 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-OCR Technical Report
Mar 11, 2026GLM-OCR is an efficient 0.9B-parameter compact multimodal model designed for real-world document understanding. It combines a 0.4B-parameter CogViT visual encoder with a 0.5B-parameter GLM language decoder, achieving a strong balance between computational efficiency and recognition performance. To address the inefficiency of standard autoregressive decoding in deterministic OCR tasks, GLM-OCR introduces a Multi-Token Prediction (MTP) mechanism that predicts multiple tokens per step, significantly improving decoding throughput while keeping memory overhead low through shared parameters. At the system level, a two-stage pipeline is adopted: PP-DocLayout-V3 first performs layout analysis, followed by parallel region-level recognition. Extensive evaluations on public benchmarks and industrial scenarios show that GLM-OCR achieves competitive or state-of-the-art performance in document parsing, text and formula transcription, table structure recovery, and key information extraction. Its compact architecture and structured generation make it suitable for both resource-constrained edge deployment and large-scale production systems.
TraceSIR: A Multi-Agent Framework for Structured Analysis and Reporting of Agentic Execution Traces
Feb 28, 2026Agentic systems augment large language models with external tools and iterative decision making, enabling complex tasks such as deep research, function calling, and coding. However, their long and intricate execution traces make failure diagnosis and root cause analysis extremely challenging. Manual inspection does not scale, while directly applying LLMs to raw traces is hindered by input length limits and unreliable reasoning. Focusing solely on final task outcomes further discards critical behavioral information required for accurate issue localization. To address these issues, we propose TraceSIR, a multi-agent framework for structured analysis and reporting of agentic execution traces. TraceSIR coordinates three specialized agents: (1) StructureAgent, which introduces a novel abstraction format, TraceFormat, to compress execution traces while preserving essential behavioral information; (2) InsightAgent, which performs fine-grained diagnosis including issue localization, root cause analysis, and optimization suggestions; (3) ReportAgent, which aggregates insights across task instances and generates comprehensive analysis reports. To evaluate TraceSIR, we construct TraceBench, covering three real-world agentic scenarios, and introduce ReportEval, an evaluation protocol for assessing the quality and usability of analysis reports aligned with industry needs. Experiments show that TraceSIR consistently produces coherent, informative, and actionable reports, significantly outperforming existing approaches across all evaluation dimensions. Our project and video are publicly available at https://github.com/SHU-XUN/TraceSIR.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering
Oct 23, 2024Long-Context Question Answering (LCQA), a challenging task, aims to reason over long-context documents to yield accurate answers to questions. Existing long-context Large Language Models (LLMs) for LCQA often struggle with the "lost in the middle" issue. Retrieval-Augmented Generation (RAG) mitigates this issue by providing external factual evidence. However, its chunking strategy disrupts the global long-context information, and its low-quality retrieval in long contexts hinders LLMs from identifying effective factual details due to substantial noise. To this end, we propose LongRAG, a general, dual-perspective, and robust LLM-based RAG system paradigm for LCQA to enhance RAG's understanding of complex long-context knowledge (i.e., global information and factual details). We design LongRAG as a plug-and-play paradigm, facilitating adaptation to various domains and LLMs. Extensive experiments on three multi-hop datasets demonstrate that LongRAG significantly outperforms long-context LLMs (up by 6.94%), advanced RAG (up by 6.16%), and Vanilla RAG (up by 17.25%). Furthermore, we conduct quantitative ablation studies and multi-dimensional analyses, highlighting the effectiveness of the system's components and fine-tuning strategies. Data and code are available at https://github.com/QingFei1/LongRAG.
Pre-Training and Prompting for Few-Shot Node Classification on Text-Attributed Graphs
Jul 22, 2024
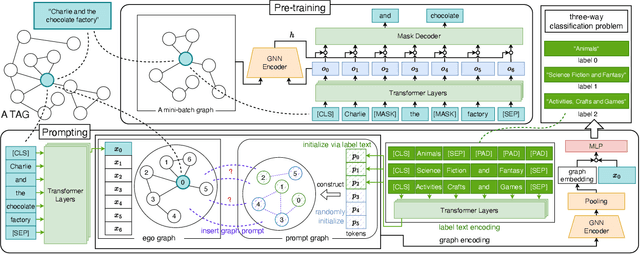
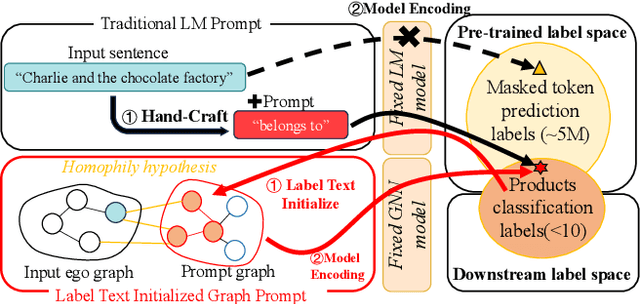
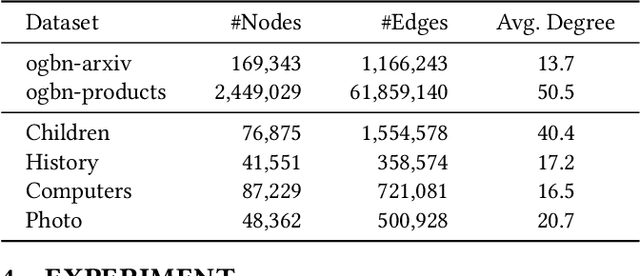
The text-attributed graph (TAG) is one kind of important real-world graph-structured data with each node associated with raw texts. For TAGs, traditional few-shot node classification methods directly conduct training on the pre-processed node features and do not consider the raw texts. The performance is highly dependent on the choice of the feature pre-processing method. In this paper, we propose P2TAG, a framework designed for few-shot node classification on TAGs with graph pre-training and prompting. P2TAG first pre-trains the language model (LM) and graph neural network (GNN) on TAGs with self-supervised loss. To fully utilize the ability of language models, we adapt the masked language modeling objective for our framework. The pre-trained model is then used for the few-shot node classification with a mixed prompt method, which simultaneously considers both text and graph information. We conduct experiments on six real-world TAGs, including paper citation networks and product co-purchasing networks. Experimental results demonstrate that our proposed framework outperforms existing graph few-shot learning methods on these datasets with +18.98% ~ +35.98% improvements.
