 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffiCANet: Efficient Time Series Forecasting with Convolutional Attention
Nov 07, 2024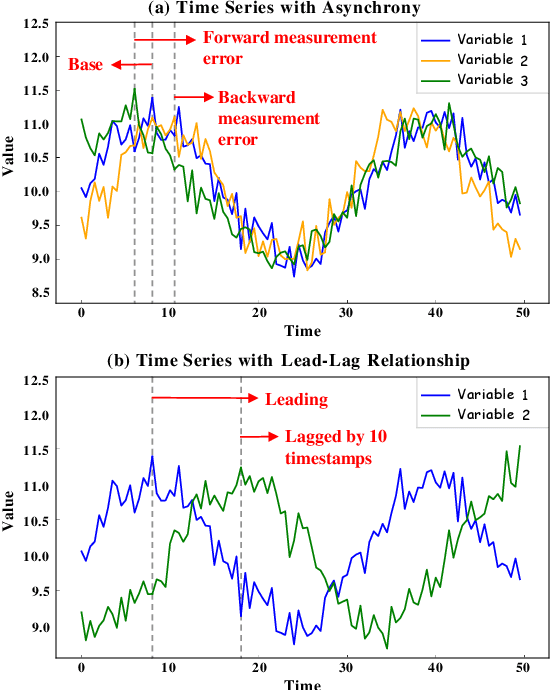
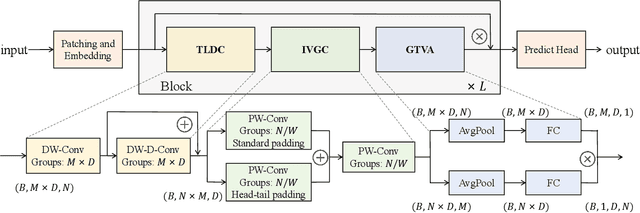

The exponential growth of multivariate time series data from sensor networks in domains like industrial monitoring and smart cities requires efficient and accurate forecasting models. Current deep learning methods often fail to adequately capture long-range dependencies and complex inter-variable relationships, especially under real-time processing constraints. These limitations arise as many models are optimized for either short-term forecasting with limited receptive fields or long-term accuracy at the cost of efficiency. Additionally, dynamic and intricate interactions between variables in real-world data further complicate modeling efforts. To address these limitations, we propose EffiCANet, an Efficient Convolutional Attention Network designed to enhance forecasting accuracy while maintaining computational efficiency. EffiCANet integrates three key components: (1) a Temporal Large-kernel Decomposed Convolution (TLDC) module that captures long-term temporal dependencies while reducing computational overhead; (2) an Inter-Variable Group Convolution (IVGC) module that captures complex and evolving relationships among variables; and (3) a Global Temporal-Variable Attention (GTVA) mechanism that prioritizes critical temporal and inter-variable features. Extensive evaluations across nine benchmark datasets show that EffiCANet achieves the maximum reduction of 10.02% in MAE over state-of-the-art models, while cutting computational costs by 26.2% relative to conventional large-kernel convolution methods, thanks to its efficient decomposition strategy.
Towards Universal Large-Scale Foundational Model for Natural Gas Demand Forecasting
Sep 24, 2024



In the context of global energy strategy, accurate natural gas demand forecasting is crucial for ensuring efficient resource allocation and operational planning. Traditional forecasting methods struggle to cope with the growing complexity and variability of gas consumption patterns across diverse industries and commercial sectors. To address these challenges, we propose the first foundation model specifically tailored for natural gas demand forecasting. Foundation models, known for their ability to generalize across tasks and datasets, offer a robust solution to the limitations of traditional methods, such as the need for separate models for different customer segments and their limited generalization capabilities. Our approach leverages contrastive learning to improve prediction accuracy in real-world scenarios, particularly by tackling issues such as noise in historical consumption data and the potential misclassification of similar data samples, which can lead to degradation in the quaility of the representation and thus the accuracy of downstream forecasting tasks. By integrating advanced noise filtering techniques within the contrastive learning framework, our model enhances the quality of learned representations, leading to more accurate predictions. Furthermore, the model undergoes industry-specific fine-tuning during pretraining, enabling it to better capture the unique characteristics of gas consumption across various sectors. We conducted extensive experiments using a large-scale dataset from ENN Group, which includes data from over 10,000 industrial, commercial, and welfare-related customers across multiple regions. Our model outperformed existing state-of-the-art methods, demonstrating a relative improvement in MSE by 3.68\% and in MASE by 6.15\% compared to the best available model.
Graffin: Stand for Tails in Imbalanced Node Classification
Sep 09, 2024



Graph representation learning (GRL) models have succeeded in many scenarios. Real-world graphs have imbalanced distribution, such as node labels and degrees, which leaves a critical challenge to GRL. Imbalanced inputs can lead to imbalanced outputs. However, most existing works ignore it and assume that the distribution of input graphs is balanced, which cannot align with real situations, resulting in worse model performance on tail data. The domination of head data makes tail data underrepresented when training graph neural networks (GNNs). Thus, we propose Graffin, a pluggable tail data augmentation module, to address the above issues. Inspired by recurrent neural networks (RNNs), Graffin flows head features into tail data through graph serialization techniques to alleviate the imbalance of tail representation. The local and global structures are fused to form the node representation under the combined effect of neighborhood and sequence information, which enriches the semantics of tail data. We validate the performance of Graffin on four real-world datasets in node classification tasks. Results show that Graffin can improve the adaptation to tail data without significantly degrading the overall model performance.
Multi-view Graph Structural Representation Learning via Graph Coarsening
Apr 18, 2024Graph Transformers (GTs) have made remarkable achievements in graph-level tasks. However, most existing works regard graph structures as a form of guidance or bias for enhancing node representations, which focuses on node-central perspectives and lacks explicit representations of edges and structures. One natural question is, can we treat graph structures node-like as a whole to learn high-level features? Through experimental analysis, we explore the feasibility of this assumption. Based on our findings, we propose a novel multi-view graph structural representation learning model via graph coarsening (MSLgo) on GT architecture for graph classification. Specifically, we build three unique views, original, coarsening, and conversion, to learn a thorough structural representation. We compress loops and cliques via hierarchical heuristic graph coarsening and restrict them with well-designed constraints, which builds the coarsening view to learn high-level interactions between structures. We also introduce line graphs for edge embeddings and switch to edge-central perspective to construct the conversion view. Experiments on six real-world datasets demonstrate the improvements of MSLgo over 14 baselines from various architectures.
TreeMAN: Tree-enhanced Multimodal Attention Network for ICD Coding
May 29, 2023ICD coding is designed to assign the disease codes to electronic health records (EHRs) upon discharge, which is crucial for billing and clinical statistics. In an attempt to improve the effectiveness and efficiency of manual coding, many methods have been proposed to automatically predict ICD codes from clinical notes. However, most previous works ignore the decisive information contained in structured medical data in EHRs, which is hard to be captured from the noisy clinical notes. In this paper, we propose a Tree-enhanced Multimodal Attention Network (TreeMAN) to fuse tabular features and textual features into multimodal representations by enhancing the text representations with tree-based features via the attention mechanism. Tree-based features are constructed according to decision trees learned from structured multimodal medical data, which capture the decisive information about ICD coding. We can apply the same multi-label classifier from previous text models to the multimodal representations to predict ICD codes. Experiments on two MIMIC datasets show that our method outperforms prior state-of-the-art ICD coding approaches. The code is available at https://github.com/liu-zichen/TreeMAN.