 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQA-Dragon: Query-Aware Dynamic RAG System for Knowledge-Intensive Visual Question Answering
Aug 07, 2025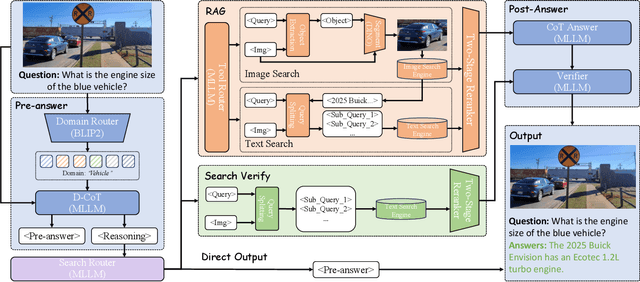

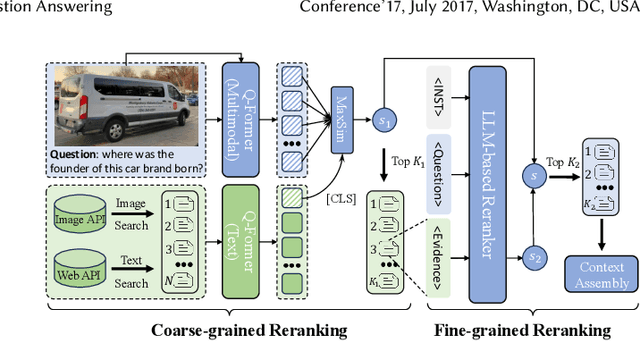
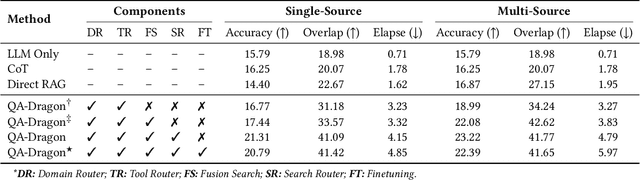
Retrieval-Augmented Generation (RAG) has been introduced to mitigate hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge into the generation process, and it has become a widely adopted approach for knowledge-intensive Visual Question Answering (VQA). However, existing RAG methods typically retrieve from either text or images in isolation, limiting their ability to address complex queries that require multi-hop reasoning or up-to-date factual knowledge. To address this limitation, we propose QA-Dragon, a Query-Aware Dynamic RAG System for Knowledge-Intensive VQA. Specifically, QA-Dragon introduces a domain router to identify the query's subject domain for domain-specific reasoning, along with a search router that dynamically selects optimal retrieval strategies. By orchestrating both text and image search agents in a hybrid setup, our system supports multimodal, multi-turn, and multi-hop reasoning, enabling it to tackle complex VQA tasks effectively. We evaluate our QA-Dragon on the Meta CRAG-MM Challenge at KDD Cup 2025, where it significantly enhances the reasoning performance of base models under challenging scenarios. Our framework achieves substantial improvements in both answer accuracy and knowledge overlap scores, outperforming baselines by 5.06% on the single-source task, 6.35% on the multi-source task, and 5.03% on the multi-turn task.
HiBench: Benchmarking LLMs Capability on Hierarchical Structure Reasoning
Mar 02, 2025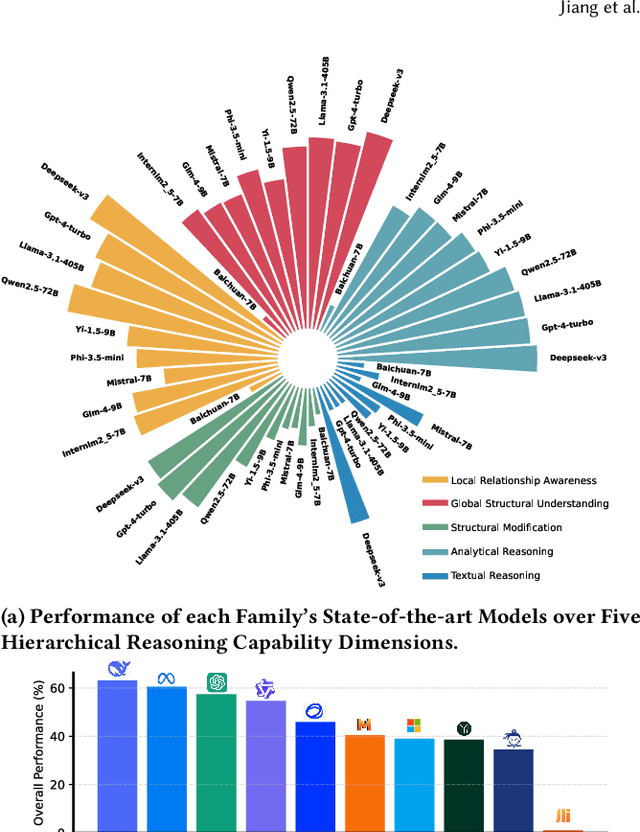
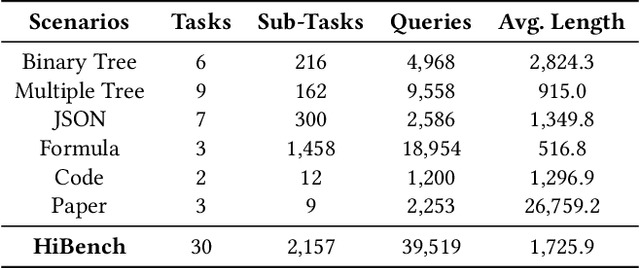
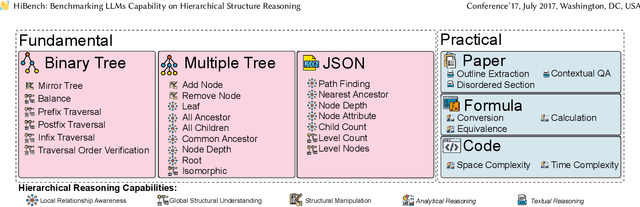
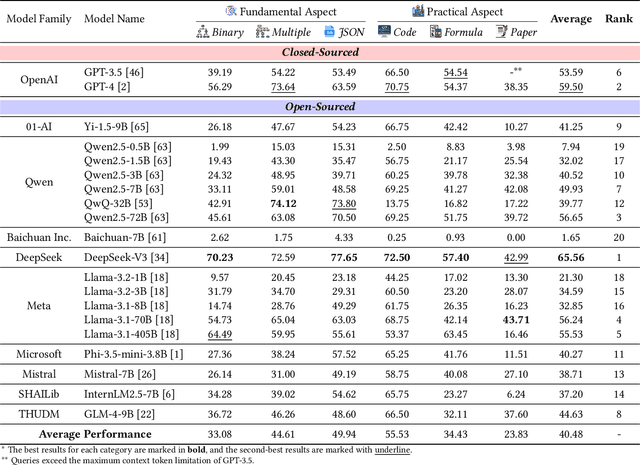
Structure reasoning is a fundamental capability of large language models (LLMs), enabling them to reason about structured commonsense and answer multi-hop questions. However, existing benchmarks for structure reasoning mainly focus on horizontal and coordinate structures (\emph{e.g.