 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop Treating Collisions Equally: Qualification-Aware Semantic ID Learning for Recommendation at Industrial Scale
Feb 28, 2026Semantic IDs (SIDs) are compact discrete representations derived from multimodal item features, serving as a unified abstraction for ID-based and generative recommendation. However, learning high-quality SIDs remains challenging due to two issues. (1) Collision problem: the quantized token space is prone to collisions, in which semantically distinct items are assigned identical or overly similar SID compositions, resulting in semantic entanglement. (2) Collision-signal heterogeneity: collisions are not uniformly harmful. Some reflect genuine conflicts between semantically unrelated items, while others stem from benign redundancy or systematic data effects. To address these challenges, we propose Qualification-Aware Semantic ID Learning (QuaSID), an end-to-end framework that learns collision-qualified SIDs by selectively repelling qualified conflict pairs and scaling the repulsion strength by collision severity. QuaSID consists of two mechanisms: Hamming-guided Margin Repulsion, which translates low-Hamming SID overlaps into explicit, severity-scaled geometric constraints on the encoder space; and Conflict-Aware Valid Pair Masking, which masks protocol-induced benign overlaps to denoise repulsion supervision. In addition, QuaSID incorporates a dual-tower contrastive objective to inject collaborative signals into tokenization. Experiments on public benchmarks and industrial data validate QuaSID. On public datasets, QuaSID consistently outperforms strong baselines, improving top-K ranking quality by 5.9% over the best baseline while increasing SID composition diversity. In an online A/B test on Kuaishou e-commerce with a 5% traffic split, QuaSID increases ranking GMV-S2 by 2.38% and improves completed orders on cold-start retrieval by up to 6.42%. Finally, we show that the proposed repulsion loss is plug-and-play and enhances a range of SID learning frameworks across datasets.
SUPERGLASSES: Benchmarking Vision Language Models as Intelligent Agents for AI Smart Glasses
Feb 26, 2026The rapid advancement of AI-powered smart glasses, one of the hottest wearable devices, has unlocked new frontiers for multimodal interaction, with Visual Question Answering (VQA) over external knowledge sources emerging as a core application. Existing Vision Language Models (VLMs) adapted to smart glasses are typically trained and evaluated on traditional multimodal datasets; however, these datasets lack the variety and realism needed to reflect smart glasses usage scenarios and diverge from their specific challenges, where accurately identifying the object of interest must precede any external knowledge retrieval. To bridge this gap, we introduce SUPERGLASSES, the first comprehensive VQA benchmark built on real-world data entirely collected by smart glasses devices. SUPERGLASSES comprises 2,422 egocentric image-question pairs spanning 14 image domains and 8 query categories, enriched with full search trajectories and reasoning annotations. We evaluate 26 representative VLMs on this benchmark, revealing significant performance gaps. To address the limitations of existing models, we further propose SUPERLENS, a multimodal smart glasses agent that enables retrieval-augmented answer generation by integrating automatic object detection, query decoupling, and multimodal web search. Our agent achieves state-of-the-art performance, surpassing GPT-4o by 2.19 percent, and highlights the need for task-specific solutions in smart glasses VQA scenarios.
QA-Dragon: Query-Aware Dynamic RAG System for Knowledge-Intensive Visual Question Answering
Aug 07, 2025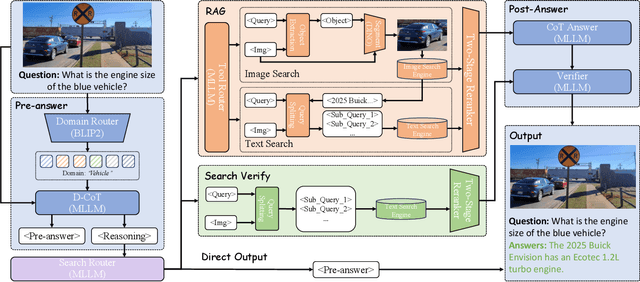

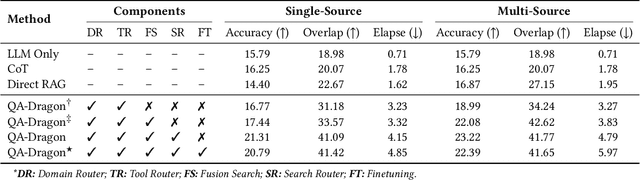
Retrieval-Augmented Generation (RAG) has been introduced to mitigate hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge into the generation process, and it has become a widely adopted approach for knowledge-intensive Visual Question Answering (VQA). However, existing RAG methods typically retrieve from either text or images in isolation, limiting their ability to address complex queries that require multi-hop reasoning or up-to-date factual knowledge. To address this limitation, we propose QA-Dragon, a Query-Aware Dynamic RAG System for Knowledge-Intensive VQA. Specifically, QA-Dragon introduces a domain router to identify the query's subject domain for domain-specific reasoning, along with a search router that dynamically selects optimal retrieval strategies. By orchestrating both text and image search agents in a hybrid setup, our system supports multimodal, multi-turn, and multi-hop reasoning, enabling it to tackle complex VQA tasks effectively. We evaluate our QA-Dragon on the Meta CRAG-MM Challenge at KDD Cup 2025, where it significantly enhances the reasoning performance of base models under challenging scenarios. Our framework achieves substantial improvements in both answer accuracy and knowledge overlap scores, outperforming baselines by 5.06% on the single-source task, 6.35% on the multi-source task, and 5.03% on the multi-turn task.
