 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBefore Fusion, Ask What to Keep: Contextual Calibration of Multimodal Signals
Jun 01, 2026Multimodal systems often benefit from combining information across language, sound, and visual streams, but this benefit is not guaranteed. A modality that is useful for one input may become distracting for another, and local feature responses within the same modality can disagree with evidence from other sources. This work investigates how to adjust multimodal representations before they are merged by a downstream predictor. We develop a compact calibration module that compares each modality with the others at the summary level, extracts cues of cross-source support and conflict, and converts these cues into instance-wise and dimension-wise modulation signals. The calibration is applied to the original modality features rather than to already fused representations, enabling the model to suppress misleading components, preserve weak but useful evidence, and emphasize responses that are better supported by the current multimodal context. The module is designed as a plug-in component and can be attached to different fusion backbones without changing their prediction heads. Across five benchmarks covering sentiment understanding, action recognition, audio-visual event detection, and audio-visual emotion classification, the proposed pre-combination calibration strategy improves performance under both sequence-based and convolutional fusion settings. Additional analyses under modality removal, synthetic corruption, training dynamics, and feature-level visualization show that calibrating signals before fusion can reduce interference from unreliable modalities and produce more stable multimodal optimization.
M$^4$-SAM: Multi-Modal Mixture-of-Experts with Memory-Augmented SAM for RGB-D Video Salient Object Detection
May 12, 2026The Segment Anything Model 2 (SAM2) has emerged as a foundation model for universal segmentation. Owing to its generalizable visual representations, SAM2 has been successfully applied to various downstream tasks. However, extending SAM2 to the RGB-D video salient object detection (RGB-D VSOD) task encounters three challenges including limited spatial modeling of linear LoRA, insufficient employment of SAM's multi-scale features, and dependence of initialization on explicit prompts. To address the issues, we present Multi-Modal Mixture-of-Experts with Memory-Augmented SAM (M$^4$-SAM), which equips SAM2 with modality-related PEFT, hierarchical feature fusion, and prompt-free memory initialization. Firstly, we inject Modality-Aware MoE-LORA, which employs convolutional experts to encode local spatial priors and introduces a modality dispatcher for efficient multi-modal fine-tuning, into SAM2's encoder. Secondly, we deploy Gated Multi-Level Feature Fusion, which hierarchically aggregates multi-scale encoder features with an adaptive gating mechanism, to balance spatial details and semantic context. Finally, to conduct zero-shot VSOD without manual prompts, we utilize a Pseudo-Guided Initialization, where a coarse mask is regarded as a pseudo prior and used to bootstrap the memory bank. Extensive experiments demonstrate that M$^4$-SAM achieves the state-of-the-art performance across all evaluation metrics on three public RGB-D VSOD datasets.
Decoupled Travel Planning with Behavior Forest
Apr 23, 2026Behavior sequences, composed of executable steps, serve as the operational foundation for multi-constraint planning problems such as travel planning. In such tasks, each planning step is not only constrained locally but also influenced by global constraints spanning multiple subtasks, leading to a tightly coupled and complex decision process. Existing travel planning methods typically rely on a single decision space that entangles all subtasks and constraints, failing to distinguish between locally acting constraints within a subtask and global constraints that span multiple subtasks. Consequently, the model is forced to jointly reason over local and global constraints at each decision step, increasing the reasoning burden and reducing planning efficiency. To address this problem, we propose the Behavior Forest method. Specifically, our approach structures the decision-making process into a forest of parallel behavior trees, where each behavior tree is responsible for a subtask. A global coordination mechanism is introduced to orchestrate the interactions among these trees, enabling modular and coherent travel planning. Within this framework, large language models are embedded as decision engines within behavior tree nodes, performing localized reasoning conditioned on task-specific constraints to generate candidate subplans and adapt decisions based on coordination feedback. The behavior trees, in turn, provide an explicit control structure that guides LLM generation. This design decouples complex tasks and constraints into manageable subspaces, enabling task-specific reasoning and reducing the cognitive load of LLM. Experimental results show that our method outperforms state-of-the-art methods by 6.67% on the TravelPlanner and by 11.82% on the ChinaTravel benchmarks, demonstrating its effectiveness in increasing LLM performance for complex multi-constraint travel planning.
