 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Source Reasoning-based Correction for Author Name Disambiguation
Jun 07, 2026Author name disambiguation is a critical challenge in academic search systems, often addressed through from-scratch and real-time disambiguation approaches. However, current algorithms remain vulnerable to cumulative errors of paper-author assignments and overlook inconsistent assignments across different sources. Resorting to expert annotation is resource-intensive. To this end, this paper explores a new perspective for author name disambiguation: cross-source correction by leveraging inconsistent assignments across sources. We propose CrossND, a full-stack framework that integrates data refinement, cross-source reasoning, and test-time scaling. First, a chain-of-refinement pipeline denoises author profiles and produces more accurate paper-author matching probabilities. Second, a supervised fine-tuning process incorporates these refined signals and a probabilistic soft logic-based cross-correction module to infer the assignments of which sources are incorrect. Third, test-time scaling further enhances the accuracy and robustness of the predictions. Experiments on real-world datasets indicate that CrossND consistently outperforms 17 baselines by leveraging cross-source reasoning without human intervention.
A Finite-Calibration Regime Map for LLM Judge Panels
May 31, 2026We study when LLM judge panels should be calibrated with low-dimensional stackers versus joint output tables under finite human-label budgets. Low-dimensional stackers have small estimation cost but miss interactions, whereas joint-table calibrators can represent interactions but pay for cell counts and unseen patterns. We cast this tradeoff as a finite-calibration regime map and instantiate it as Finite-Calibration Panel Selection, a deployable validation selector over judge path, prefix size, and aggregator family with table and parametric estimation diagnostics. On RewardBench, LLMBar, SummEval, and Arena100K with a seven-judge pool including DeepSeek V4 Flash, scalar/reliability aggregation wins 16 of 20 real dataset--budget cells, indicating that current judge outputs are often additive or redundant. Controlled calibration-growth data show the complementary regime: additive labels remain scalar-favored, whereas a six-way interaction selects a larger joint table and its test MSE drops from 0.224 to 0.061 once unseen mass vanishes. Thus the practical question is not ``how many judges?'' but whether the next judge's information is estimable under the available human labels.
Double-Calibration: Towards Trustworthy LLMs via Calibrating Knowledge and Reasoning Confidence
Jan 17, 2026Trustworthy reasoning in Large Language Models (LLMs) is challenged by their propensity for hallucination. While augmenting LLMs with Knowledge Graphs (KGs) improves factual accuracy, existing KG-augmented methods fail to quantify epistemic uncertainty in both the retrieved evidence and LLMs' reasoning. To bridge this gap, we introduce DoublyCal, a framework built on a novel double-calibration principle. DoublyCal employs a lightweight proxy model to first generate KG evidence alongside a calibrated evidence confidence. This calibrated supporting evidence then guides a black-box LLM, yielding final predictions that are not only more accurate but also well-calibrated, with confidence scores traceable to the uncertainty of the supporting evidence. Experiments on knowledge-intensive benchmarks show that DoublyCal significantly improves both the accuracy and confidence calibration of black-box LLMs with low token cost.
HopWeaver: Synthesizing Authentic Multi-Hop Questions Across Text Corpora
May 21, 2025Multi-Hop Question Answering (MHQA) is crucial for evaluating the model's capability to integrate information from diverse sources. However, creating extensive and high-quality MHQA datasets is challenging: (i) manual annotation is expensive, and (ii) current synthesis methods often produce simplistic questions or require extensive manual guidance. This paper introduces HopWeaver, the first automatic framework synthesizing authentic multi-hop questions from unstructured text corpora without human intervention. HopWeaver synthesizes two types of multi-hop questions (bridge and comparison) using an innovative approach that identifies complementary documents across corpora. Its coherent pipeline constructs authentic reasoning paths that integrate information across multiple documents, ensuring synthesized questions necessitate authentic multi-hop reasoning. We further present a comprehensive system for evaluating synthesized multi-hop questions. Empirical evaluations demonstrate that the synthesized questions achieve comparable or superior quality to human-annotated datasets at a lower cost. Our approach is valuable for developing MHQA datasets in specialized domains with scarce annotated resources. The code for HopWeaver is publicly available.