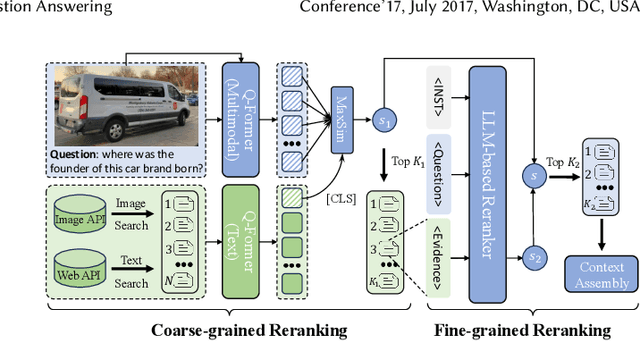
mKG-RAG: Multimodal Knowledge Graph-Enhanced RAG for Visual Question Answering
Aug 07, 2025Recently, Retrieval-Augmented Generation (RAG) has been proposed to expand internal knowledge of Multimodal Large Language Models (MLLMs) by incorporating external knowledge databases into the generation process, which is widely used for knowledge-based Visual Question Answering (VQA) tasks. Despite impressive advancements, vanilla RAG-based VQA methods that rely on unstructured documents and overlook the structural relationships among knowledge elements frequently introduce irrelevant or misleading content, reducing answer accuracy and reliability. To overcome these challenges, a promising solution is to integrate multimodal knowledge graphs (KGs) into RAG-based VQA frameworks to enhance the generation by introducing structured multimodal knowledge. Therefore, in this paper, we propose a novel multimodal knowledge-augmented generation framework (mKG-RAG) based on multimodal KGs for knowledge-intensive VQA tasks. Specifically, our approach leverages MLLM-powered keyword extraction and vision-text matching to distill semantically consistent and modality-aligned entities/relationships from multimodal documents, constructing high-quality multimodal KGs as structured knowledge representations. In addition, a dual-stage retrieval strategy equipped with a question-aware multimodal retriever is introduced to improve retrieval efficiency while refining precision. Comprehensive experiments demonstrate that our approach significantly outperforms existing methods, setting a new state-of-the-art for knowledge-based VQA.
Cross-Domain Transfer and Few-Shot Learning for Personal Identifiable Information Recognition
Jul 16, 2025Accurate recognition of personally identifiable information (PII) is central to automated text anonymization. This paper investigates the effectiveness of cross-domain model transfer, multi-domain data fusion, and sample-efficient learning for PII recognition. Using annotated corpora from healthcare (I2B2), legal (TAB), and biography (Wikipedia), we evaluate models across four dimensions: in-domain performance, cross-domain transferability, fusion, and few-shot learning. Results show legal-domain data transfers well to biographical texts, while medical domains resist incoming transfer. Fusion benefits are domain-specific, and high-quality recognition is achievable with only 10% of training data in low-specialization domains.
Do Protein Transformers Have Biological Intelligence?