SAM-DAQ: Segment Anything Model with Depth-guided Adaptive Queries for RGB-D Video Salient Object Detection
Nov 13, 2025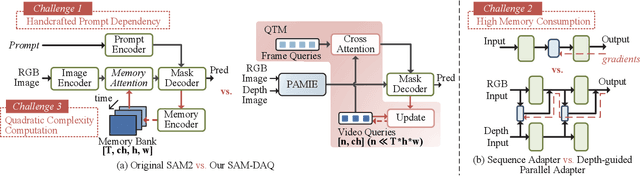
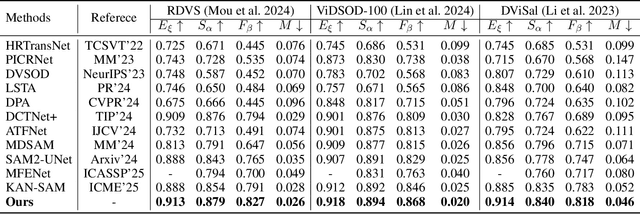
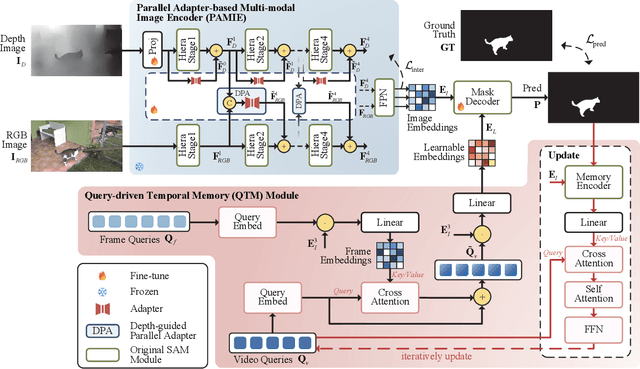
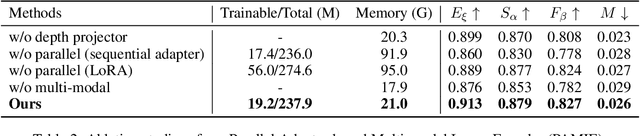
Recently segment anything model (SAM) has attracted widespread concerns, and it is often treated as a vision foundation model for universal segmentation. Some researchers have attempted to directly apply the foundation model to the RGB-D video salient object detection (RGB-D VSOD) task, which often encounters three challenges, including the dependence on manual prompts, the high memory consumption of sequential adapters, and the computational burden of memory attention. To address the limitations, we propose a novel method, namely Segment Anything Model with Depth-guided Adaptive Queries (SAM-DAQ), which adapts SAM2 to pop-out salient objects from videos by seamlessly integrating depth and temporal cues within a unified framework. Firstly, we deploy a parallel adapter-based multi-modal image encoder (PAMIE), which incorporates several depth-guided parallel adapters (DPAs) in a skip-connection way. Remarkably, we fine-tune the frozen SAM encoder under prompt-free conditions, where the DPA utilizes depth cues to facilitate the fusion of multi-modal features. Secondly, we deploy a query-driven temporal memory (QTM) module, which unifies the memory bank and prompt embeddings into a learnable pipeline. Concretely, by leveraging both frame-level queries and video-level queries simultaneously, the QTM module can not only selectively extract temporal consistency features but also iteratively update the temporal representations of the queries. Extensive experiments are conducted on three RGB-D VSOD datasets, and the results show that the proposed SAM-DAQ consistently outperforms state-of-the-art methods in terms of all evaluation metrics.
Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery
Jul 16, 2025In this paper, we address the problem of novel class discovery (NCD), which aims to cluster novel classes by leveraging knowledge from disjoint known classes. While recent advances have made significant progress in this area, existing NCD methods face two major limitations. First, they primarily focus on single-view data (e.g., images), overlooking the increasingly common multi-view data, such as multi-omics datasets used in disease diagnosis. Second, their reliance on pseudo-labels to supervise novel class clustering often results in unstable performance, as pseudo-label quality is highly sensitive to factors such as data noise and feature dimensionality. To address these challenges, we propose a novel framework named Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery (IICMVNCD), which is the first attempt to explore NCD in multi-view setting so far. Specifically, at the intra-view level, leveraging the distributional similarity between known and novel classes, we employ matrix factorization to decompose features into view-specific shared base matrices and factor matrices. The base matrices capture distributional consistency among the two datasets, while the factor matrices model pairwise relationships between samples. At the inter-view level, we utilize view relationships among known classes to guide the clustering of novel classes. This includes generating predicted labels through the weighted fusion of factor matrices and dynamically adjusting view weights of known classes based on the supervision loss, which are then transferred to novel class learning. Experimental results validate the effectiveness of our proposed approach.
HopWeaver: Synthesizing Authentic Multi-Hop Questions Across Text Corpora
May 21, 2025Multi-Hop Question Answering (MHQA) is crucial for evaluating the model's capability to integrate information from diverse sources. However, creating extensive and high-quality MHQA datasets is challenging: (i) manual annotation is expensive, and (ii) current synthesis methods often produce simplistic questions or require extensive manual guidance. This paper introduces HopWeaver, the first automatic framework synthesizing authentic multi-hop questions from unstructured text corpora without human intervention. HopWeaver synthesizes two types of multi-hop questions (bridge and comparison) using an innovative approach that identifies complementary documents across corpora. Its coherent pipeline constructs authentic reasoning paths that integrate information across multiple documents, ensuring synthesized questions necessitate authentic multi-hop reasoning. We further present a comprehensive system for evaluating synthesized multi-hop questions. Empirical evaluations demonstrate that the synthesized questions achieve comparable or superior quality to human-annotated datasets at a lower cost. Our approach is valuable for developing MHQA datasets in specialized domains with scarce annotated resources. The code for HopWeaver is publicly available.
Active-Passive Federated Learning for Vertically Partitioned Multi-view Data
Sep 06, 2024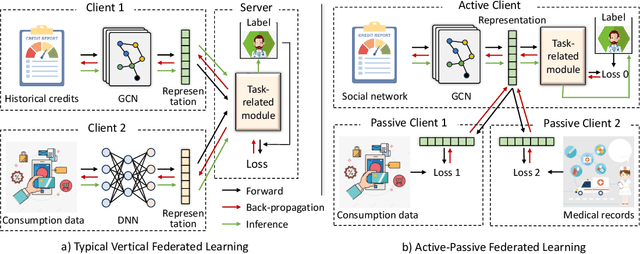


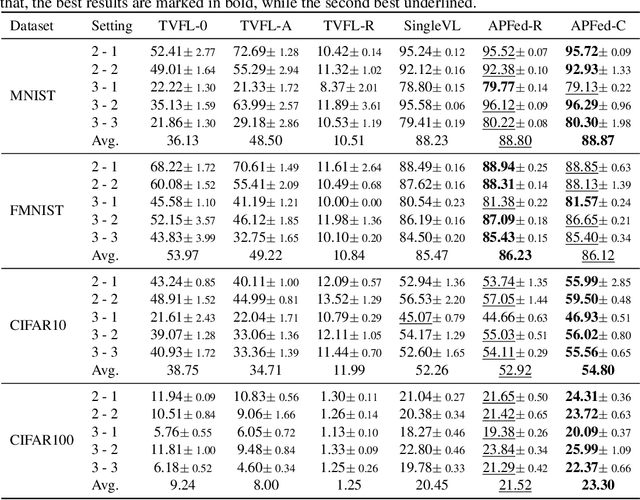
Vertical federated learning is a natural and elegant approach to integrate multi-view data vertically partitioned across devices (clients) while preserving their privacies. Apart from the model training, existing methods requires the collaboration of all clients in the model inference. However, the model inference is probably maintained for service in a long time, while the collaboration, especially when the clients belong to different organizations, is unpredictable in real-world scenarios, such as concellation of contract, network unavailablity, etc., resulting in the failure of them. To address this issue, we, at the first attempt, propose a flexible Active-Passive Federated learning (APFed) framework. Specifically, the active client is the initiator of a learning task and responsible to build the complete model, while the passive clients only serve as assistants. Once the model built, the active client can make inference independently. In addition, we instance the APFed framework into two classification methods with employing the reconstruction loss and the contrastive loss on passive clients, respectively. Meanwhile, the two methods are tested in a set of experiments and achieves desired results, validating their effectiveness.
