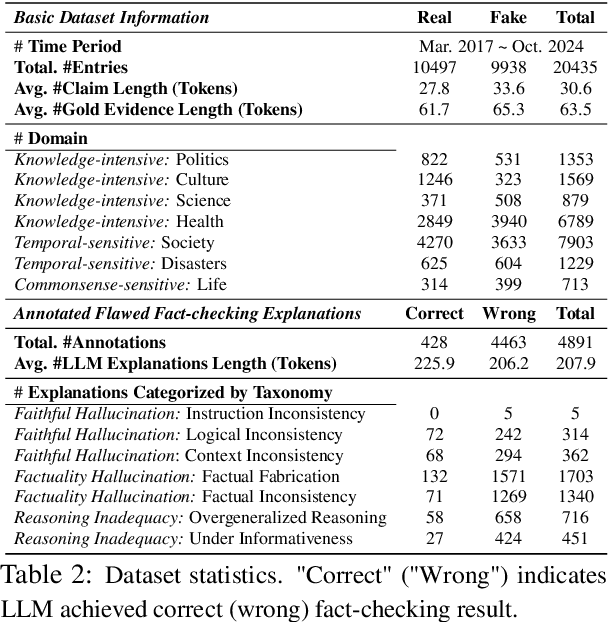
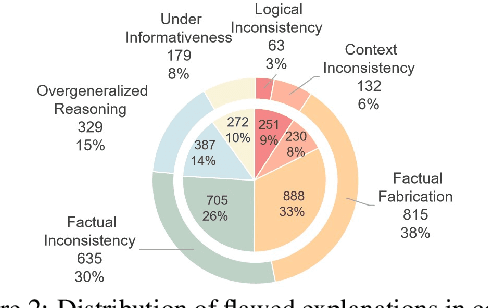

The effectiveness of large language models (LLMs) to fact-check misinformation remains uncertain, despite their growing use. To this end, we present CANDY, a benchmark designed to systematically evaluate the capabilities and limitations of LLMs in fact-checking Chinese misinformation. Specifically, we curate a carefully annotated dataset of ~20k instances. Our analysis shows that current LLMs exhibit limitations in generating accurate fact-checking conclusions, even when enhanced with chain-of-thought reasoning and few-shot prompting. To understand these limitations, we develop a taxonomy to categorize flawed LLM-generated explanations for their conclusions and identify factual fabrication as the most common failure mode. Although LLMs alone are unreliable for fact-checking, our findings indicate their considerable potential to augment human performance when deployed as assistive tools in scenarios. Our dataset and code can be accessed at https://github.com/SCUNLP/CANDY
Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning
Aug 27, 2025The functionality of Large Language Model (LLM) agents is primarily determined by two capabilities: action planning and answer summarization. The former, action planning, is the core capability that dictates an agent's performance. However, prevailing training paradigms employ end-to-end, multi-objective optimization that jointly trains both capabilities. This paradigm faces two critical challenges: imbalanced optimization objective allocation and scarcity of verifiable data, making it difficult to enhance the agent's planning capability. To address these challenges, we propose Reinforcement Learning with Tool-use Rewards (RLTR), a novel framework that decouples the training process to enable a focused, single-objective optimization of the planning module. Crucially, RLTR introduces a reward signal based on tool-use completeness to directly evaluate the quality of tool invocation sequences. This method offers a more direct and reliable training signal than assessing the final response content, thereby obviating the need for verifiable data. Our experiments demonstrate that RLTR achieves an 8%-12% improvement in planning performance compared to end-to-end baselines. Moreover, this enhanced planning capability, in turn, translates to a 5%-6% increase in the final response quality of the overall agent system.
Query Routing for Retrieval-Augmented Language Models
May 29, 2025Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) on knowledge-intensive tasks. However, varying response quality across LLMs under RAG necessitates intelligent routing mechanisms, which select the most suitable model for each query from multiple retrieval-augmented LLMs via a dedicated router model. We observe that external documents dynamically affect LLMs' ability to answer queries, while existing routing methods, which rely on static parametric knowledge representations, exhibit suboptimal performance in RAG scenarios. To address this, we formally define the new retrieval-augmented LLM routing problem, incorporating the influence of retrieved documents into the routing framework. We propose RAGRouter, a RAG-aware routing design, which leverages document embeddings and RAG capability embeddings with contrastive learning to capture knowledge representation shifts and enable informed routing decisions. Extensive experiments on diverse knowledge-intensive tasks and retrieval settings show that RAGRouter outperforms the best individual LLM by 3.61% on average and existing routing methods by 3.29%-9.33%. With an extended score-threshold-based mechanism, it also achieves strong performance-efficiency trade-offs under low-latency constraints.