Jun 07, 2025Deep neural networks, particularly Transformers, have been widely adopted for predicting the functional properties of proteins. In this work, we focus on exploring whether Protein Transformers can capture biological intelligence among protein sequences. To achieve our goal, we first introduce a protein function dataset, namely Protein-FN, providing over 9000 protein data with meaningful labels. Second, we devise a new Transformer architecture, namely Sequence Protein Transformers (SPT), for computationally efficient protein function predictions. Third, we develop a novel Explainable Artificial Intelligence (XAI) technique called Sequence Score, which can efficiently interpret the decision-making processes of protein models, thereby overcoming the difficulty of deciphering biological intelligence bided in Protein Transformers. Remarkably, even our smallest SPT-Tiny model, which contains only 5.4M parameters, demonstrates impressive predictive accuracy, achieving 94.3% on the Antibiotic Resistance (AR) dataset and 99.6% on the Protein-FN dataset, all accomplished by training from scratch. Besides, our Sequence Score technique helps reveal that our SPT models can discover several meaningful patterns underlying the sequence structures of protein data, with these patterns aligning closely with the domain knowledge in the biology community. We have officially released our Protein-FN dataset on Hugging Face Datasets https://huggingface.co/datasets/Protein-FN/Protein-FN. Our code is available at https://github.com/fudong03/BioIntelligence.
Variational Autoencoder Framework for Hyperspectral Retrievals (Hyper-VAE) of Phytoplankton Absorption and Chlorophyll a in Coastal Waters for NASA's EMIT and PACE Missions
Apr 18, 2025



Phytoplankton absorb and scatter light in unique ways, subtly altering the color of water, changes that are often minor for human eyes to detect but can be captured by sensitive ocean color instruments onboard satellites from space. Hyperspectral sensors, paired with advanced algorithms, are expected to significantly enhance the characterization of phytoplankton community composition, especially in coastal waters where ocean color remote sensing applications have historically encountered significant challenges. This study presents novel machine learning-based solutions for NASA's hyperspectral missions, including EMIT and PACE, tackling high-fidelity retrievals of phytoplankton absorption coefficient and chlorophyll a from their hyperspectral remote sensing reflectance. Given that a single Rrs spectrum may correspond to varied combinations of inherent optical properties and associated concentrations, the Variational Autoencoder (VAE) is used as a backbone in this study to handle such multi-distribution prediction problems. We first time tailor the VAE model with innovative designs to achieve hyperspectral retrievals of aphy and of Chl-a from hyperspectral Rrs in optically complex estuarine-coastal waters. Validation with extensive experimental observation demonstrates superior performance of the VAE models with high precision and low bias. The in-depth analysis of VAE's advanced model structures and learning designs highlights the improvement and advantages of VAE-based solutions over the mixture density network (MDN) approach, particularly on high-dimensional data, such as PACE. Our study provides strong evidence that current EMIT and PACE hyperspectral data as well as the upcoming Surface Biology Geology mission will open new pathways toward a better understanding of phytoplankton community dynamics in aquatic ecosystems when integrated with AI technologies.
