 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Jan 14, 2026Understanding research papers remains challenging for foundation models due to specialized scientific discourse and complex figures and tables, yet existing benchmarks offer limited fine-grained evaluation at scale. To address this gap, we introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges of high-quality computer science papers, containing 15K human-verified QA pairs. We design a fine-grained taxonomy aligned with the scientific research flow to assess models' ability to understand and answer why, what, and how questions in scholarly contexts. We also define an elaborate LLM-human interaction annotation framework to support large-scale labeling and quality control. Following the LLM-as-a-Judge paradigm, we develop a scalable framework that evaluates models on correctness-completeness and conciseness, with high agreement to human judgment. Experiments reveal that even the strongest models (GPT-5) achieve only 68.2% correctness-completeness, dropping to 37.46% after conciseness adjustment, highlighting substantial gaps in precise academic paper understanding. Our code and data are available at https://rpc-bench.github.io/.
Small Language Model Makes an Effective Long Text Extractor
Feb 11, 2025
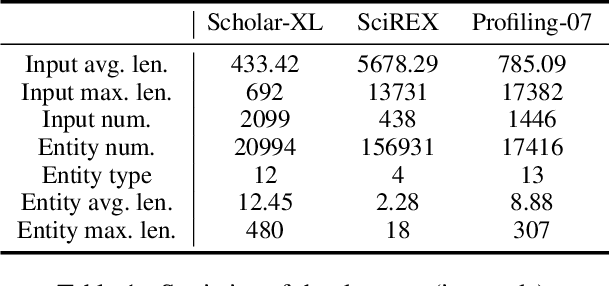
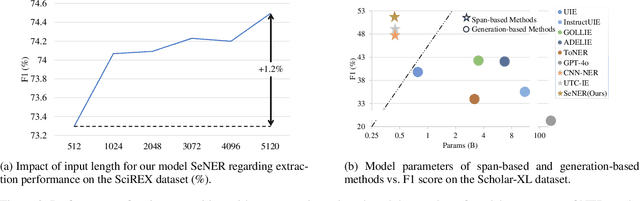
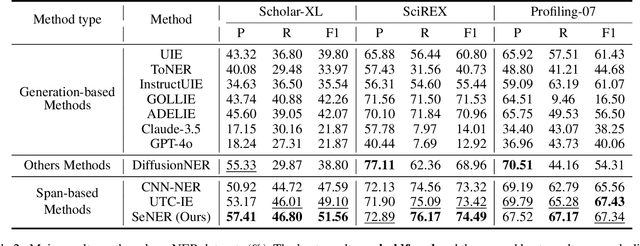
Named Entity Recognition (NER) is a fundamental problem in natural language processing (NLP). However, the task of extracting longer entity spans (e.g., awards) from extended texts (e.g., homepages) is barely explored. Current NER methods predominantly fall into two categories: span-based methods and generation-based methods. Span-based methods require the enumeration of all possible token-pair spans, followed by classification on each span, resulting in substantial redundant computations and excessive GPU memory usage. In contrast, generation-based methods involve prompting or fine-tuning large language models (LLMs) to adapt to downstream NER tasks. However, these methods struggle with the accurate generation of longer spans and often incur significant time costs for effective fine-tuning. To address these challenges, this paper introduces a lightweight span-based NER method called SeNER, which incorporates a bidirectional arrow attention mechanism coupled with LogN-Scaling on the [CLS] token to embed long texts effectively, and comprises a novel bidirectional sliding-window plus-shaped attention (BiSPA) mechanism to reduce redundant candidate token-pair spans significantly and model interactions between token-pair spans simultaneously. Extensive experiments demonstrate that our method achieves state-of-the-art extraction accuracy on three long NER datasets and is capable of extracting entities from long texts in a GPU-memory-friendly manner. Code: https://github.com/THUDM/scholar-profiling/tree/main/sener
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.