 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Improvement on Psychotherapy Chatbot Using Assistant
Apr 24, 2024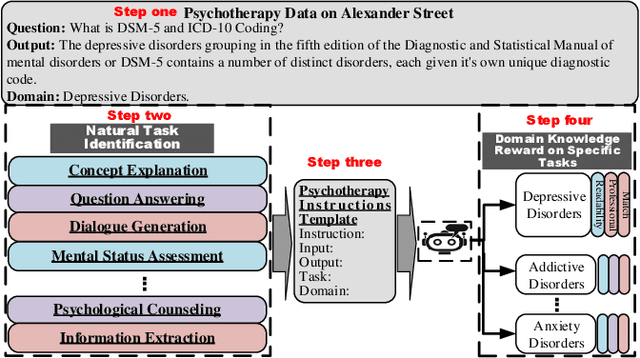
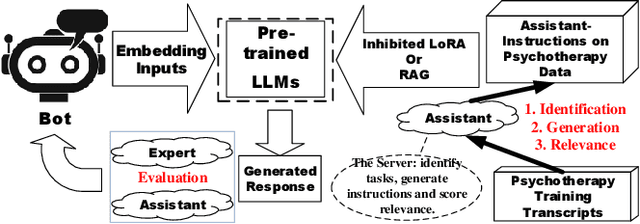


Large language models (LLMs) have demonstrated impressive generalization capabilities on specific tasks with human-written instruction data. However, the limited quantity, diversity, and professional expertise of such instruction data raise concerns about the performance of LLMs in psychotherapy tasks when provided with domain-specific instructions. To address this, we firstly propose Domain-Specific Assistant Instructions based on AlexanderStreet therapy, and secondly, we use an adaption fine-tuning method and retrieval augmented generation method to improve pre-trained LLMs. Through quantitative evaluation of linguistic quality using automatic and human evaluation, we observe that pre-trained LLMs on Psychotherapy Assistant Instructions outperform state-of-the-art LLMs response baselines. Our Assistant-Instruction approach offers a half-annotation method to align pre-trained LLMs with instructions and provide pre-trained LLMs with more psychotherapy knowledge.
BOND: Bootstrapping From-Scratch Name Disambiguation with Multi-task Promoting
Apr 12, 2024From-scratch name disambiguation is an essential task for establishing a reliable foundation for academic platforms. It involves partitioning documents authored by identically named individuals into groups representing distinct real-life experts. Canonically, the process is divided into two decoupled tasks: locally estimating the pairwise similarities between documents followed by globally grouping these documents into appropriate clusters. However, such a decoupled approach often inhibits optimal information exchange between these intertwined tasks. Therefore, we present BOND, which bootstraps the local and global informative signals to promote each other in an end-to-end regime. Specifically, BOND harnesses local pairwise similarities to drive global clustering, subsequently generating pseudo-clustering labels. These global signals further refine local pairwise characterizations. The experimental results establish BOND's superiority, outperforming other advanced baselines by a substantial margin. Moreover, an enhanced version, BOND+, incorporating ensemble and post-match techniques, rivals the top methods in the WhoIsWho competition.
* TheWebConf 2024 (WWW '24)
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.
Web-Scale Academic Name Disambiguation: the WhoIsWho Benchmark, Leaderboard, and Toolkit
Feb 23, 2023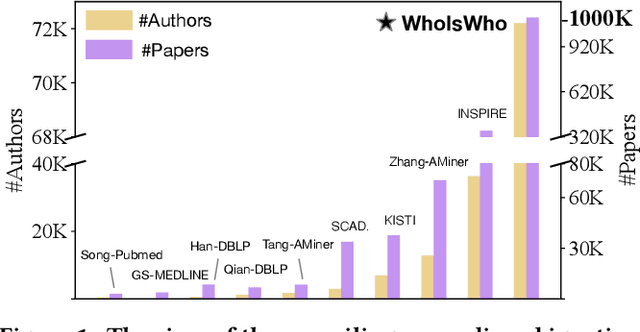

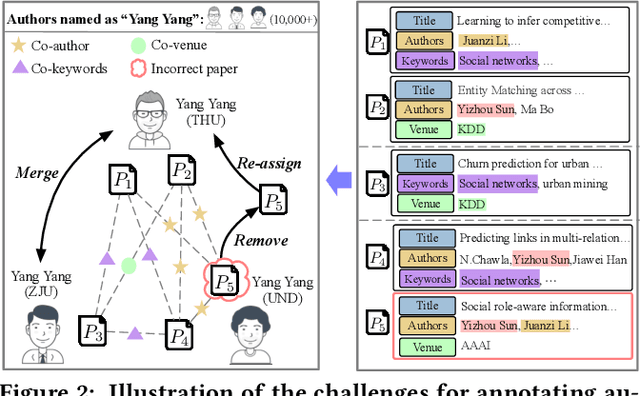
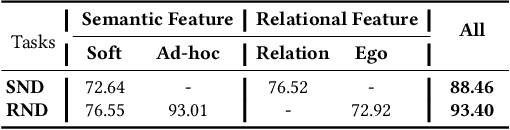
Name disambiguation -- a fundamental problem in online academic systems -- is now facing greater challenges with the increasing growth of research papers. For example, on AMiner, an online academic search platform, about 10% of names own more than 100 authors. Such real-world hard cases cannot be fully addressed by existing research efforts, because of the small-scale or low-quality datasets that they use to build algorithms. The development of effective algorithms is further hampered by a variety of tasks and evaluation protocols designed on top of diverse datasets. To this end, we present WhoIsWho owning, a large-scale benchmark with over 1,000,000 papers built using an interactive annotation process, a regular leaderboard with comprehensive tasks, and an easy-to-use toolkit encapsulating the entire pipeline as well as the most powerful features and baseline models for tackling the tasks. Our developed strong baseline has already been deployed online in the AMiner system to enable daily arXiv paper assignments. The documentation and regular leaderboards are publicly available at http://whoiswho.biendata.xyz/.