 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Jan 14, 2026Understanding research papers remains challenging for foundation models due to specialized scientific discourse and complex figures and tables, yet existing benchmarks offer limited fine-grained evaluation at scale. To address this gap, we introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges of high-quality computer science papers, containing 15K human-verified QA pairs. We design a fine-grained taxonomy aligned with the scientific research flow to assess models' ability to understand and answer why, what, and how questions in scholarly contexts. We also define an elaborate LLM-human interaction annotation framework to support large-scale labeling and quality control. Following the LLM-as-a-Judge paradigm, we develop a scalable framework that evaluates models on correctness-completeness and conciseness, with high agreement to human judgment. Experiments reveal that even the strongest models (GPT-5) achieve only 68.2% correctness-completeness, dropping to 37.46% after conciseness adjustment, highlighting substantial gaps in precise academic paper understanding. Our code and data are available at https://rpc-bench.github.io/.
HopWeaver: Synthesizing Authentic Multi-Hop Questions Across Text Corpora
May 21, 2025Multi-Hop Question Answering (MHQA) is crucial for evaluating the model's capability to integrate information from diverse sources. However, creating extensive and high-quality MHQA datasets is challenging: (i) manual annotation is expensive, and (ii) current synthesis methods often produce simplistic questions or require extensive manual guidance. This paper introduces HopWeaver, the first automatic framework synthesizing authentic multi-hop questions from unstructured text corpora without human intervention. HopWeaver synthesizes two types of multi-hop questions (bridge and comparison) using an innovative approach that identifies complementary documents across corpora. Its coherent pipeline constructs authentic reasoning paths that integrate information across multiple documents, ensuring synthesized questions necessitate authentic multi-hop reasoning. We further present a comprehensive system for evaluating synthesized multi-hop questions. Empirical evaluations demonstrate that the synthesized questions achieve comparable or superior quality to human-annotated datasets at a lower cost. Our approach is valuable for developing MHQA datasets in specialized domains with scarce annotated resources. The code for HopWeaver is publicly available.
MIND: Effective Incorrect Assignment Detection through a Multi-Modal Structure-Enhanced Language Model
Dec 05, 2024
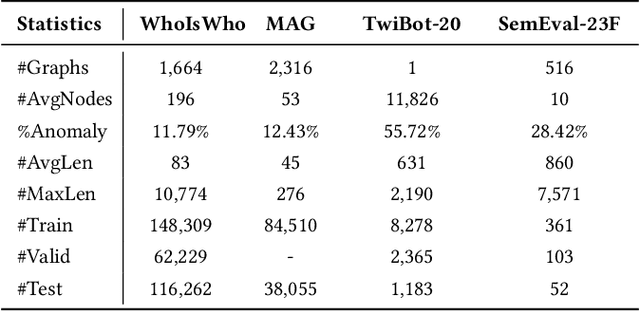
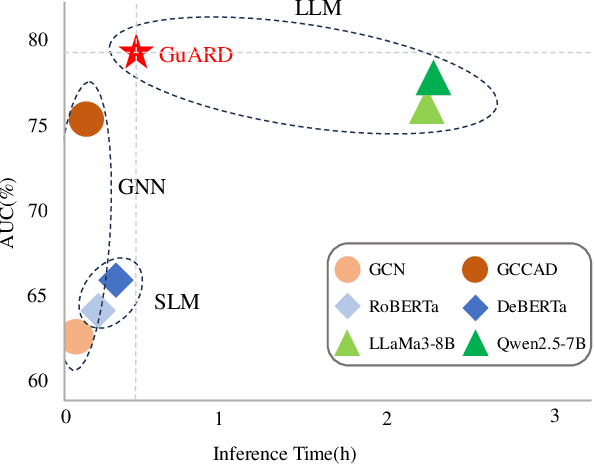
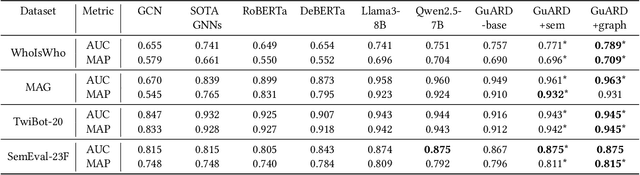
The rapid growth of academic publications has exacerbated the issue of author name ambiguity in online digital libraries. Despite advances in name disambiguation algorithms, cumulative errors continue to undermine the reliability of academic systems. It is estimated that over 10% paper-author assignments are rectified when constructing the million-scale WhoIsWho benchmark. Existing endeavors to detect incorrect assignments are either semantic-based or graph-based approaches, which fall short of making full use of the rich text attributes of papers and implicit structural features defined via the co-occurrence of paper attributes. To this end, this paper introduces a structure-enhanced language model that combines key structural features from graph-based methods with fine-grained semantic features from rich paper attributes to detect incorrect assignments. The proposed model is trained with a highly effective multi-modal multi-turn instruction tuning framework, which incorporates task-guided instruction tuning, text-attribute modality, and structural modality. Experimental results demonstrate that our model outperforms previous approaches, achieving top performance on the leaderboard of KDD Cup 2024. Our code has been publicly available.
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024



With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.