Contrastive Continual Multi-view Clustering with Filtered Structural Fusion
Sep 26, 2023
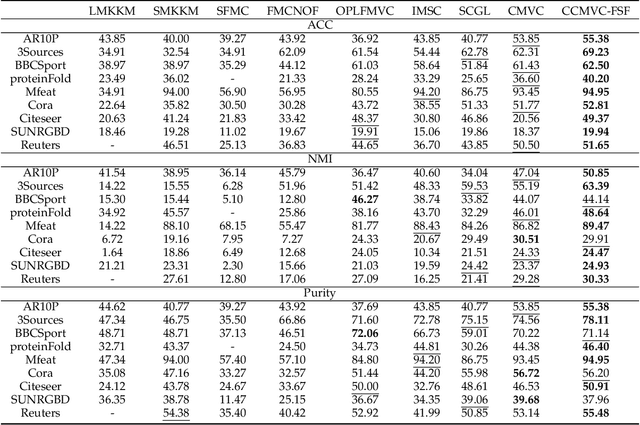

Multi-view clustering thrives in applications where views are collected in advance by extracting consistent and complementary information among views. However, it overlooks scenarios where data views are collected sequentially, i.e., real-time data. Due to privacy issues or memory burden, previous views are not available with time in these situations. Some methods are proposed to handle it but are trapped in a stability-plasticity dilemma. In specific, these methods undergo a catastrophic forgetting of prior knowledge when a new view is attained. Such a catastrophic forgetting problem (CFP) would cause the consistent and complementary information hard to get and affect the clustering performance. To tackle this, we propose a novel method termed Contrastive Continual Multi-view Clustering with Filtered Structural Fusion (CCMVC-FSF). Precisely, considering that data correlations play a vital role in clustering and prior knowledge ought to guide the clustering process of a new view, we develop a data buffer with fixed size to store filtered structural information and utilize it to guide the generation of a robust partition matrix via contrastive learning. Furthermore, we theoretically connect CCMVC-FSF with semi-supervised learning and knowledge distillation. Extensive experiments exhibit the excellence of the proposed method.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023



The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023
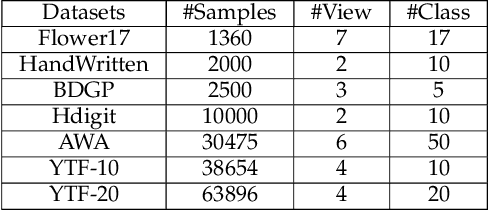
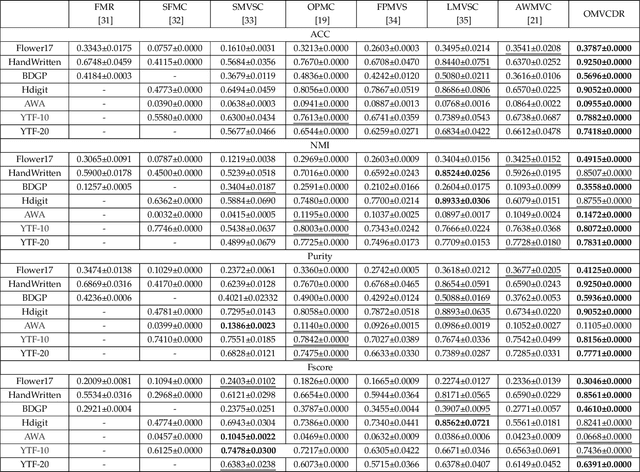

Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.