 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-Calibration: Towards Trustworthy LLMs via Calibrating Knowledge and Reasoning Confidence
Jan 17, 2026Trustworthy reasoning in Large Language Models (LLMs) is challenged by their propensity for hallucination. While augmenting LLMs with Knowledge Graphs (KGs) improves factual accuracy, existing KG-augmented methods fail to quantify epistemic uncertainty in both the retrieved evidence and LLMs' reasoning. To bridge this gap, we introduce DoublyCal, a framework built on a novel double-calibration principle. DoublyCal employs a lightweight proxy model to first generate KG evidence alongside a calibrated evidence confidence. This calibrated supporting evidence then guides a black-box LLM, yielding final predictions that are not only more accurate but also well-calibrated, with confidence scores traceable to the uncertainty of the supporting evidence. Experiments on knowledge-intensive benchmarks show that DoublyCal significantly improves both the accuracy and confidence calibration of black-box LLMs with low token cost.
iTFKAN: Interpretable Time Series Forecasting with Kolmogorov-Arnold Network
Apr 23, 2025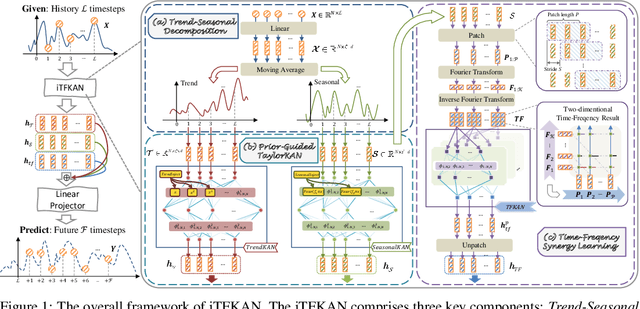



As time evolves, data within specific domains exhibit predictability that motivates time series forecasting to predict future trends from historical data. However, current deep forecasting methods can achieve promising performance but generally lack interpretability, hindering trustworthiness and practical deployment in safety-critical applications such as auto-driving and healthcare. In this paper, we propose a novel interpretable model, iTFKAN, for credible time series forecasting. iTFKAN enables further exploration of model decision rationales and underlying data patterns due to its interpretability achieved through model symbolization. Besides, iTFKAN develops two strategies, prior knowledge injection, and time-frequency synergy learning, to effectively guide model learning under complex intertwined time series data. Extensive experimental results demonstrated that iTFKAN can achieve promising forecasting performance while simultaneously possessing high interpretive capabilities.
A Survey of WebAgents: Towards Next-Generation AI Agents for Web Automation with Large Foundation Models
Mar 30, 2025With the advancement of web techniques, they have significantly revolutionized various aspects of people's lives. Despite the importance of the web, many tasks performed on it are repetitive and time-consuming, negatively impacting overall quality of life. To efficiently handle these tedious daily tasks, one of the most promising approaches is to advance autonomous agents based on Artificial Intelligence (AI) techniques, referred to as AI Agents, as they can operate continuously without fatigue or performance degradation. In the context of the web, leveraging AI Agents -- termed WebAgents -- to automatically assist people in handling tedious daily tasks can dramatically enhance productivity and efficiency. Recently, Large Foundation Models (LFMs) containing billions of parameters have exhibited human-like language understanding and reasoning capabilities, showing proficiency in performing various complex tasks. This naturally raises the question: `Can LFMs be utilized to develop powerful AI Agents that automatically handle web tasks, providing significant convenience to users?' To fully explore the potential of LFMs, extensive research has emerged on WebAgents designed to complete daily web tasks according to user instructions, significantly enhancing the convenience of daily human life. In this survey, we comprehensively review existing research studies on WebAgents across three key aspects: architectures, training, and trustworthiness. Additionally, several promising directions for future research are explored to provide deeper insights.