Generalizing Graph Transformers Across Diverse Graphs and Tasks via Pre-Training on Industrial-Scale Data
Jul 04, 2024Graph pre-training has been concentrated on graph-level on small graphs (e.g., molecular graphs) or learning node representations on a fixed graph. Extending graph pre-trained models to web-scale graphs with billions of nodes in industrial scenarios, while avoiding negative transfer across graphs or tasks, remains a challenge. We aim to develop a general graph pre-trained model with inductive ability that can make predictions for unseen new nodes and even new graphs. In this work, we introduce a scalable transformer-based graph pre-training framework called PGT (Pre-trained Graph Transformer). Specifically, we design a flexible and scalable graph transformer as the backbone network. Meanwhile, based on the masked autoencoder architecture, we design two pre-training tasks: one for reconstructing node features and the other one for reconstructing local structures. Unlike the original autoencoder architecture where the pre-trained decoder is discarded, we propose a novel strategy that utilizes the decoder for feature augmentation. We have deployed our framework on Tencent's online game data. Extensive experiments have demonstrated that our framework can perform pre-training on real-world web-scale graphs with over 540 million nodes and 12 billion edges and generalizes effectively to unseen new graphs with different downstream tasks. We further conduct experiments on the publicly available ogbn-papers100M dataset, which consists of 111 million nodes and 1.6 billion edges. Our framework achieves state-of-the-art performance on both industrial datasets and public datasets, while also enjoying scalability and efficiency.
GraphAlign: Pretraining One Graph Neural Network on Multiple Graphs via Feature Alignment
Jun 05, 2024Graph self-supervised learning (SSL) holds considerable promise for mining and learning with graph-structured data. Yet, a significant challenge in graph SSL lies in the feature discrepancy among graphs across different domains. In this work, we aim to pretrain one graph neural network (GNN) on a varied collection of graphs endowed with rich node features and subsequently apply the pretrained GNN to unseen graphs. We present a general GraphAlign method that can be seamlessly integrated into the existing graph SSL framework. To align feature distributions across disparate graphs, GraphAlign designs alignment strategies of feature encoding, normalization, alongside a mixture-of-feature-expert module. Extensive experiments show that GraphAlign empowers existing graph SSL frameworks to pretrain a unified and powerful GNN across multiple graphs, showcasing performance superiority on both in-domain and out-of-domain graphs.
Does Negative Sampling Matter? A Review with Insights into its Theory and Applications
Feb 27, 2024



Negative sampling has swiftly risen to prominence as a focal point of research, with wide-ranging applications spanning machine learning, computer vision, natural language processing, data mining, and recommender systems. This growing interest raises several critical questions: Does negative sampling really matter? Is there a general framework that can incorporate all existing negative sampling methods? In what fields is it applied? Addressing these questions, we propose a general framework that leverages negative sampling. Delving into the history of negative sampling, we trace the development of negative sampling through five evolutionary paths. We dissect and categorize the strategies used to select negative sample candidates, detailing global, local, mini-batch, hop, and memory-based approaches. Our review categorizes current negative sampling methods into five types: static, hard, GAN-based, Auxiliary-based, and In-batch methods, providing a clear structure for understanding negative sampling. Beyond detailed categorization, we highlight the application of negative sampling in various areas, offering insights into its practical benefits. Finally, we briefly discuss open problems and future directions for negative sampling.
PST-Bench: Tracing and Benchmarking the Source of Publications
Feb 25, 2024



Tracing the source of research papers is a fundamental yet challenging task for researchers. The billion-scale citation relations between papers hinder researchers from understanding the evolution of science efficiently. To date, there is still a lack of an accurate and scalable dataset constructed by professional researchers to identify the direct source of their studied papers, based on which automatic algorithms can be developed to expand the evolutionary knowledge of science. In this paper, we study the problem of paper source tracing (PST) and construct a high-quality and ever-increasing dataset PST-Bench in computer science. Based on PST-Bench, we reveal several intriguing discoveries, such as the differing evolution patterns across various topics. An exploration of various methods underscores the hardness of PST-Bench, pinpointing potential directions on this topic. The dataset and codes have been available at https://github.com/THUDM/paper-source-trace.
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.