iTFKAN: Interpretable Time Series Forecasting with Kolmogorov-Arnold Network
Apr 23, 2025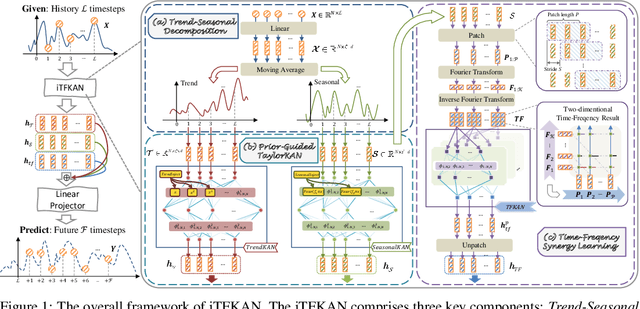



As time evolves, data within specific domains exhibit predictability that motivates time series forecasting to predict future trends from historical data. However, current deep forecasting methods can achieve promising performance but generally lack interpretability, hindering trustworthiness and practical deployment in safety-critical applications such as auto-driving and healthcare. In this paper, we propose a novel interpretable model, iTFKAN, for credible time series forecasting. iTFKAN enables further exploration of model decision rationales and underlying data patterns due to its interpretability achieved through model symbolization. Besides, iTFKAN develops two strategies, prior knowledge injection, and time-frequency synergy learning, to effectively guide model learning under complex intertwined time series data. Extensive experimental results demonstrated that iTFKAN can achieve promising forecasting performance while simultaneously possessing high interpretive capabilities.
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
MIND: Effective Incorrect Assignment Detection through a Multi-Modal Structure-Enhanced Language Model
Dec 05, 2024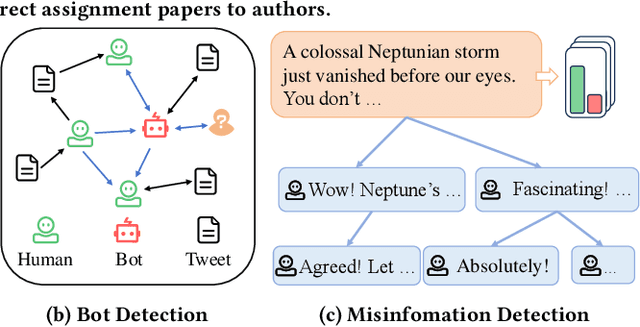
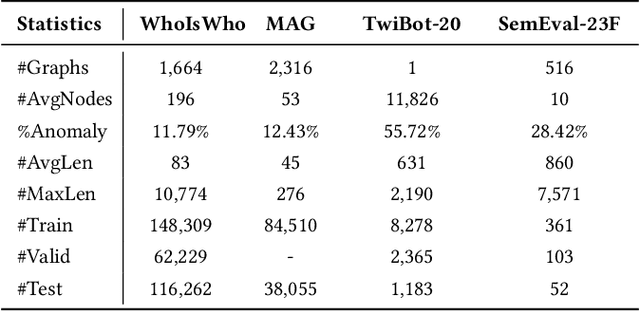
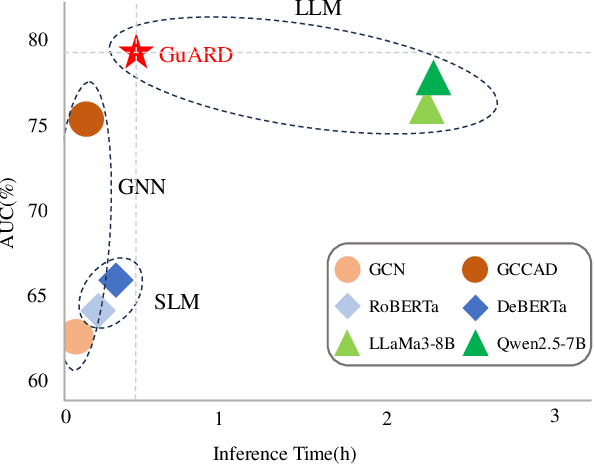
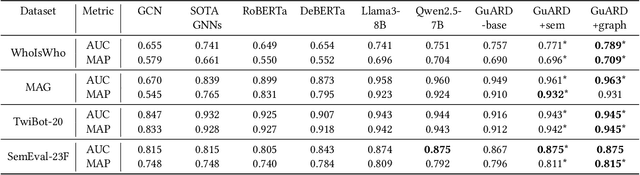
The rapid growth of academic publications has exacerbated the issue of author name ambiguity in online digital libraries. Despite advances in name disambiguation algorithms, cumulative errors continue to undermine the reliability of academic systems. It is estimated that over 10% paper-author assignments are rectified when constructing the million-scale WhoIsWho benchmark. Existing endeavors to detect incorrect assignments are either semantic-based or graph-based approaches, which fall short of making full use of the rich text attributes of papers and implicit structural features defined via the co-occurrence of paper attributes. To this end, this paper introduces a structure-enhanced language model that combines key structural features from graph-based methods with fine-grained semantic features from rich paper attributes to detect incorrect assignments. The proposed model is trained with a highly effective multi-modal multi-turn instruction tuning framework, which incorporates task-guided instruction tuning, text-attribute modality, and structural modality. Experimental results demonstrate that our model outperforms previous approaches, achieving top performance on the leaderboard of KDD Cup 2024. Our code has been publicly available.