HiBench: Benchmarking LLMs Capability on Hierarchical Structure Reasoning
Mar 02, 2025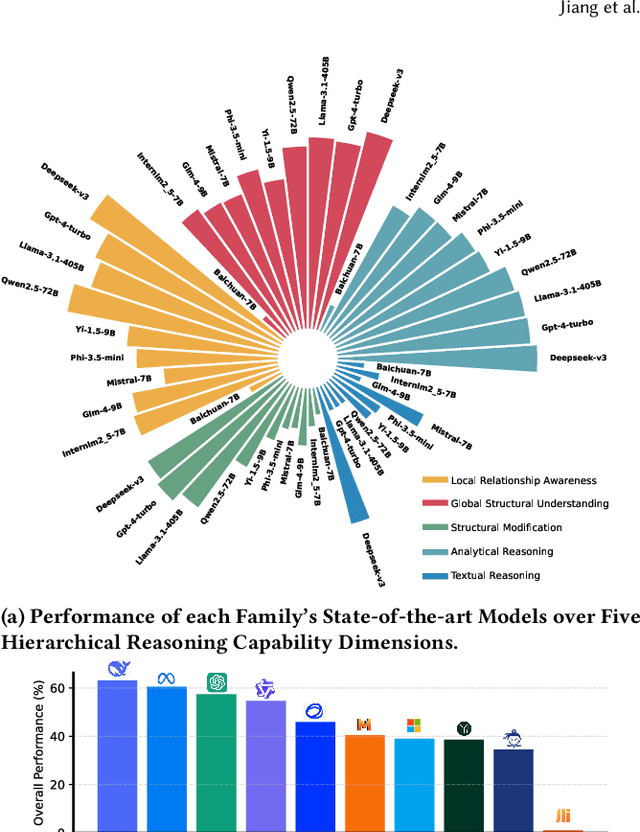
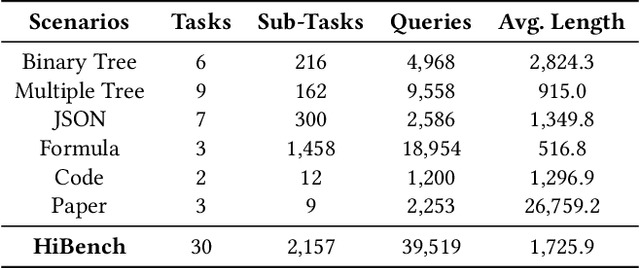
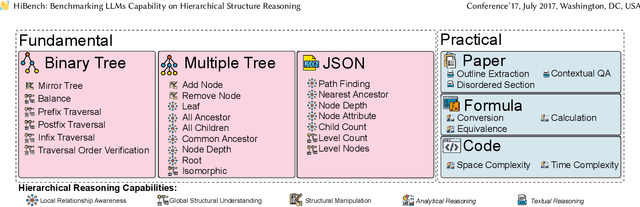
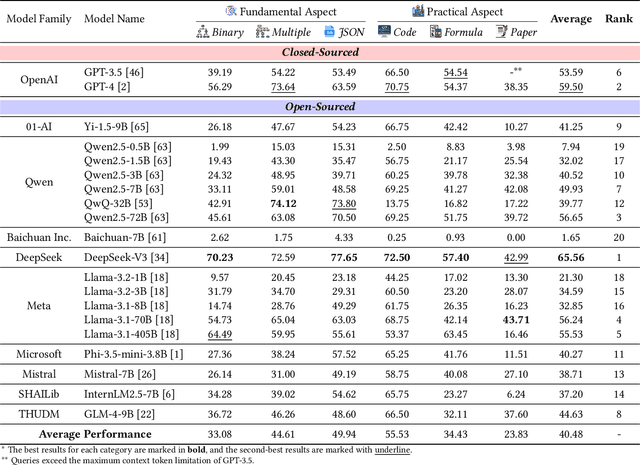
Structure reasoning is a fundamental capability of large language models (LLMs), enabling them to reason about structured commonsense and answer multi-hop questions. However, existing benchmarks for structure reasoning mainly focus on horizontal and coordinate structures (\emph{e.g.} graphs), overlooking the hierarchical relationships within them. Hierarchical structure reasoning is crucial for human cognition, particularly in memory organization and problem-solving. It also plays a key role in various real-world tasks, such as information extraction and decision-making. To address this gap, we propose HiBench, the first framework spanning from initial structure generation to final proficiency assessment, designed to benchmark the hierarchical reasoning capabilities of LLMs systematically. HiBench encompasses six representative scenarios, covering both fundamental and practical aspects, and consists of 30 tasks with varying hierarchical complexity, totaling 39,519 queries. To evaluate LLMs comprehensively, we develop five capability dimensions that depict different facets of hierarchical structure understanding. Through extensive evaluation of 20 LLMs from 10 model families, we reveal key insights into their capabilities and limitations: 1) existing LLMs show proficiency in basic hierarchical reasoning tasks; 2) they still struggle with more complex structures and implicit hierarchical representations, especially in structural modification and textual reasoning. Based on these findings, we create a small yet well-designed instruction dataset, which enhances LLMs' performance on HiBench by an average of 88.84\% (Llama-3.1-8B) and 31.38\% (Qwen2.5-7B) across all tasks. The HiBench dataset and toolkit are available here, https://github.com/jzzzzh/HiBench, to encourage evaluation.