Resource Heterogeneity-Aware and Utilization-Enhanced Scheduling for Deep Learning Clusters
Mar 13, 2025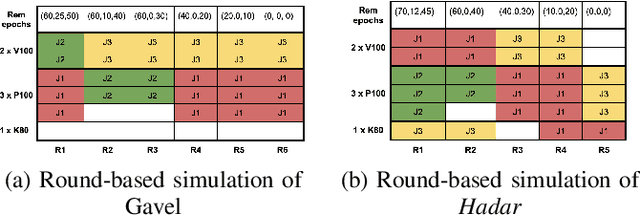
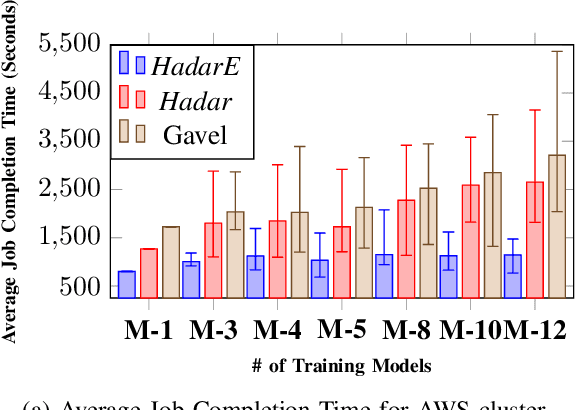
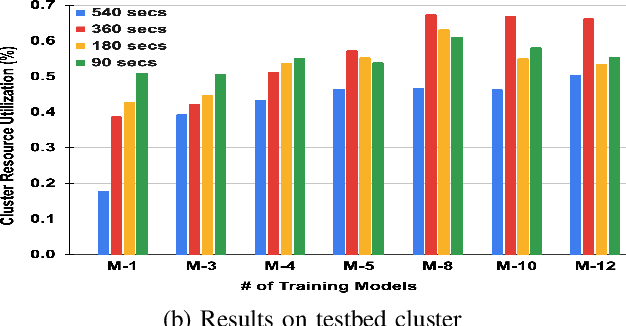
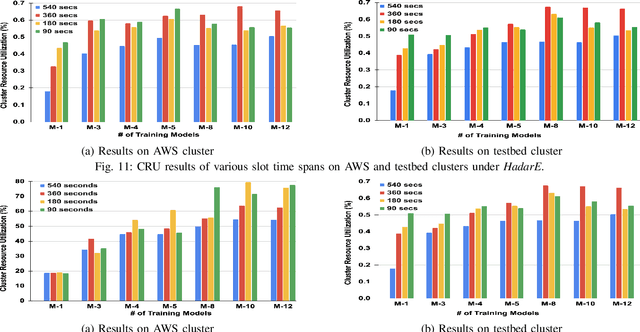
Scheduling deep learning (DL) models to train on powerful clusters with accelerators like GPUs and TPUs, presently falls short, either lacking fine-grained heterogeneity awareness or leaving resources substantially under-utilized. To fill this gap, we propose a novel design of a task-level heterogeneity-aware scheduler, {\em Hadar}, based on an optimization framework that can boost resource utilization. {\em Hadar} leverages the performance traits of DL jobs on a heterogeneous DL cluster, characterizes the task-level performance heterogeneity in the optimization problem, and makes scheduling decisions across both spatial and temporal dimensions. %with the objective to reduce the average job completion time of DL jobs. It involves the primal-dual framework employing a dual subroutine, to solve the optimization problem and guide the scheduling design. Our trace-driven simulation with representative DL model training workloads demonstrates that {\em Hadar} accelerates the total time duration by 1.20$\times$ when compared with its state-of-the-art heterogeneity-aware counterpart, Gavel. Further, our {\em Hadar} scheduler is enhanced to {\em HadarE} by forking each job into multiple copies to let a job train concurrently on heterogeneous GPUs resided on separate available nodes (i.e., machines or servers) for resource utilization enhancement. {\em HadarE} is evaluated extensively on physical DL clusters for comparison with {\em Hadar} and Gavel. With substantial enhancement in cluster resource utilization (by 1.45$\times$), {\em HadarE} exhibits considerable speed-ups in DL model training, reducing the total time duration by 50\% (or 80\%) on an Amazon's AWS (or our lab) cluster, while producing trained DL models with consistently better inference quality than those trained by \textit{Hadar}.
HiBench: Benchmarking LLMs Capability on Hierarchical Structure Reasoning
Mar 02, 2025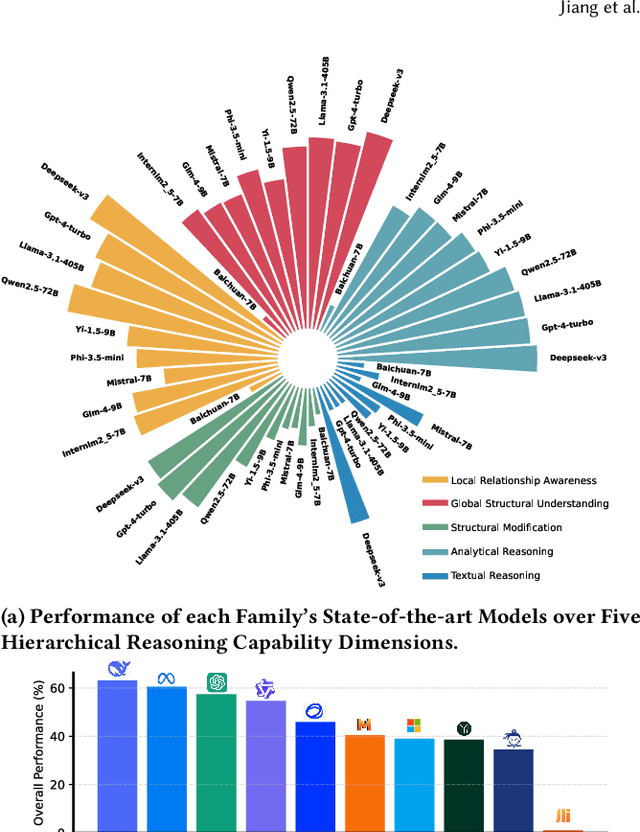
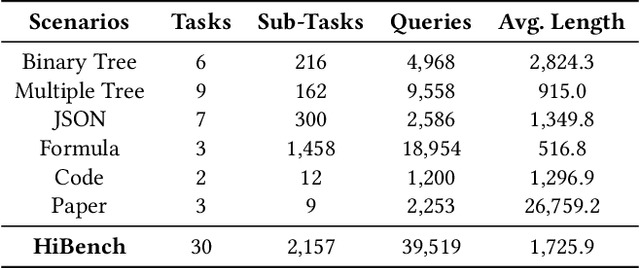
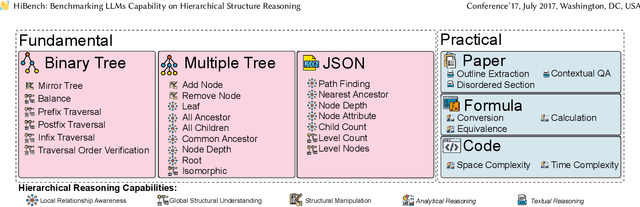
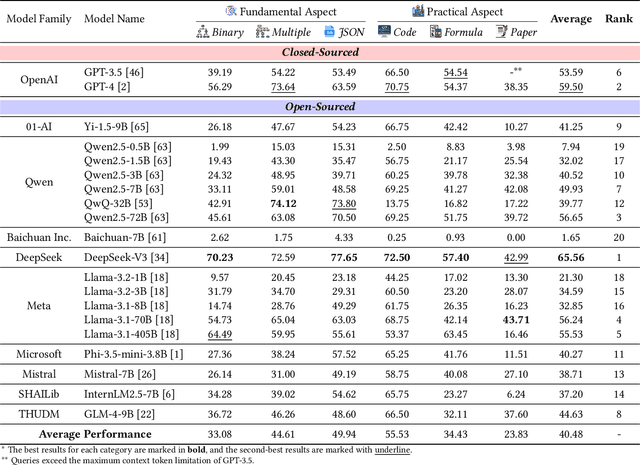