Automated Privacy Information Annotation in Large Language Model Interactions
May 27, 2025Users interacting with large language models (LLMs) under their real identifiers often unknowingly risk disclosing private information. Automatically notifying users whether their queries leak privacy and which phrases leak what private information has therefore become a practical need. Existing privacy detection methods, however, were designed for different objectives and application scenarios, typically tagging personally identifiable information (PII) in anonymous content. In this work, to support the development and evaluation of privacy detection models for LLM interactions that are deployable on local user devices, we construct a large-scale multilingual dataset with 249K user queries and 154K annotated privacy phrases. In particular, we build an automated privacy annotation pipeline with cloud-based strong LLMs to automatically extract privacy phrases from dialogue datasets and annotate leaked information. We also design evaluation metrics at the levels of privacy leakage, extracted privacy phrase, and privacy information. We further establish baseline methods using light-weight LLMs with both tuning-free and tuning-based methods, and report a comprehensive evaluation of their performance. Evaluation results reveal a gap between current performance and the requirements of real-world LLM applications, motivating future research into more effective local privacy detection methods grounded in our dataset.
Text-driven 3D Human Generation via Contrastive Preference Optimization
Feb 13, 2025Recent advances in Score Distillation Sampling (SDS) have improved 3D human generation from textual descriptions. However, existing methods still face challenges in accurately aligning 3D models with long and complex textual inputs. To address this challenge, we propose a novel framework that introduces contrastive preferences, where human-level preference models, guided by both positive and negative prompts, assist SDS for improved alignment. Specifically, we design a preference optimization module that integrates multiple models to comprehensively capture the full range of textual features. Furthermore, we introduce a negation preference module to mitigate over-optimization of irrelevant details by leveraging static-dynamic negation prompts, effectively preventing ``reward hacking". Extensive experiments demonstrate that our method achieves state-of-the-art results, significantly enhancing texture realism and visual alignment with textual descriptions, particularly for long and complex inputs.
JGHand: Joint-Driven Animatable Hand Avater via 3D Gaussian Splatting
Jan 31, 2025



Since hands are the primary interface in daily interactions, modeling high-quality digital human hands and rendering realistic images is a critical research problem. Furthermore, considering the requirements of interactive and rendering applications, it is essential to achieve real-time rendering and driveability of the digital model without compromising rendering quality. Thus, we propose Jointly 3D Gaussian Hand (JGHand), a novel joint-driven 3D Gaussian Splatting (3DGS)-based hand representation that renders high-fidelity hand images in real-time for various poses and characters. Distinct from existing articulated neural rendering techniques, we introduce a differentiable process for spatial transformations based on 3D key points. This process supports deformations from the canonical template to a mesh with arbitrary bone lengths and poses. Additionally, we propose a real-time shadow simulation method based on per-pixel depth to simulate self-occlusion shadows caused by finger movements. Finally, we embed the hand prior and propose an animatable 3DGS representation of the hand driven solely by 3D key points. We validate the effectiveness of each component of our approach through comprehensive ablation studies. Experimental results on public datasets demonstrate that JGHand achieves real-time rendering speeds with enhanced quality, surpassing state-of-the-art methods.
Multi-modal Retrieval Augmented Multi-modal Generation: A Benchmark, Evaluate Metrics and Strong Baselines
Nov 25, 2024
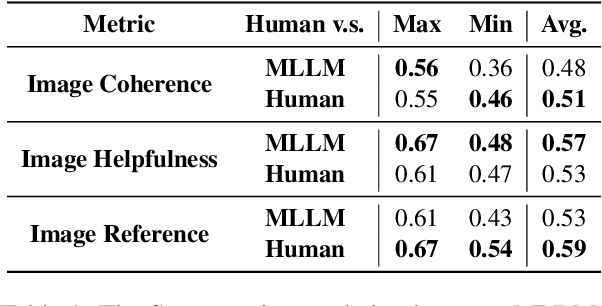
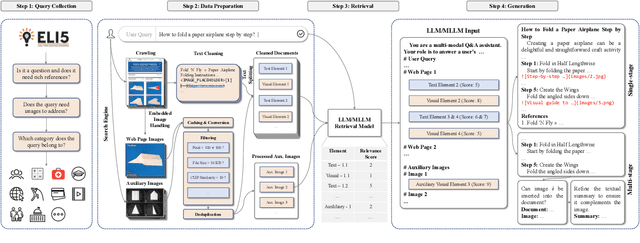
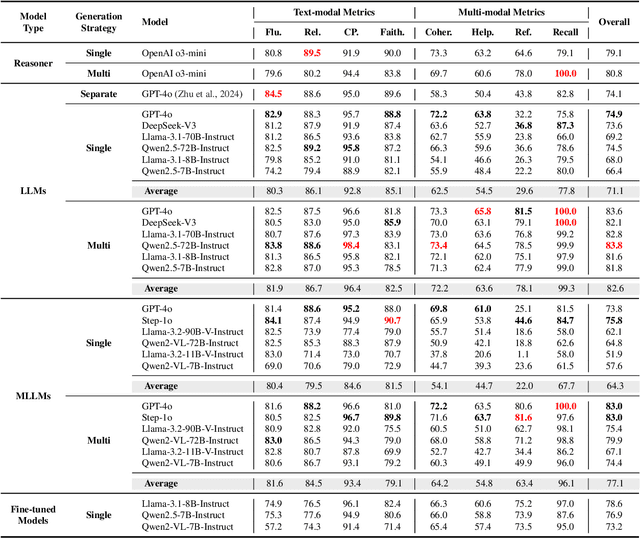
This paper investigates an intriguing task of Multi-modal Retrieval Augmented Multi-modal Generation (M$^2$RAG). This task requires foundation models to browse multi-modal web pages, with mixed text and images, and generate multi-modal responses for solving user queries, which exhibits better information density and readability. Given the early researching stage of M$^2$RAG task, there is a lack of systematic studies and analysis. To fill this gap, we construct a benchmark for M$^2$RAG task, equipped with a suite of text-modal metrics and multi-modal metrics to analyze the capabilities of existing foundation models. Besides, we also propose several effective methods for foundation models to accomplish this task, based on the comprehensive evaluation results on our benchmark. Extensive experimental results reveal several intriguing phenomena worth further research.
