 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiCANet: Efficient Time Series Forecasting with Convolutional Attention
Nov 07, 2024
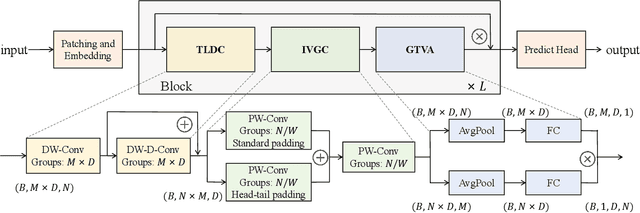

The exponential growth of multivariate time series data from sensor networks in domains like industrial monitoring and smart cities requires efficient and accurate forecasting models. Current deep learning methods often fail to adequately capture long-range dependencies and complex inter-variable relationships, especially under real-time processing constraints. These limitations arise as many models are optimized for either short-term forecasting with limited receptive fields or long-term accuracy at the cost of efficiency. Additionally, dynamic and intricate interactions between variables in real-world data further complicate modeling efforts. To address these limitations, we propose EffiCANet, an Efficient Convolutional Attention Network designed to enhance forecasting accuracy while maintaining computational efficiency. EffiCANet integrates three key components: (1) a Temporal Large-kernel Decomposed Convolution (TLDC) module that captures long-term temporal dependencies while reducing computational overhead; (2) an Inter-Variable Group Convolution (IVGC) module that captures complex and evolving relationships among variables; and (3) a Global Temporal-Variable Attention (GTVA) mechanism that prioritizes critical temporal and inter-variable features. Extensive evaluations across nine benchmark datasets show that EffiCANet achieves the maximum reduction of 10.02% in MAE over state-of-the-art models, while cutting computational costs by 26.2% relative to conventional large-kernel convolution methods, thanks to its efficient decomposition strategy.
Towards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
Action Pick-up in Dynamic Action Space Reinforcement Learning
Apr 03, 2023



Most reinforcement learning algorithms are based on a key assumption that Markov decision processes (MDPs) are stationary. However, non-stationary MDPs with dynamic action space are omnipresent in real-world scenarios. Yet problems of dynamic action space reinforcement learning have been studied by many previous works, how to choose valuable actions from new and unseen actions to improve learning efficiency remains unaddressed. To tackle this problem, we propose an intelligent Action Pick-up (AP) algorithm to autonomously choose valuable actions that are most likely to boost performance from a set of new actions. In this paper, we first theoretically analyze and find that a prior optimal policy plays an important role in action pick-up by providing useful knowledge and experience. Then, we design two different AP methods: frequency-based global method and state clustering-based local method, based on the prior optimal policy. Finally, we evaluate the AP on two simulated but challenging environments where action spaces vary over time. Experimental results demonstrate that our proposed AP has advantages over baselines in learning efficiency.