} graphs), overlooking the hierarchical relationships within them. Hierarchical structure reasoning is crucial for human cognition, particularly in memory organization and problem-solving. It also plays a key role in various real-world tasks, such as information extraction and decision-making. To address this gap, we propose HiBench, the first framework spanning from initial structure generation to final proficiency assessment, designed to benchmark the hierarchical reasoning capabilities of LLMs systematically. HiBench encompasses six representative scenarios, covering both fundamental and practical aspects, and consists of 30 tasks with varying hierarchical complexity, totaling 39,519 queries. To evaluate LLMs comprehensively, we develop five capability dimensions that depict different facets of hierarchical structure understanding. Through extensive evaluation of 20 LLMs from 10 model families, we reveal key insights into their capabilities and limitations: 1) existing LLMs show proficiency in basic hierarchical reasoning tasks; 2) they still struggle with more complex structures and implicit hierarchical representations, especially in structural modification and textual reasoning. Based on these findings, we create a small yet well-designed instruction dataset, which enhances LLMs' performance on HiBench by an average of 88.84\% (Llama-3.1-8B) and 31.38\% (Qwen2.5-7B) across all tasks. The HiBench dataset and toolkit are available here, https://github.com/jzzzzh/HiBench, to encourage evaluation.
Action Pick-up in Dynamic Action Space Reinforcement Learning
Apr 03, 2023



Most reinforcement learning algorithms are based on a key assumption that Markov decision processes (MDPs) are stationary. However, non-stationary MDPs with dynamic action space are omnipresent in real-world scenarios. Yet problems of dynamic action space reinforcement learning have been studied by many previous works, how to choose valuable actions from new and unseen actions to improve learning efficiency remains unaddressed. To tackle this problem, we propose an intelligent Action Pick-up (AP) algorithm to autonomously choose valuable actions that are most likely to boost performance from a set of new actions. In this paper, we first theoretically analyze and find that a prior optimal policy plays an important role in action pick-up by providing useful knowledge and experience. Then, we design two different AP methods: frequency-based global method and state clustering-based local method, based on the prior optimal policy. Finally, we evaluate the AP on two simulated but challenging environments where action spaces vary over time. Experimental results demonstrate that our proposed AP has advantages over baselines in learning efficiency.