C-LLM: Learn to Check Chinese Spelling Errors Character by Character
Jun 24, 2024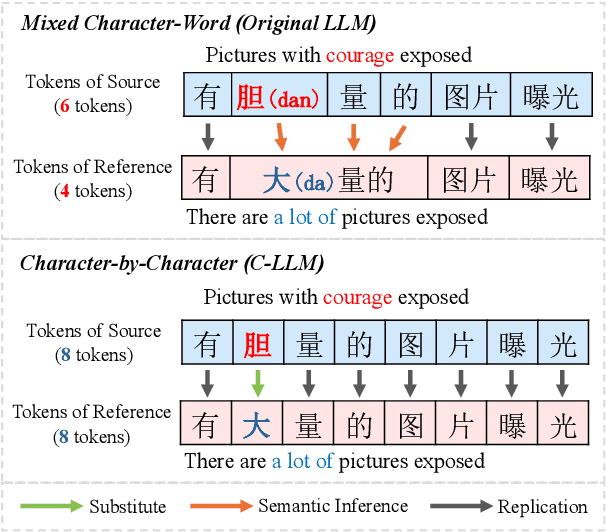
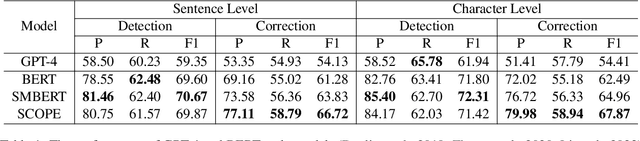
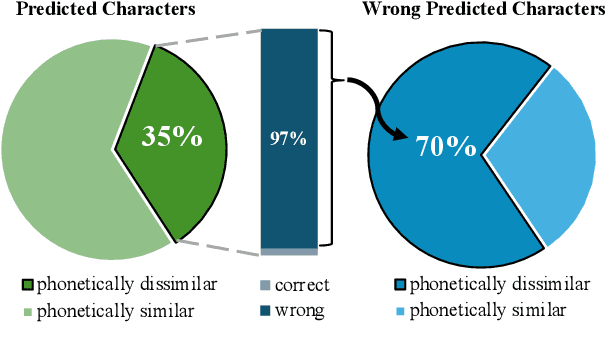
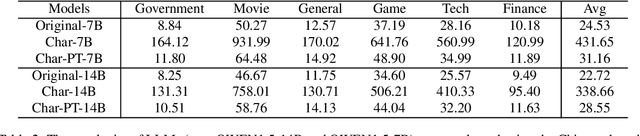
Chinese Spell Checking (CSC) aims to detect and correct spelling errors in sentences. Despite Large Language Models (LLMs) exhibit robust capabilities and are widely applied in various tasks, their performance on CSC is often unsatisfactory. We find that LLMs fail to meet the Chinese character-level constraints of the CSC task, namely equal length and phonetic similarity, leading to a performance bottleneck. Further analysis reveal that this issue stems from the granularity of tokenization, as current mixed character-word tokenization struggles to satisfy these character-level constraints. To address this issue, we propose C-LLM, a Large Language Model-based Chinese Spell Checking method that learns to check errors Character by Character. Character-level tokenization enables the model to learn character-level alignment, effectively mitigating issues related to character-level constraints. Furthermore, CSC is simplified to replication-dominated and substitution-supplemented tasks. Experiments on two CSC benchmarks demonstrate that C-LLM achieves an average improvement of 10% over existing methods. Specifically, it shows a 2.1% improvement in general scenarios and a significant 12% improvement in vertical domain scenarios, establishing state-of-the-art performance. The source code can be accessed at https://github.com/ktlKTL/C-LLM.