Structure reasoning is a fundamental capability of large language models (LLMs), enabling them to reason about structured commonsense and answer multi-hop questions. However, existing benchmarks for structure reasoning mainly focus on horizontal and coordinate structures (\emph{e.g.} graphs), overlooking the hierarchical relationships within them. Hierarchical structure reasoning is crucial for human cognition, particularly in memory organization and problem-solving. It also plays a key role in various real-world tasks, such as information extraction and decision-making. To address this gap, we propose HiBench, the first framework spanning from initial structure generation to final proficiency assessment, designed to benchmark the hierarchical reasoning capabilities of LLMs systematically. HiBench encompasses six representative scenarios, covering both fundamental and practical aspects, and consists of 30 tasks with varying hierarchical complexity, totaling 39,519 queries. To evaluate LLMs comprehensively, we develop five capability dimensions that depict different facets of hierarchical structure understanding. Through extensive evaluation of 20 LLMs from 10 model families, we reveal key insights into their capabilities and limitations: 1) existing LLMs show proficiency in basic hierarchical reasoning tasks; 2) they still struggle with more complex structures and implicit hierarchical representations, especially in structural modification and textual reasoning. Based on these findings, we create a small yet well-designed instruction dataset, which enhances LLMs' performance on HiBench by an average of 88.84\% (Llama-3.1-8B) and 31.38\% (Qwen2.5-7B) across all tasks. The HiBench dataset and toolkit are available here, https://github.com/jzzzzh/HiBench, to encourage evaluation.
GRID: Protecting Training Graph from Link Stealing Attacks on GNN Models
Jan 19, 2025



Graph neural networks (GNNs) have exhibited superior performance in various classification tasks on graph-structured data. However, they encounter the potential vulnerability from the link stealing attacks, which can infer the presence of a link between two nodes via measuring the similarity of its incident nodes' prediction vectors produced by a GNN model. Such attacks pose severe security and privacy threats to the training graph used in GNN models. In this work, we propose a novel solution, called Graph Link Disguise (GRID), to defend against link stealing attacks with the formal guarantee of GNN model utility for retaining prediction accuracy. The key idea of GRID is to add carefully crafted noises to the nodes' prediction vectors for disguising adjacent nodes as n-hop indirect neighboring nodes. We take into account the graph topology and select only a subset of nodes (called core nodes) covering all links for adding noises, which can avert the noises offset and have the further advantages of reducing both the distortion loss and the computation cost. Our crafted noises can ensure 1) the noisy prediction vectors of any two adjacent nodes have their similarity level like that of two non-adjacent nodes and 2) the model prediction is unchanged to ensure zero utility loss. Extensive experiments on five datasets are conducted to show the effectiveness of our proposed GRID solution against different representative link-stealing attacks under transductive settings and inductive settings respectively, as well as two influence-based attacks. Meanwhile, it achieves a much better privacy-utility trade-off than existing methods when extended to GNNs.