IterSelectTune: An Iterative Training Framework for Efficient Instruction-Tuning Data Selection
Oct 17, 2024



As large language models (LLMs) continue to advance, instruction tuning has become critical for improving their ability to generate accurate and contextually appropriate responses. Although numerous instruction-tuning datasets have been developed to enhance LLM performance, selecting high-quality instruction data from large source datasets typically demands significant human effort. In this work, we introduce $\textbf{IterSelectTune}$, an efficient, cost-effective iterative training policy for selecting high-quality instruction data with no human involvement and limited reliance on GPT-4. By fine-tuning on approximately 20\% of the source data, our method consistently outperforms models fine-tuned on the full dataset across multiple benchmarks and public test datasets. These results highlight the effectiveness of our approach in enhancing LLM performance while reducing the computational resources required for instruction tuning.
Multimodal Clickbait Detection by De-confounding Biases Using Causal Representation Inference
Oct 10, 2024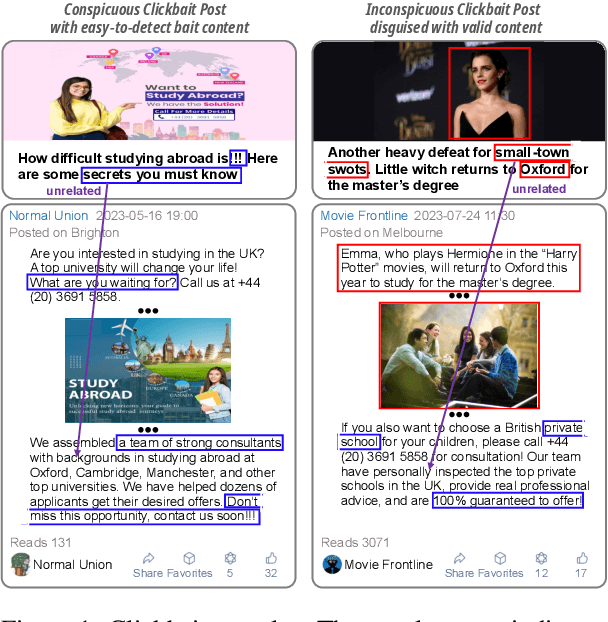
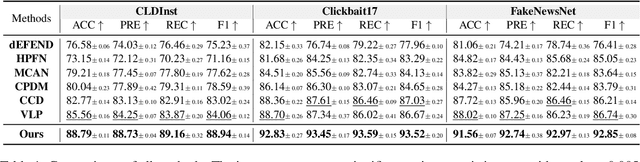
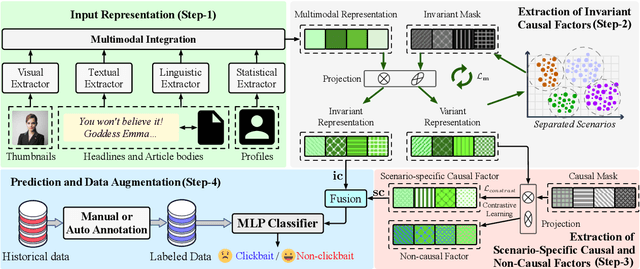

This paper focuses on detecting clickbait posts on the Web. These posts often use eye-catching disinformation in mixed modalities to mislead users to click for profit. That affects the user experience and thus would be blocked by content provider. To escape detection, malicious creators use tricks to add some irrelevant non-bait content into bait posts, dressing them up as legal to fool the detector. This content often has biased relations with non-bait labels, yet traditional detectors tend to make predictions based on simple co-occurrence rather than grasping inherent factors that lead to malicious behavior. This spurious bias would easily cause misjudgments. To address this problem, we propose a new debiased method based on causal inference. We first employ a set of features in multiple modalities to characterize the posts. Considering these features are often mixed up with unknown biases, we then disentangle three kinds of latent factors from them, including the invariant factor that indicates intrinsic bait intention; the causal factor which reflects deceptive patterns in a certain scenario, and non-causal noise. By eliminating the noise that causes bias, we can use invariant and causal factors to build a robust model with good generalization ability. Experiments on three popular datasets show the effectiveness of our approach.
Self-supervised Topic Taxonomy Discovery in the Box Embedding Space
Aug 27, 2024Topic taxonomy discovery aims at uncovering topics of different abstraction levels and constructing hierarchical relations between them. Unfortunately, most of prior work can hardly model semantic scopes of words and topics by holding the Euclidean embedding space assumption. What's worse, they infer asymmetric hierarchical relations by symmetric distances between topic embeddings. As a result, existing methods suffer from problems of low-quality topics at high abstraction levels and inaccurate hierarchical relations. To alleviate these problems, this paper develops a Box embedding-based Topic Model (BoxTM) that maps words and topics into the box embedding space, where the asymmetric metric is defined to properly infer hierarchical relations among topics. Additionally, our BoxTM explicitly infers upper-level topics based on correlation between specific topics through recursive clustering on topic boxes. Finally, extensive experiments validate high-quality of the topic taxonomy learned by BoxTM.